如果将人脑的神经信号也视为一种语言,那么将机器翻译架构应用于解读神经信号的可行性似乎并不令人惊讶。在《Nature Neuroscience》的一篇论文中,来自加州大学旧金山分校的研究者实践了这一想法。他们用一个编码器-解码器框架将大脑神经信号转换为文字,在 250 个词的封闭句子集中将错误率降到了 3%。

论文链接:https://www.nature.com/articles/s41593-020-0608-8
在过去的十年里,脑机接口(BMI)已经从动物实验转变为人类实验,其中具有代表性的结果是使得四肢瘫痪者恢复一定的运动能力,在空间维度中的两个自由度上实现连续运动。尽管这种类型的控制也可以与虚拟键盘结合使用来生成文本,但即使在理想的光标控制下(目前尚无法实现),码字率仍受限于单指打字。另一种选择是直接解码口语,但到目前为止,这种 BMI 仅限于解码孤立的音素或单音节,或者在中等数量词汇(约 100 单词)构成的连续语音中,正确解码不到 40% 的单词。
为了获得更高的准确度,来自加州大学旧金山分校的研究者利用了「从神经活动解码语音」与「机器翻译」两个任务之间的概念相似性。这两种任务的目标都是在同一基础分析单位的两种不同表示之间建立映射。更确切地说,二者都是将一个任意长度的序列转化为另一个任意长度的序列(任意是指输入和输出序列的长度不同,并且彼此之间没有决定性的联系)。
在这项研究中,研究者试图一次解码一个句子,就像当下大多数机器翻译算法一样,因此这两种任务实际上都映射到相同类型的输出,即一个单词序列对应于一个句子。另一方面,这两种任务的输入是存在很大区别的:分别是神经信号和文本。但是,当前机器翻译架构可以通过人工神经网络直接从数据中学习特征,这表明机器翻译的端到端学习算法几乎可以直接运用于语音解码。
为了验证这一假设,在语音生成过程中,研究者利用从脑电图(ECoG)获得的神经信号以及相应口语的转录,训练了一种「序列到序列」的架构。此外,这项任务和机器翻译之间最重要的区别在于,后者的数据集可以包含超过 100 万个句子,但构成该研究基础的脑电图研究中的单个参与者通常只提供几千个句子。
为了在相对不足的训练数据中利用端到端学习的优势,研究者使用了仅包含 30-50 个不同句子的限制性「语言」,并且在某些情况下,采用了其他参与者的数据和其他语音任务的迁移学习。
这项研究的参与者从以下两个数据集之一中大声朗读句子:一组图片描述(30 句,约 125 个不同单词),通常以一个会话的形式描述;或 MOCHATIMIT14(460 句,约 1800 个不同单词),以 50 句分组的会话进行(最后一组 60 句),研究者称之为 MOCHA-1、MOCHA-2 等等。在时间允许的情况下重复分组会话。对于测试,研究者只考虑了至少重复三次的句子集(即提供一组用于测试,至少提供两组用于训练),这在实践中将 MOCHA-TIMIT 集限制为 MOCHA-1(50 句,约 250 个不同单词)。
方法
这里首先简要描述解码流程,如下图所示:
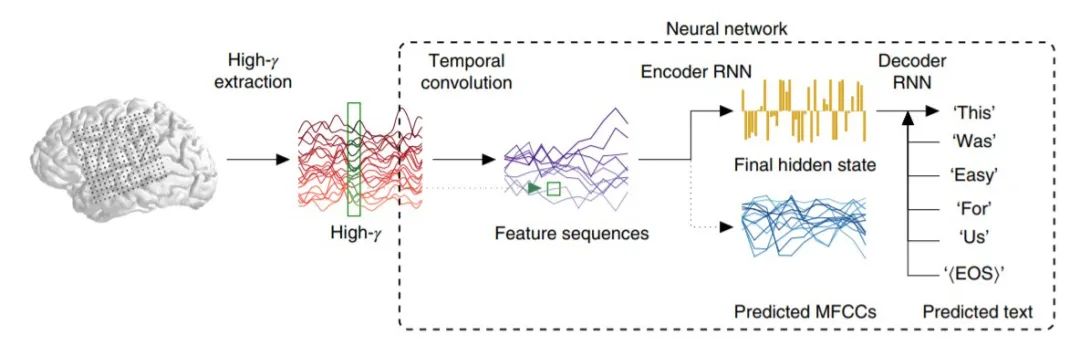
研究者要求参与者大声朗读句子,同时利用高密度 ECoG 网格(ECoG grid)记录他们 peri-Sylvian 皮质的神经活动。
在每个电极上,ECoG 信号的高频分量(70-150Hz,即「high-γ」)的包络线(即该范围内分析信号的振幅)在大约 200Hz 处提取。然后将所得的序列(每个对应于一个句子)作为输入数据传递到「编码器-解码器」式的人工神经网络。
网络分三个阶段处理序列:
- 时间卷积:类似的特征很可能在 ECoG 数据序列的不同点上重现,全连接的前馈网络无法利用这样的特点。
- 编码器 RNN:下采样序列被 RNN 按序处理。在每个时间步中,编码器 RNN 的输入由每个下采样序列的当前样本以及它自己的先前状态组成。然后最终隐藏状态(Final hidden state,上图中的黄色条)提供整个序列的单个高维编码,与序列长度无关。为了引导编码器在训练过程中找到有用的解,研究者还要求编码器在每个时间步中预测语音音频信号的表示,即梅尔频率倒谱系数的序列 (MFCCs)。
- 解码器 RNN:最后,高维状态必须转换回另一个序列,即单词序列。因此,我们初始化第二个 RNN,然后训练为在每个时间步骤解码出一个单词或序列结束 token(在该点终止解码)。在输出序列的每个步骤中,除了自身先前的隐藏状态外,解码器还以参与者实际说出句子中的前一个单词作为输入(在模型训练阶段),或者它自己在前一步预测的单词作为输入 (在测试阶段)。与以前针对语音音素进行语音解码的方法相比,该方法将单词作为目标。
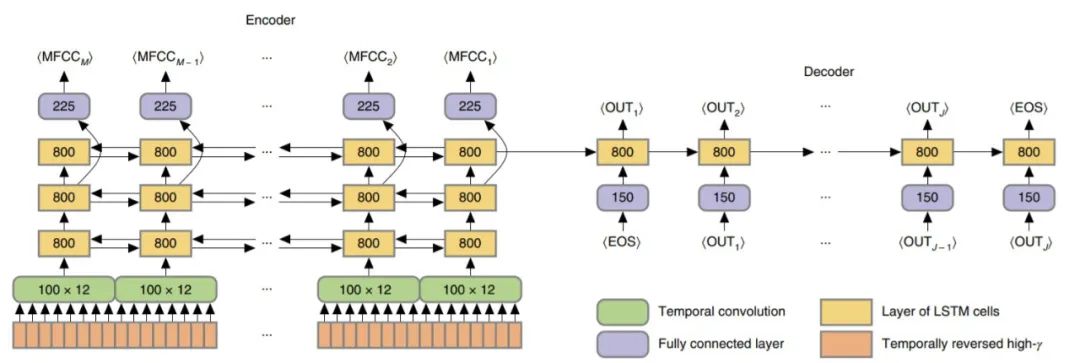
网络架构
整个网络同时进行训练,使编码器生成值接近目标 MFCC,并使解码器为每个目标词分配高概率。请注意,MFCC 目标提供了一个「辅助损失」,这是一种多任务学习的形式,其目的仅仅是引导网络找到解决词序解码问题的足够好的解。在测试期间,MFCC 预测被丢弃不管,解码完全基于解码器 RNN 的输出。所有的训练都是通过反向传播的随机梯度下降进行的,并将 dropout 应用于所有的层。
实验结果
在整个实验过程中,研究者用平均单词错误率 (WER,基于所有测试句子计算) 来量化性能,因此,完美解码的 WER 为 0%。作为参考,在语音转录中,5% 的 WER 为专业水平,20-25% 为可接受的性能。这也是语音识别技术被广泛采用的标准,尽管它的参考词汇量要大得多。
我们首先考虑一个示例参与者说 MOCHA-1 的 50 个句子(大约 250 个不同单词)时的编码器-解码器框架的性能(见下图)。下图中参与者的平均 WER 约为 3%。以前最先进方法的语音解码 WER 是 60%,并使用较小的词汇量(100 词)进行实验。
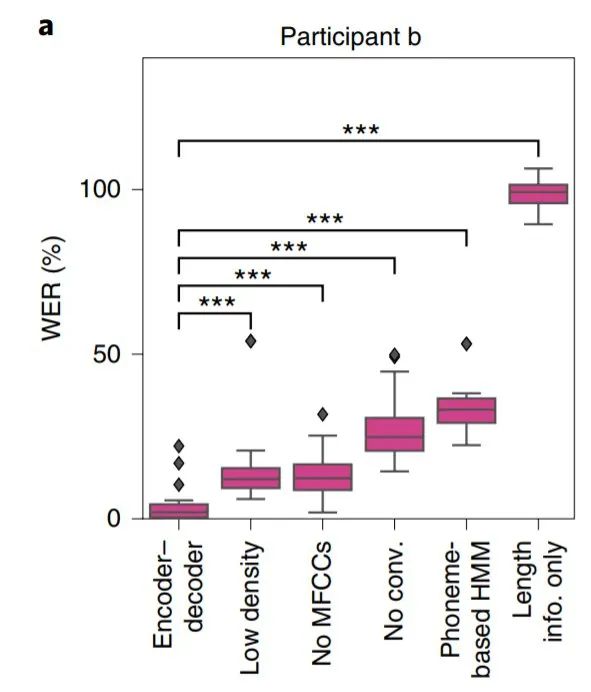
解码句子的WERs。
编码器-解码器网络的卓越性能源自什么?为了量化其各种因素的贡献,研究者系统地删除或削弱了它们,并从头开始训练网络。上图中的第二个方框显示了对数据进行空间下采样以模拟较低密度 ECoG 网格的性能。具体来说,只留下了网格两个维度上四分之一的通道(也就是说,实际上是 64 个通道,而不是 256 个通道)。WER 大约是原来的四倍,仍然在可用范围内,这表明了除高密度网格外其它因素对于该算法的重要性。
第三个方框内显示当 MFCC 在训练过程中未被锁定时的性能,其 WER 与使用低密度网格数据训练的模型的 WER 接近,但仍然明显优于先前的语音解码方法。
接下来,研究者考虑一个输入层是全连接而不是卷积的网络(第四个框),WER 达到了原来的 8 倍。
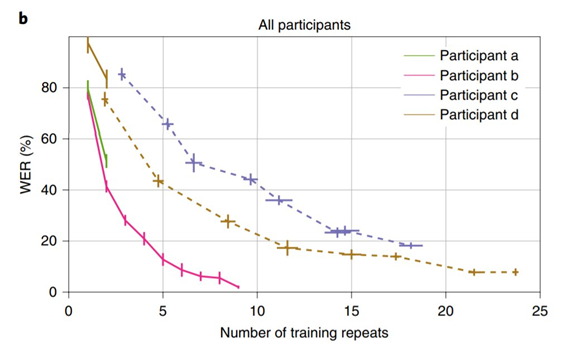
然后考虑实现高性能需要多少数据。下图显示了四个参与者的 WER,作为神经网络训练重复次数的函数。没有任何参与者的训练数据总量超过 40 分钟,当至少有 15 次重复训练时,WER 可能低于 25% 以下。
在下图中,有两名参与者,他们在 MOCHA 句子上的训练次数很少 (参与者 a/绿色实线,参与者 d/棕色实线),因此解码性能较差。