本文分享阿里技术专家关于 Kubernetes 的一些观点和看法,并给出学习 Kubernetes 的方法建议 ,最后分享 Kubernetes 集群上的问题排查经验。
一 什么是 Kubernetes?
我们来看一下什么是 Kubernetes。这部分内容我会从四个角度来跟大家分享一下我的看法。
1 未来什么样
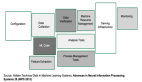
这是一张未来大部分公司后端 IT 基础设施的架构图。简单来说,以后所有公司的 IT 基础设施都会部署在云上。用户会基于 Kubernetes 把底层云资源分割成具体的集群单元,给不同的业务使用。而随着业务微服务化的深入,服务网格这样的服务治理逻辑会变得跟下边两层一样,成为基础设施的范畴。
目前,阿里基本上所有的业务都跑在云上。而其中大约有一半的业务已经迁移到了自己定制 Kubernetes 集群上。另外据我了解,阿里计划今年完成 100% 的基于 Kubernetes 集群的业务部署。
而服务网格这块,在阿里的一些部门,像蚂蚁金服,其实已经有线上业务在用了。大家可以通过蚂蚁一些同学的分享来了解他们的实践过程。
虽然这张图里的观点可能有点绝对,但是目前这个趋势是非常明显的。所以未来几年, Kubernetes 肯定会变成像 Linux 一样的,作为集群的操作系统无处不在。
2 Kubernetes 与操作系统
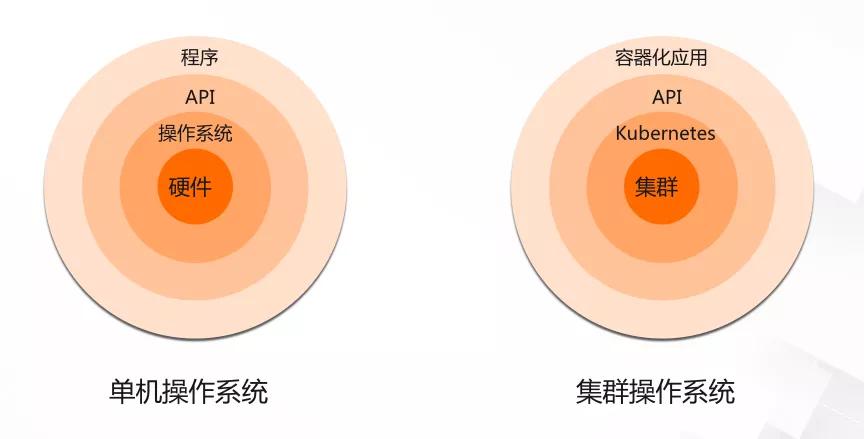
这是一张传统的操作系统和 Kubernetes 的比较图。大家都知道,作为一个传统的操作系统,像 Linux 或者 Windows,它们扮演的角色,就是底层硬件的 一个抽象层。它们向下管理计算机的硬件,像内存或 CPU,然后把底层硬件抽象成一些易用的接口,用这些接口,向上对应用层提供支持。
而 Kubernetes 呢,我们也可以把它理解为一个操作系统。这个操作系统说白了也是一个抽象层,它向下管理的硬件,不是内存或者 CPU 这种硬件,而是多台计算机组成的集群,这些计算机本身就是普通的单机系统,有自己的操作系统和硬件。Kubernetes 把这些计算机当成一个资源池来 统一管理,向上对应用提供支撑。
这里的应用比较特别,就是这些应用都是容器化的应用。如果对容器不太了解的同学,可以简单把这些应用,理解为一个应用安装文件。安装文件打包了所有的依赖库,比如 libc 这些。这些应用不会依赖底层操作系统的库文件来运行。
3 Kubernetes 与 Google 运维解密

上图中,左边是一个 Kubernetes 集群,右边是一本非常有名的书,就是 Google 运维解密这本书。相信很多人都看过这本书,而且有很多公司目前也在实践这本书里的方法。包括故障管理,运维排班等。
Kubernetes 和这本书的关系,我们可以把他们比作剑法和气功的关系。不知道这里有多少人看过笑傲江湖。笑傲江湖里的华山派分两个派别,气宗和剑宗。气宗注重气功修炼,而剑宗更强调剑法的精妙。实际上气宗和剑宗的分家,是因为华山派两个弟子偷学一本葵花宝典,两个人各记了一部分,最终因为观点分歧分成了两派。
Kubernetes 实际上源自 Google 的集群自动化管理和调度系统 Borg,也就是这本书里讲的运维方法所针对的对象。Borg 系统和书里讲的各种运维方法可以看做是一件事情的两个方面。如果一个公司只去学习他们的运维方法,比如开了 SRE 的职位,而不懂这套方法所管理的系统的话,那其实就是学习葵花宝典,但是只学了一部分。
Borg 因为是 Google 内部的系统,所以我们一般人是看不到的,而 Kubernetes 基本上继承了 Borg 在集群自动化管理方面非常核心的一些理念。所以如果大家看了这本书,觉得很厉害,或者在实践这本书里的方法,那大家一定要深入理解下 Kubernetes。
4 技术演进史
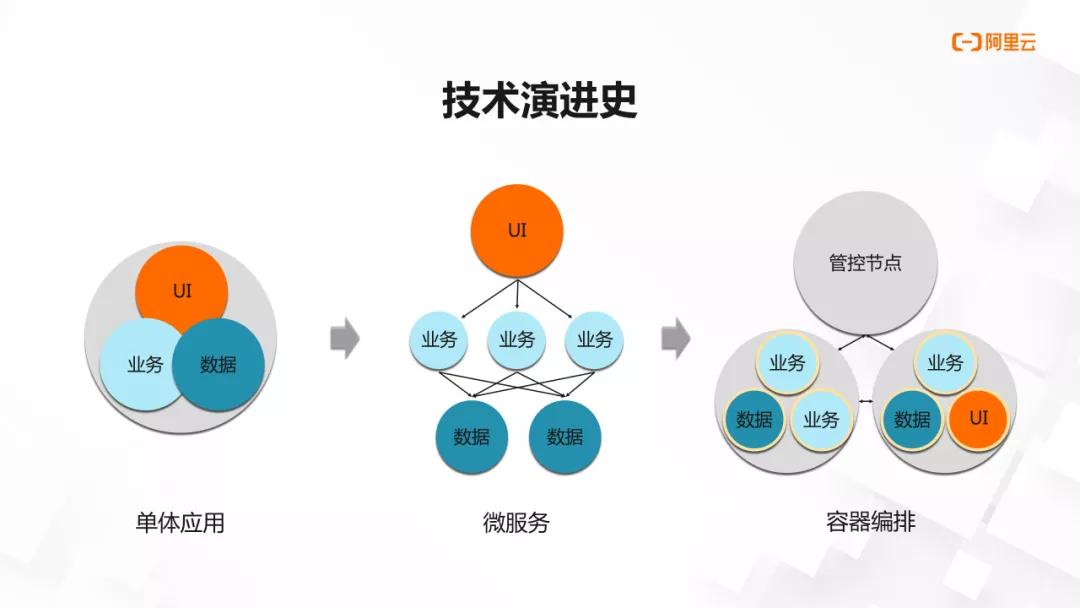
早期的时候,我们做一个网站后端,可能只需要把所有的模块放在一个可执行文件里,就像上图一样,我们有 UI、数据和业务三个模块,这三个模块被编译成一个可执行文件,跑在一台服务器上。
但是随着业务量的大幅增长,我们没有办法,通过升级服务器配置的方式来扩容。这时候我们就必须去做微服务化了。
微服务化会把单体应用拆分成低耦合的小应用。这些应用各自负责一块业务,然后每个应用的实例独占一台服务器,它们之间通过网络互相调用。
这里最关键的是,我们可以通过增加实例个数,来对小应用做横向扩容。这就解决了单台服务器无法扩容的问题。
微服务之后会出现一个问题,就是一个实例占用一台服务器的问题。这种部署方式,资源的浪费其实是比较严重的。这时我们自然会想到,把这些实例混部到底层服务器上。
但是混部会引入两个新问题,一个是依赖库兼容性问题。这些应用依赖的库文件版本可能完全不一样,安装到一个操作系统里,必然会出问题。另一个问题就是应用调度和集群资源管理的问题。
比如一个新的应用被创建出来,我们需要考虑这个应用被调度到哪台服务器,调度上去之后资源够不够用这些问题。
这里的依赖库兼容性问题,是靠容器化来解决的,也就是每个应用自带依赖库,只跟其他应用共享内核。而调度和资源管理就是 Kubernetes 所解决的问题。
顺便提一句,我们可能会因为,集群里混部的应用太多,这些应用关系错综复杂,而没有办法去排查一些像请求响应慢这样的问题。所以类似服务网格这类服务治理的技术,肯定会成为下一个趋势。
二 怎么学习 Kubernetes?
1 Kubernetes 学习难点
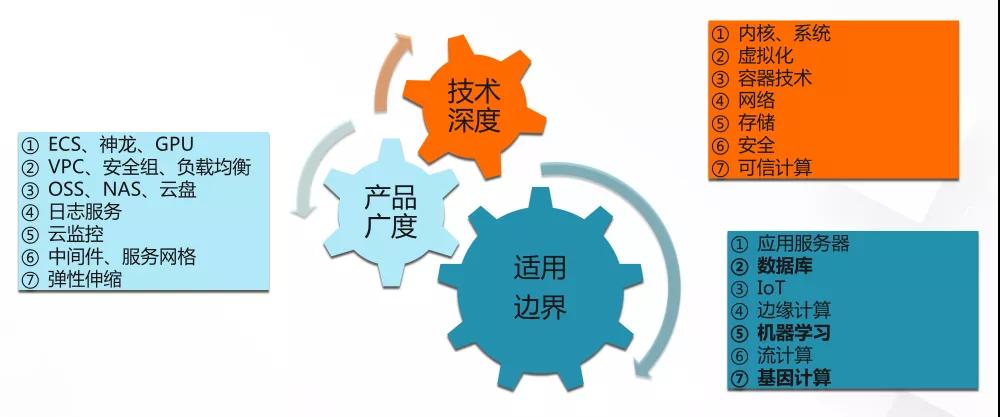
总体来说,Kubernetes 之所以门槛比较高,比较难学习,一个是因为它的技术栈非常深,包括了内核,虚拟化,容器,软件定义网络 SDN,存储,安全,甚至可信计算等,绝对可以称得上全栈技术。
同时 Kubernetes 在云环境的实现,肯定会牵扯到非常多的云产品,比如在阿里云上,我们的 Kubernetes 集群用到了 ECS 云服务器,VPC 虚拟网络,负载均衡,安全组,日志服务,云监控,中间件产品像 ahas 和 arms,服务网格,弹性伸缩等等大量云产品。
最后,因为 Kubernetes 是一个通用的计算平台,所以它会被用到各种业务场景中去,比如数据库。据我所知,像我们的 PolarDB Box 一体机就是计划基于 Kubernetes 搭建。另外还有边缘计算,机器学习,流计算等等。
2 了解、动手、思考

基于我个人的经验,学习 Kubernetes,我们需要从了解、动手、以及思考三个方面去把握。
了解其实很重要,特别是了解技术的演进史,以及技术的全景图。
我们需要知道各种技术的演进历史,比如容器技术是怎么从 chroot 这个命令发展而来的,以及技术演进背后要解决的问题是什么,只有知道技术的演进史和发展的动力,我们才能对未来技术方向有自己的判断。
同时我们需要了解技术全景,对 Kubernetes 来说,我们需要了解整个云原生技术栈,包括容器,CICD,微服务、服务网格这些,知道 Kubernetes 在整个技术栈里所处的位置。
除了这些基本的背景知识以外,学习 Kubernetes 技术,动手实践是非常关键的。
从我和大量工程师一起解决问题的经验来说,很多人其实是不会去深入研究技术细节的。我们经常开玩笑说工程师有两种,一种是 search engineer,就是搜索工程师,一种是 research engineer,就是研究工程师。很多工程师遇到问题,google 一把,如果搜不到答案,就直接开工单了。这样是很难深入理解一个技术的。
最后就是怎么去思考,怎么去总结了。我个人的经验是,我们需要在理解技术细节之后,不断的问自己,细节的背后,有没有什么更本质的东西。也就是我们要把复杂的细节看简单,然后找出普通的模式出来。
下边我用两个例子来具体解释一下上边的方法。
3 用冰箱来理解集群控制器
第一个例子是关于集群控制器的。我们在学习 Kubernetes 的时候会听到几个概念,像声明式 API,Operator,面向终态设计等。这些概念本质上 都是在讲一件事情,就是控制器模式。
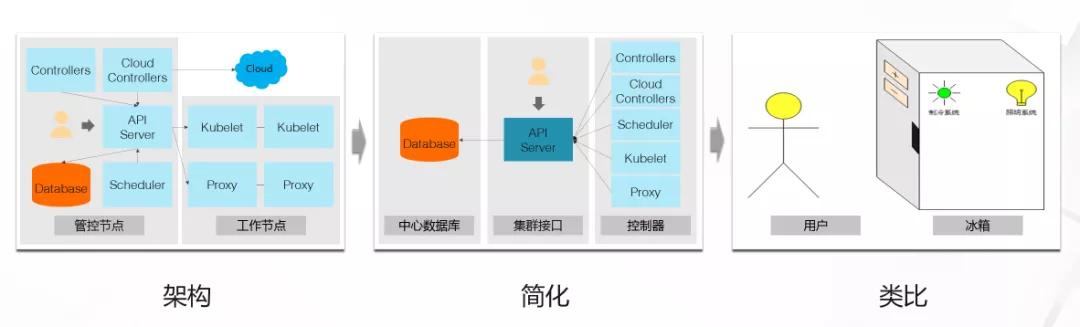
我们怎么来理解 Kubernetes 的控制器呢?上面这张图是一个经典的 Kubernetes 架构图,这张图里有集群管控节点和工作节点,管控节点上有中心数据库,API Server,调度器及一些控制器。
中心数据库是集群的核心存储系统,API Server 是集群的管控入口,调度器负责把应用调度到资源充沛的节点上。而控制器是我们这里要说的重点。控制器的作用,我们用一句话概括,就是“让梦想照进现实”。从这个意义上来讲,我自己也经常扮演控制器的角色,我女儿如果说,爸爸我要吃冰激凌,那我女儿就是集群的用户,我就是负责把她这个愿望实现的人,就是控制器。
除了管控节点以外,Kubernetes 集群有很多工作节点,这些节点都部署了 Kubelet 和 Proxy 这两个代理。Kubelet 负责管理工作节点,包括应用在节点上启动和停止之类的工作。Proxy 负责把服务的定义落实成具体的 iptables 或者 ipvs 规则。这里服务的概念,其实简单来说,就是利用 iptables 或者 ipvs 来实现负载均衡。
如果我们从控制器的角度来看第一张图的话,我们就会得到第二张图。也就是说,集群实际上就包括一个数据库,一个集群入口,以及很多个控制器。这些组件,包括调度器,Kubelet 以及 Proxy,实际上都是不断的去观察集群里各种资源的定义,然后把这些定义落实成具体的配置,比如容器启动或 iptables 配置。
从控制器的角度观察 Kubernetes 的时候,我们其实得到了 Kubernetes 最根本的一个原理了。就是控制器模式。
其实控制器模式在我们生活中无处不在的,这里我拿冰箱做个例子。我们在控制冰箱的时候,并不会直接去控制冰箱里的制冷系统或者照明系统。我们打开冰箱的时候,里边的灯会打开,我们在设置了想要的温度之后,就算我们不在家,制冷系统也会一直保持这个温度。这背后就是因为有控制器模式在起作用。
4 为什么删除不掉命名空间
第二个例子,我们来看一个真实问题的排查过程。这个问题是一个命名空间不能被删除的问题。问题稍微有点复杂,我们一步一步来看。
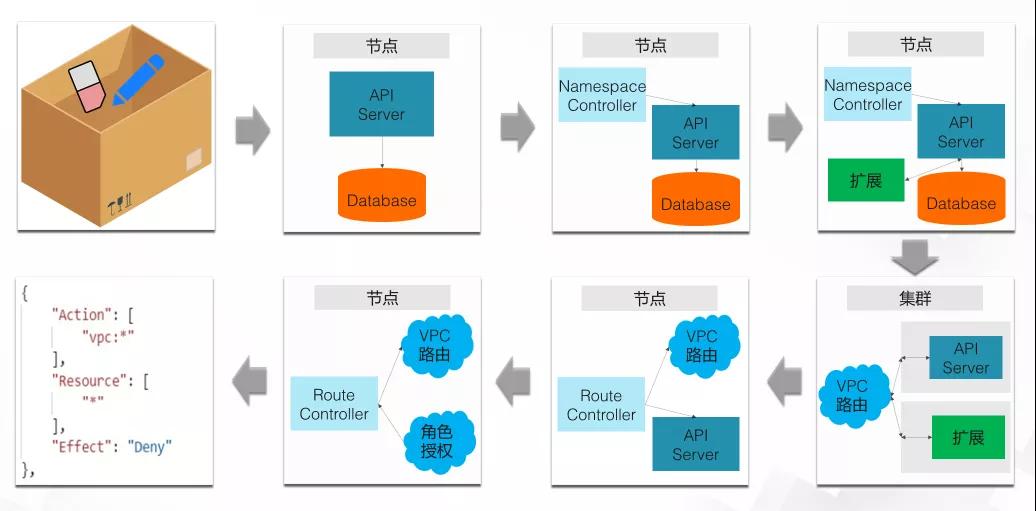
命名空间是 Kubernetes 集群的 一个收纳盒机制,就像这里的第一张图片一样。这个盒子就是命名空间,它里边收纳了橡皮和铅笔。
命名空间可以被创建或者删除。我们经常会遇到不能删除命名空间的问题。遇到这个问题,我们如果完全不知道怎么排查。第一步我们可能会想到,研究一下 API Server 是怎么处理这个删除操作的,因为 API Server 就是集群的 管理入口。
API Server 本身是一个应用,我们可以通过提升这个应用的日志级别,来深入理解它的操作流程。在这个问题里,我们会发现,API Server 收到删除命令,但是就没有其他信息了。
这里我们需要稍微理解下命名空间的删除过程,用户在删除命名空间的时候,其实命名空间并不会被直接删除掉,而会被改成“删除中”的状态。这个时候命名空间控制器就会看到这个状态。
为了理解命名空间控制器的行为,我们同样可以把控制器的日志级别提高来查看详细的日志。这个时候呢,我们会发现,控制器正在尝试去获取所有的 API 分组。
到这里我们需要去理解两个事情。一个是为什么删除命名空间,控制器会去获取 API 分组。第二个是 API 分组到底是什么。
我们先看第二个问题,API 分组到底是什么。简单来说,API 分组就是集群 API 的分类机制,比如网络相关的 API 就在 networking 这个组里。而通过网络 API 分组创建出来的资源就属于这个组。
那为什么命名空间控制器会去获取 API 分组呢?是因为在删除命名空间的时候,控制器需要删除命名空间里的所有资源。这个操作不像我们删除文件夹一样,会把里边的文件都一起删掉。
命名空间收纳了资源,实际上是这些资源用类似索引的机制,指向了这个命名空间。集群只有遍历所有的 API 分组,找出指向这个命名空间的所有资源,才能逐个把它们删除掉。
而遍历 API 组这个操作呢,会使得集群的 API Server 和它的扩展进行通信。这是因为 API Server 的扩展,也可以实现一部分 API 分组。所以想知道被删除的命名空间里是不是有包括这个扩展定义的资源,API Server 就必须和扩展通信。
到这一步之后,问题实际上变成 API Server 和他的扩展之间通信的问题。也就是删除资源的问题就变成了网络问题。
阿里云的 Kubernetes 集群,是在 VPC 网络,也就是虚拟局域网上创建的。默认情况下, VPC 的只认识 VPC 网段的地址,而集群里边的容器,一般会使用和 VPC 不同的网段。比如 VPC 使用 172 网段,那容器可能就使用 192 网段。
我们通过在 VPC 的路由表里,增加容器网段的路由项,可以让容器使用 VPC 网络进行通信。
在右下角这张图,我们有两个集群节点,他们的地址是 172 网段,那我们给路由表里增加 192 网段的路由项,就可以让 VPC 把发给容器的数据转发到正确的节点上,再由节点发给具体的容器。
而这里的路由项,是在节点加入集群的时候,由路由控制器来添加的。路由控制器在发现有新节点加入集群之后,会立刻做出反应,给路由表里增加一条路由项。
添加路由项这个操作,其实是对 VPC 的一次操作。这个操作是需要使用一定的授权的,这是因为这个操作跟线下一台机器访问云上资源是差不多的,肯定需要授权。
这里路由控制器使用的授权,是以 RAM 角色的方式绑定到路由控制器所在的集群节点上的。而这个 RAM 角色,正常会有一系列的授权规则。
最后,我们通过检查,发现用户修改了授权规则,所以导致了这个问题。