鱼和熊掌我都要!BAIR公布神经支持决策树新研究,兼顾准确率与可解释性。
随着深度学习在金融、医疗等领域的不断落地,模型的可解释性成了一个非常大的痛点,因为这些领域需要的是预测准确而且可以解释其行为的模型。然而,深度神经网络缺乏可解释性也是出了名的,这就带来了一种矛盾。可解释性人工智能(XAI)试图平衡模型准确率与可解释性之间的矛盾,但 XAI 在说明决策原因时并没有直接解释模型本身。
决策树是一种用于分类的经典机器学习方法,它易于理解且可解释性强,能够在中等规模数据上以低难度获得较好的模型。之前很火的微软小冰读心术极可能就是使用了决策树。小冰会先让我们想象一个知名人物(需要有点名气才行),然后向我们询问 15 个以内的问题,我们只需回答是、否或不知道,小冰就可以很快猜到我们想的那个人是谁。
周志华老师曾在「西瓜书」中展示过决策树的示意图:
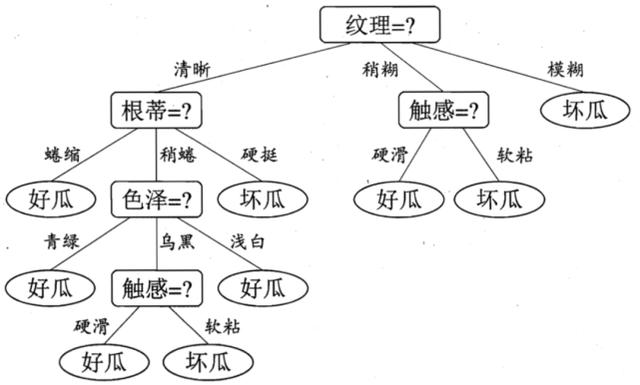
决策树示意图。
尽管决策树有诸多优点,但历史经验告诉我们,如果遇上 ImageNet 这一级别的数据,其性能还是远远比不上神经网络。
「准确率」和「可解释性」,「鱼」与「熊掌」要如何兼得?把二者结合会怎样?最近,来自加州大学伯克利分校和波士顿大学的研究者就实践了这种想法。
他们提出了一种神经支持决策树「Neural-backed decision trees」,在 ImageNet 上取得了 75.30% 的 top-1 分类准确率,在保留决策树可解释性的同时取得了当前神经网络才能达到的准确率,比其他基于决策树的图像分类方法高出了大约 14%。

BAIR 博客地址:https://bair.berkeley.edu/blog/2020/04/23/decisions/
论文地址:https://arxiv.org/abs/2004.00221
开源项目地址:https://github.com/alvinwan/neural-backed-decision-trees
这种新提出的方法可解释性有多强?我们来看两张图。
OpenAI Microscope 中深层神经网络可视化后是这样的:
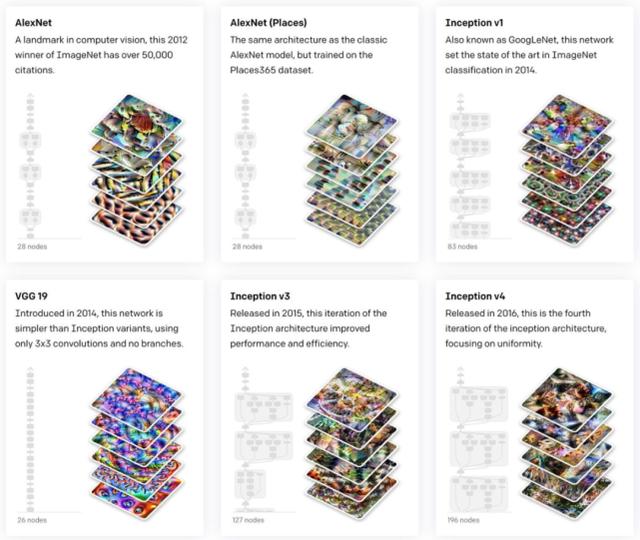
而论文所提方法在 CIFAR100 上分类的可视化结果是这样的:
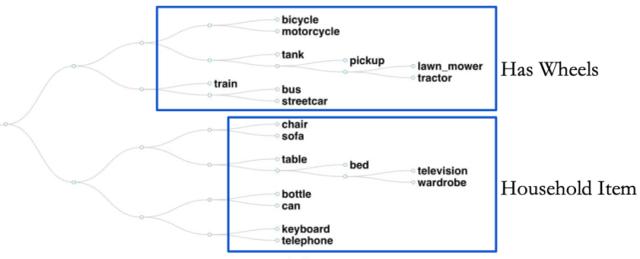
哪种方法在图像分类上的可解释性强已经很明显了吧。
决策树的优势与缺陷
在深度学习风靡之前,决策树是准确性和可解释性的标杆。下面,我们首先阐述决策树的可解释性。
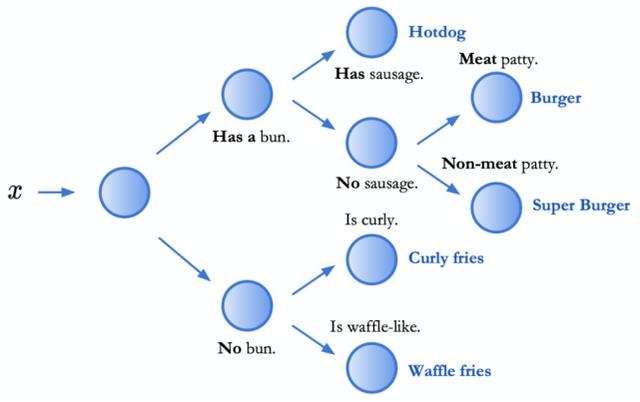
如上图所示,这个决策树不只是给出输入数据 x 的预测结果(是「超级汉堡」还是「华夫薯条」),还会输出一系列导致最终预测的中间决策。我们可以对这些中间决策进行验证或质疑。
然而,在图像分类数据集上,决策树的准确率要落后神经网络 40%。神经网络和决策树的组合体也表现不佳,甚至在 CIFAR10 数据集上都无法和神经网络相提并论。
这种准确率缺陷使其可解释性的优点变得「一文不值」:我们首先需要一个准确率高的模型,但这个模型也要具备可解释性。
走近神经支持决策树
现在,这种两难处境终于有了进展。加州大学伯克利分校和波士顿大学的研究者通过建立既可解释又准确的模型来解决这个问题。
研究的关键点是将神经网络和决策树结合起来,保持高层次的可解释性,同时用神经网络进行低层次的决策。如下图所示,研究者称这种模型为「神经支持决策树(NBDT)」,并表示这种模型在保留决策树的可解释性的同时,也能够媲美神经网络的准确性。
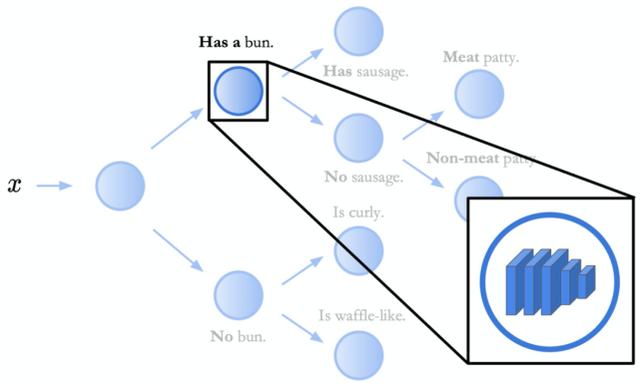
在这张图中,每一个节点都包含一个神经网络,上图放大标记出了一个这样的节点与其包含的神经网络。在这个 NBDT 中,预测是通过决策树进行的,保留高层次的可解释性。但决策树上的每个节点都有一个用来做低层次决策的神经网络,比如上图的神经网络做出的低层决策是「有香肠」或者「没有香肠」。
NBDT 具备和决策树一样的可解释性。并且 NBDT 能够输出预测结果的中间决策,这一点优于当前的神经网络。
如下图所示,在一个预测「狗」的网络中,神经网络可能只输出「狗」,但 NBDT 可以输出「狗」和其他中间结果(动物、脊索动物、肉食动物等)。
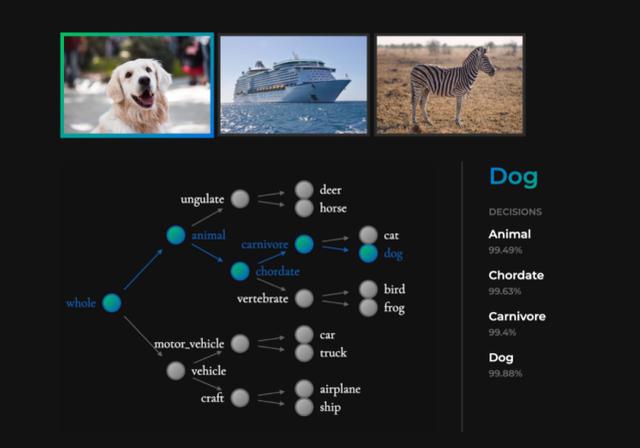
此外,NBDT 的预测层次轨迹也是可视化的,可以说明哪些可能性被否定了。
与此同时,NBDT 也实现了可以媲美神经网络的准确率。在 CIFAR10、CIFAR100 和 TinyImageNet200 等数据集上,NBDT 的准确率接近神经网络(差距
神经支持决策树是如何解释的
对于个体预测的辩证理由
最有参考价值的辩证理由是面向该模型从未见过的对象。例如,考虑一个 NBDT(如下图所示),同时在 Zebra 上进行推演。虽然此模型从未见过斑马,但下图所显示的中间决策是正确的-斑马既是动物又是蹄类动物。对于从未见过的物体而言,个体预测的合理性至关重要。
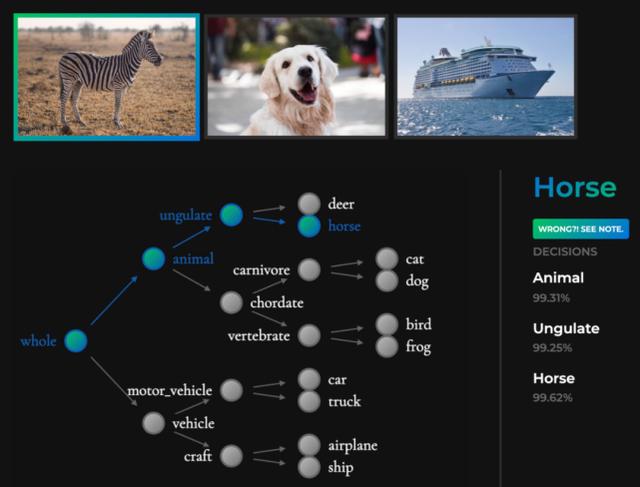
对于模型行为的辩证理由
此外,研究者发现使用 NBDT,可解释性随着准确性的提高而提高。这与文章开头中介绍的准确性与可解释性的对立背道而驰,即:NBDT 不仅具有准确性和可解释性,还可以使准确性和可解释性成为同一目标。
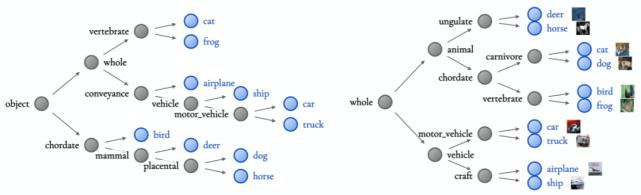
ResNet10 层次结构(左)不如 WideResNet 层次结构(右)。
例如,ResNet10 的准确度比 CIFAR10 上的 WideResNet28x10 低 4%。相应地,较低精度的 ResNet ^ 6 层次结构(左)将青蛙,猫和飞机分组在一起且意义较小,因为很难找到三个类共有的视觉特征。而相比之下,准确性更高的 WideResNet 层次结构(右)更有意义,将动物与车完全分离开了。因此可以说,准确性越高,NBDT 就越容易解释。
了解决策规则
使用低维表格数据时,决策树中的决策规则很容易解释,例如,如果盘子中有面包,然后分配给合适的孩子(如下所示)。然而,决策规则对于像高维图像的输入而言则不是那么直接。模型的决策规则不仅基于对象类型,而且还基于上下文,形状和颜色等等。
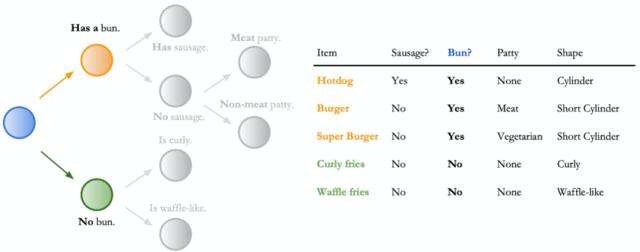
此案例演示了如何使用低维表格数据轻松解释决策的规则。
为了定量解释决策规则,研究者使用了 WordNet3 的现有名词层次;通过这种层次结构可以找到类别之间最具体的共享含义。例如,给定类别 Cat 和 Dog,WordNet 将反馈哺乳动物。在下图中,研究者定量验证了这些 WordNet 假设。
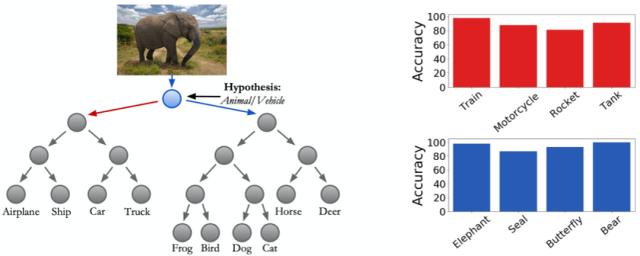
左侧从属树(红色箭头)的 WordNet 假设是 Vehicle。右边的 WordNet 假设(蓝色箭头)是 Animal。
值得注意的是,在具有 10 个类(如 CIFAR10)的小型数据集中,研究者可以找到所有节点的 WordNet 假设。但是,在具有 1000 个类别的大型数据集(即 ImageNet)中,则只能找到节点子集中的 WordNet 假设。
How it Works
Neural-Backed 决策树的训练与推断过程可分解为如下四个步骤:
为决策树构建称为诱导层级「Induced Hierarchy」的层级;
该层级产生了一个称为树监督损失「Tree Supervision Loss」的独特损失函数;
通过将样本传递给神经网络主干开始推断。在最后一层全连接层之前,主干网络均为神经网络;
以序列决策法则方式运行最后一层全连接层结束推断,研究者将其称为嵌入决策法则「Embedded Decision Rules」。
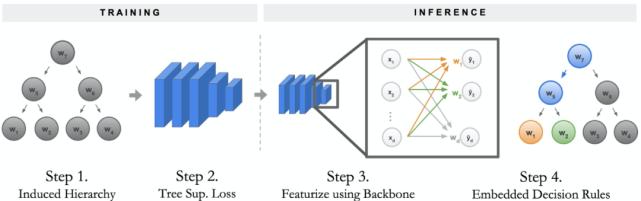
Neural-Backed 决策树训练与推断示意图。
运行嵌入决策法则
这里首先讨论推断问题。如前所述,NBDT 使用神经网络主干提取每个样本的特征。为便于理解接下来的操作,研究者首先构建一个与全连接层等价的退化决策树,如下图所示:
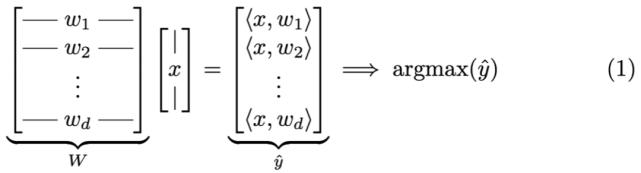
以上产生了一个矩阵-向量乘法,之后变为一个向量的内积,这里将其表示为$\hat{y}$。以上输出最大值的索引即为对类别的预测。
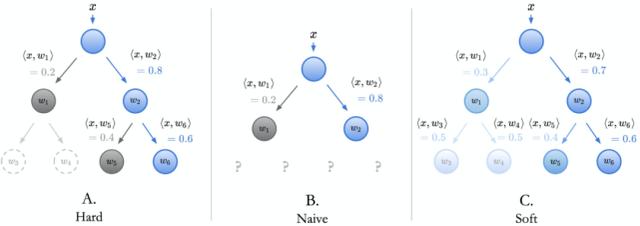
简单决策树(naive decision tree):研究者构建了一个每一类仅包含一个根节点与一个叶节点的基本决策树,如上图中「B—Naive」所示。每个叶节点均直接与根节点相连,并且具有一个表征向量(来自 W 的行向量)。
使用从样本提取的特征 x 进行推断意味着,计算 x 与每个子节点表征向量的内积。类似于全连接层,最大内积的索引即为所预测的类别。
全连接层与简单决策树之间的直接等价关系,启发研究者提出一种特别的推断方法——使用内积的决策树。
构建诱导层级
该层级决定了 NBDT 需要决策的类别集合。由于构建该层级时使用了预训练神经网络的权重,研究者将其称为诱导层级。
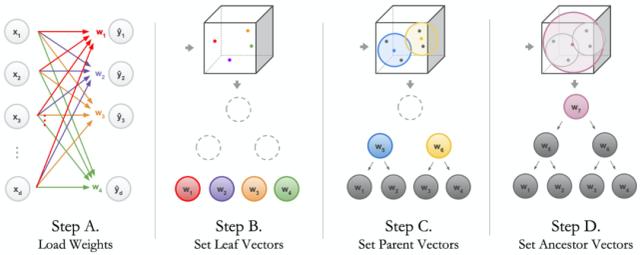
具体地,研究者将全连接层中权重矩阵 W 的每个行向量,看做 d 维空间中的一点,如上图「Step B」所示。接下来,在这些点上进行层级聚类。连续聚类之后便产生了这一层级。
使用树监督损失进行训练
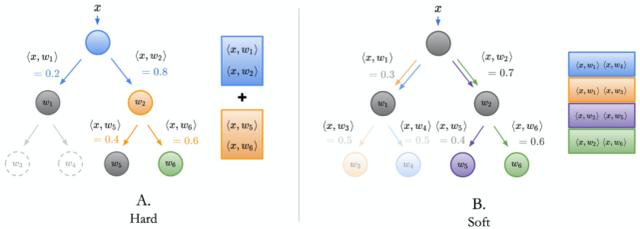
考虑上图中的「A-Hard」情形。假设绿色节点对应于 Horse 类。这只是一个类,同时它也是动物(橙色)。对结果而言,也可以知道到达根节点(蓝色)的样本应位于右侧的动物处。到达节点动物「Animal」的样本也应再次向右转到「Horse」。所训练的每个节点用于预测正确的子节点。研究者将强制实施这种损失的树称为树监督损失(Tree Supervision Loss)。换句话说,这实际上是每个节点的交叉熵损失。
使用指南
我们可以直接使用 Python 包管理工具来安装 nbdt:
pip install nbdt
- 1.
安装好 nbdt 后即可在任意一张图片上进行推断,nbdt 支持网页链接或本地图片。
nbdt https://images.pexels.com/photos/126407/pexels-photo-126407.jpeg?auto=compress&cs=tinysrgb&dpr=2&w=32
# OR run on a local image
nbdt /imaginary/path/to/local/image.png
- 1.
- 2.
- 3.
- 4.
- 5.
不想安装也没关系,研究者为我们提供了网页版演示以及 Colab 示例,地址如下:
Demo:http://nbdt.alvinwan.com/demo/
Colab:http://nbdt.alvinwan.com/notebook/
下面的代码展示了如何使用研究者提供的预训练模型进行推断:
from nbdt.model import SoftNBDT
from nbdt.models import ResNet18, wrn28_10_cifar10, wrn28_10_cifar100, wrn28_10 # use wrn28_10 for TinyImagenet200
model = wrn28_10_cifar10()
model = SoftNBDT(
pretrained=True,
dataset='CIFAR10',
arch='wrn28_10_cifar10',
model=model)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
另外,研究者还提供了如何用少于 6 行代码将 nbdt 与我们自己的神经网络相结合,详细内容请见其 GitHub 开源项目。