每当您开始一个新的数据项目或有一个很好的数据处理想法时,可能都需要初步的概念证明来启动。 您当然不想要,并且可能甚至没有时间花时间来建立全新的数据环境,而无需了解数据本身。 在下一篇文章中,您将学习Docker如何在不浪费时间一遍又一遍的情况下帮助您设置可复制的数据环境。

什么是Docker?为什么要尝试一下?
Docker是在指定环境(称为容器)中创建,部署和运行所需应用程序的最简单,最灵活的方法之一。 当然,你问自己什么是容器?
非技术性的解释:就像上图所示,在我们的情况下,您的本地机器是一个已经在生产东西的岛。 为了改善这一点,您需要其他工具,这些工具(就像Docker徽标一样)装在小容器中。 一旦设置好并运行它们,它们就可以使用了。
技术说明:容器是打包代码及其所有依赖项的软件的标准单元,因此应用程序可以从一个计算环境快速运行到另一个计算环境。 Docker容器映像是一个轻量级的,独立的,可执行的软件软件包,其中包含运行应用程序所需的一切:代码,运行时,系统工具,系统库和设置。 其他重要术语:
- 图片:只是容器的快照。
- Dockerfile:这是一个Yaml文件,用于构建您的映像。 在本课程的最后,您将拥有一个yaml文件模板,并将其用于您自己的容器规范。
- DockerHub:在这里您可以推拉Docker映像并将其用于您自己的需求。 基本上,GitHub仅用于Docker。
为什么要使用Docker?

让我向您概述我喜欢使用Docker的主要原因:
- 对于您作为数据科学家或数据分析师而言,泊坞窗意味着您可以专注于探索,转换和建模数据,而无需首先考虑您的数据环境所运行的系统。 通过使用准备在Docker容器中运行的数千种应用程序之一,您不必担心分别安装和连接它们。 Docker允许您在需要时在几秒钟内部署所选的工作环境。
- 假设您不是项目中唯一的工作人员,但是您的团队成员也需要掌握代码。 现在,一个选择是,每个队友都可以在具有不同体系结构,不同库和不同版本应用程序的环境中运行代码。 docker选项是每个成员都可以访问相同的容器映像,并使用docker启动该映像并准备就绪。 Docker为团队中的每个人提供了可重复的数据环境,因此您可以立即开始进行协作。
Docker当然还有其他几个好处,特别是如果您使用的是Enterprise版本。 绝对值得探索,不仅会使您作为数据科学家受益。
安装和运行Docker
您可以立即安装Docker桌面,这是您入门所需的内容:在此处访问Docker Hub,为Mac或Windows选择Docker版本并进行安装。 在您的本地机器上启动Docker之后,您就可以在顶部导航栏上看到这只可爱的小鲸鱼-做得很好。
通过单击Docker徽标,您可以查看Docker是否正在运行。 另一种选择是打开命令行并输入" docker info",以便您看到正在运行的内容。 以下是一些基本的Docker命令:
- docker login#登录Docker注册表
- docker run#创建一个新容器并启动
- docker start #启动一个现有的容器
- docker stop
#停止一个正在运行的容器 - docker ps [-a] #显示所有容器
- docker rm
#按名称或ID删除容器 - docker rmi $(docker images -q)#删除所有镜像
您可以从一个简单的示例开始,尝试使用Jupyter笔记本。 您要做的就是在Docker Hub中查找映像,打开终端并运行docker。 在下面的示例中,您可以找到在localhost:8888上运行的Jupyter —简单!
docker run -p 8888:8888 jupyter/scipy-notebook:2c80cf3537ca
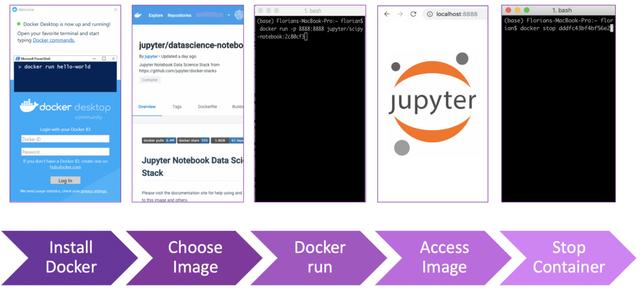
虽然我们现在可以在容器中试用我们的应用程序,但它并不是高级数据科学家正在寻找的完整数据环境。 您可能想要使用更高级的工具,例如Nifi进行数据摄取和处理,Kafka进行数据流传输,以及使用SQL或NonSQL数据库在两者之间存储一些表。 我们还能使用Docker吗? 答案:是的,当然可以-Docker在这里为您管理所有工作。
Docker Compose:将它们组合在一起

要设置所需的数据环境,您可能希望在我们的本地计算机上运行多个容器。 这就是为什么我们使用Docker Compose。 Compose是用于定义和运行多容器Docker应用程序的工具。 虽然单独连接每个容器可能很耗时,但docker compose允许多个容器的集合以非常直接的方式通过其自己的网络进行交互。 使用compose时,您首先使用yaml文件配置应用程序的服务,然后使用单个命令(docker compose up)来创建并启动先前定义的所有服务。*
在下面的内容中,您可以找到入门的主要步骤:
- 使用Dockerfile定义您的应用环境,以便轻松复制
- 在docker-compose.yml中指定构成数据环境的所有服务
- 在保存yaml文件的文件夹中打开终端,然后运行docker-compose up
docker-compose.yml可能类似于以下内容。 并且尽管您可以肯定使用以下内容作为模板,但绝对应该为自己配置一次:
- version: '3'
- services:
- zookeeper:
- hostname: zookeeper
- container_name: zookeeper_dataenv
- image: 'bitnami/zookeeper:latest'
- environment:
- - ALLOW_ANONYMOUS_LOGIN=yes
- nifi:
- image: mkobit/nifi
- container_name: nifi_dataenv
- ports:
- - 8080:8080
- - 8081:8081
- environment:
- - NIFI_WEB_HTTP_PORT=8080
- - NIFI_ZK_CONNECT_STRING=zookeeper:2181
- minimal-jupyter-notebook:
- image: jupyter/minimal-notebook:latest
- ports:
- - 8888:8888
- mongodb:
- image: mongo:latest
- container_name: mongodb_dataenv
- environment:
- - MONGO_DATA_DIR=/data/db
- - MONGO_LOG_DIR=/dev/null
- ports:
- - 27017:27017
- grafana:
- image: bitnami/grafana:latest
- container_name: grafana_dataenv
- ports:
- - 3000:3000
- db:
- image: 'postgres:9.6.3-alpine'
- container_name: psql_dataenv
- ports:
- - 5432:5432
- environment:
- POSTGRES_DB: psql_data_environment
- POSTGRES_USER: psql_user
- POSTGRES_PASSWORD: psql
- PGDATA: /opt/psql_data
- restart: "no"
而已! 您刚刚了解了如何在几秒钟内随时随地部署自己的数据环境的基础知识,这意味着浪费更少的时间进行设置,而将更多的时间用于生产。
请注意,还有许多其他容器软件选项。 我只是喜欢与Docker合作,并想与您分享我的经验