前言
Hive这个框架在Hadoop的生态体系结构中占有及其重要的地位,在实际的业务当中用的也非常多,可以说Hadoop之所以这么流行在很大程度上是因为Hive的存在。那么Hive究竟是什么,为什么在Hadoop家族中占有这么重要的地位,本篇文章将围绕Hive的体系结构(架构)、Hive的操作、Hive与Hbase的区别等对Hive进行全方面的阐述。
在此之前,先给大家介绍一个业务场景,让大家感受一下为什么Hive如此的受欢迎:
业务描述:统计业务表consumer.txt中北京的客户有多少位?下面是相应的业务数据:
- id city name sex
- 0001 beijing zhangli man
- 0002 guizhou lifang woman
- 0003 tianjin wangwei man
- 0004 chengde wanghe woman
- 0005 beijing lidong man
- 0006 lanzhou wuting woman
- 0007 beijing guona woman
- 0008 chengde houkuo man
首先我先用大家所熟悉的MapReduce程序来实现这个业务分析,完整代码如下:
- package IT;
- import java.io.IOException;
- import java.net.URI;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.FSDataInputStream;
- import org.apache.hadoop.fs.FileSystem;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.IOUtils;
- import org.apache.hadoop.io.LongWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.Mapper;
- import org.apache.hadoop.mapreduce.Reducer;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
- import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
- import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
- public class Consumer
- {
- public static String path1 = "hdfs://192.168.80.80:9000/consumer.txt";
- public static String path2 = "hdfs://192.168.80.80:9000/dir";
- public static void main(String[] args) throws Exception
- {
- FileSystem fileSystem = FileSystem.get(new URI(path1) , new Configuration());
- if(fileSystem.exists(new Path(path2)))
- {
- fileSystem.delete(new Path(path2), true);
- }
- Job job = new Job(new Configuration(),"Consumer");
- FileInputFormat.setInputPaths(job, new Path(path1));
- job.setInputFormatClass(TextInputFormat.class);
- job.setMapperClass(MyMapper.class);
- job.setMapOutputKeyClass(Text.class);
- job.setMapOutputValueClass(LongWritable.class);
- job.setNumReduceTasks(1);
- job.setPartitionerClass(HashPartitioner.class);
- job.setReducerClass(MyReducer.class);
- job.setOutputKeyClass(Text.class);
- job.setOutputValueClass(LongWritable.class);
- job.setOutputFormatClass(TextOutputFormat.class);
- FileOutputFormat.setOutputPath(job, new Path(path2));
- job.waitForCompletion(true);
- //查看执行结果
- FSDataInputStream fr = fileSystem.open(new Path("hdfs://hadoop80:9000/dir/part-r-00000"));
- IOUtils.copyBytes(fr, System.out, 1024, true);
- }
- public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable>
- {
- public static long sum = 0L;
- protected void map(LongWritable k1, Text v1,Context context) throws IOException, InterruptedException
- {
- String[] splited = v1.toString().split("\t");
- if(splited[1].equals("beijing"))
- {
- sum++;
- }
- }
- protected void cleanup(Context context)throws IOException, InterruptedException
- {
- String str = "beijing";
- context.write(new Text(str),new LongWritable(sum));
- }
- }
- public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable>
- {
- protected void reduce(Text k2, Iterable<LongWritable> v2s,Context context)throws IOException, InterruptedException
- {
- for (LongWritable v2 : v2s)
- {
- context.write(k2, v2);
- }
- }
- }
- }
MapReduce程序代码运行结果如下:
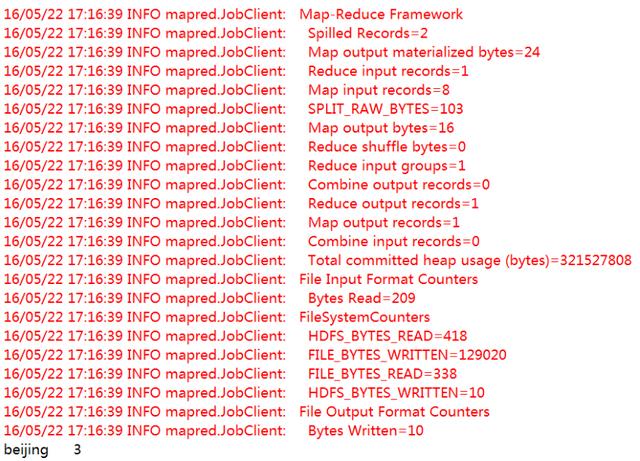
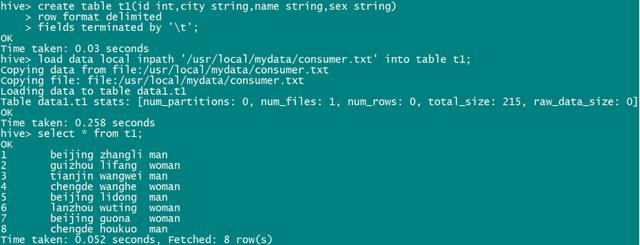
从运行结果可以看出:在consumer.txt业务表中,北京的客户共有三位。下面我们将用Hive来实现相同的功能,即统计业务表consumer.txt中北京的客户有多少位?
Hive操作如下:

Hive运行结果如下:
- OK
- beijing 3
- Time taken: 19.768 seconds, Fetched: 1 row(s)
到这里,是不是感觉Hive这个运行框架很神奇-----对于相同的业务逻辑只需要写几行Sql命令就可以获取我们所需要的结果,这也恰恰是Hive为什么这么流行的原因,Hive的优势主要体现在:
①Hive支持标准的SQL语法,免去了用户编写MapReduce程序的过程,大大减少了公司的开发成本
②Hive的出现可以让那些精通SQL技能、但是不熟悉MapReduce 、编程能力较弱与不擅长Java语言的用户能够在HDFS大规模数据集上很方便地利用SQL 语言查询、汇总、分析数据,毕竟精通SQL语言的人要比精通Java语言的多得多
③Hive是为大数据批量处理而生的,Hive的出现解决了传统的关系型数据库(MySql、Oracle)在大数据处理上的瓶颈
好了,上面通过一个简单的小业务场景说明了Hive的巨大优势,接下来将进入本篇文章的正题。
一:Hive体系结构(架构)的介绍
1、Hive的概念:
①Hive是为了简化用户编写MapReduce程序而生成的一种框架,使用MapReduce做过数据分析的人都知道,很多分析程序除业务逻辑不同外,程序流程基本一样。在这种情况下,就需要Hive这样的用户编程接口。Hive提供了一套类SQL的查询语言,称为QL,而在创造Hive框架的过程中之所以使用SQL实现Hive是因为大家对SQL语言非常的熟悉,转换成本低,可以大大普及我们Hadoop用户使用的范围,类似作用的Pig就不是通过SQL实现的。
Hive是基于Hadoop的一个开源数据仓库系统,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,Hive可以把SQL中的表、字段转换为HDFS中的目录、文件。
②Hive是建立在Hadoop之上的数据仓库基础构架、是为了减少MapReduce编写工作的批处理系统,Hive本身不存储和计算数据,它完全依赖于HDFS和MapReduce。Hive可以理解为一个客户端工具,将我们的sql操作转换为相应的MapReduce jobs,然后在Hadoop上面运行。
在开始为大家列举的consumer.txt小业务当中,从编写Sql到最后得出Beijing 3的分析结果实际上中间走的是MapReduce程序, 只不过这个MapReduce程序不用用户自己编写,而是由Hive这个客户端工具将我们的sql操作转化为了相应的MapReduce程序,下面是我们运行sql命令时显示的相关日志:
- hive> select city,count(*)
- > from t4
- > where city='beijing'
- > group by city;
- Total MapReduce jobs = 1
- Launching Job 1 out of 1
- Number of reduce tasks not specified. Estimated from input data size: 1
- In order to change the average load for a reducer (in bytes):
- set hive.exec.reducers.bytes.per.reducer=<number>
- In order to limit the maximum number of reducers:
- set hive.exec.reducers.max=<number>
- In order to set a constant number of reducers:
- set mapred.reduce.tasks=<number>
- Starting Job = job_1478233923484_0902, Tracking URL = http://hadoop22:8088/proxy/application_1478233923484_0902/
- Kill Command = /usr/local/hadoop/bin/hadoop job -kill job_1478233923484_0902
- Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
- 2016-11-09 11:36:36,688 Stage-1 map = 0%, reduce = 0%
- 2016-11-09 11:36:42,018 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.21 sec
- 2016-11-09 11:36:43,062 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.21 sec
- 2016-11-09 11:36:44,105 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.21 sec
- 2016-11-09 11:36:45,149 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.21 sec
- 2016-11-09 11:36:46,193 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.21 sec
- 2016-11-09 11:36:47,237 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.21 sec
- 2016-11-09 11:36:48,283 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.21 sec
- 2016-11-09 11:36:49,329 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 3.7 sec
- 2016-11-09 11:36:50,384 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 3.7 sec
- MapReduce Total cumulative CPU time: 3 seconds 700 msec
- Ended Job = job_1478233923484_0902
- MapReduce Jobs Launched:
- Job 0: Map: 1 Reduce: 1 Cumulative CPU: 3.7 sec HDFS Read: 419 HDFS Write: 10 SUCCESS
- Total MapReduce CPU Time Spent: 3 seconds 700 msec
- OK
- beijing 3
- Time taken: 19.768 seconds, Fetched: 1 row(s)
从日志可以看出,Hive将我们的sql命令解析成了相应的MapReduce任务,最后得到了我们的分析结果。
③Hive可以认为是MapReduce的一个封装、包装。Hive的意义就是在业务分析中将用户容易编写、会写的Sql语言转换为复杂难写的MapReduce程序,从而大大降低了Hadoop学习的门槛,让更多的用户可以利用Hadoop进行数据挖掘分析。
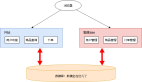
为了让大家容易理解Hive的实质-------“Hive就是一个SQL解析引擎,将SQL语句转化为相应的MapReduce程序”这句话,博主用一个图示进行示例:
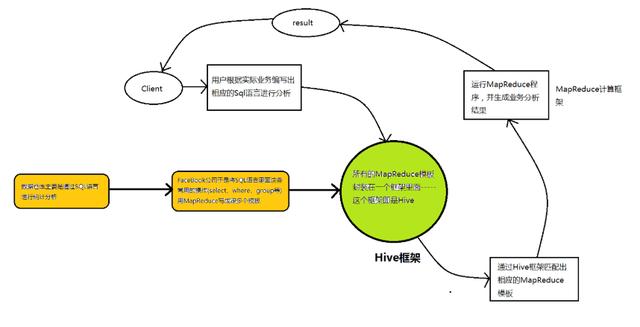
从图示可以看出,Hive从某种程度上讲就是很多“SQL—MapReduce”框架的一个封装,可以将用户编写的Sql语言解析成对应的MapReduce程序,最终通过MapReduce运算框架形成运算结果提交给Client。
2、Hive体系结构的介绍
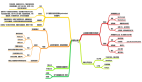
下面是Hive的体系结构图:
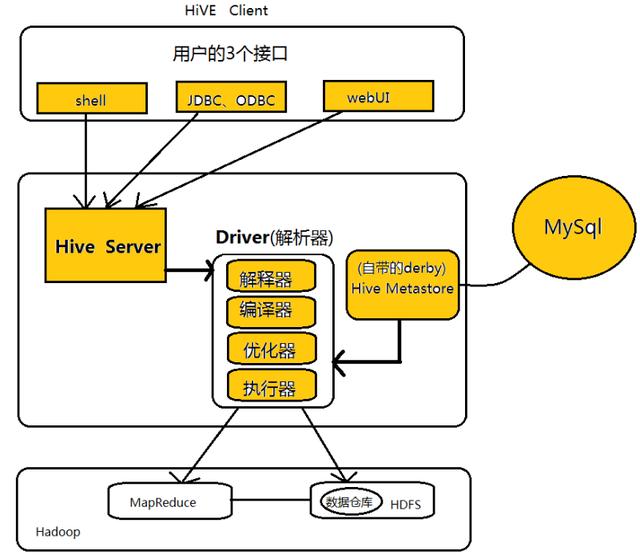
Hive的体系结构可以分为以下几个部分:
①用户接口:包括shell命令、Jdbc/Odbc和WebUi,其中最常用的是shell这个客户端方式对Hive进行相应操作
②Hive解析器(驱动Driver):Hive解析器的核心功能就是根据用户编写的Sql语法匹配出相应的MapReduce模板,形成对应的MapReduce job进行执行。
③Hive元数据库(MetaStore):Hive将表中的元数据信息存储在数据库中,如derby(自带的)、Mysql(实际工作中配置的),Hive中的元数据信息包括表的名字、表的列和分区、表的属性(是否为外部表等)、表的数据所在的目录等。Hive中的解析器在运行的时候会读取元数据库MetaStore中的相关信息。
在这里和大家说一下为什么我们在实际业务当中不用Hive自带的数据库derby,而要重新为其配置一个新的数据库Mysql,是因为derby这个数据库具有很大的局限性:derby这个数据库不允许用户打开多个客户端对其进行共享操作,只能有一个客户端打开对其进行操作,即同一时刻只能有一个用户使用它,自然这在工作当中是很不方便的,所以我们要重新为其配置一个数据库。
④Hadoop:Hive用HDFS进行存储,用MapReduce进行计算-------Hive这个数据仓库的数据存储在HDFS中,业务实际分析计算是利用MapReduce执行的。
从上面的体系结构中可以看出,在Hadoop的HDFS与MapReduce以及MySql的辅助下,Hive其实就是利用Hive解析器将用户的SQl语句解析成对应的MapReduce程序而已,即Hive仅仅是一个客户端工具,这也是为什么我们在Hive的搭建过程中没有分布与伪分布搭建的原因。(Hive就像是刘邦一样,合理的利用了张良、韩信与萧何的辅助,从而成就了一番大事!)
3、Hive的运行机制
Hive的运行机制如下图所示:
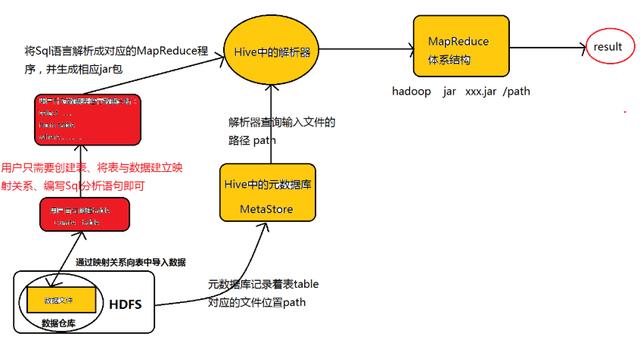
Hive的运行机制正如图所示:创建完表之后,用户只需要根据业务需求编写Sql语句,而后将由Hive框架将Sql语句解析成对应的MapReduce程序,通过MapReduce计算框架运行job,便得到了我们最终的分析结果。
在Hive的运行过程中,用户只需要创建表、导入数据、编写Sql分析语句即可,剩下的过程将由Hive框架自动完成,而创建表、导入数据、编写Sql分析语句其实就是数据库的知识了,Hive的运行过程也说明了为什么Hive的存在大大降低了Hadoop的学习门槛以及为什么Hive在Hadoop家族中占有着那么重要的地位。
二:Hive的操作
Hive的操作对于用户来说实际上就是表的操作、数据库的操作。下面我们将围绕两个方面进行介绍:
1、Hive的基本命令.
启动hive命令行:
- $>hive/bin/hive
- $hive>show databases ; -- 显式数据库
- $hive>create database mydb ; -- 创建数据库
- $hive>use mydb ; -- 使用库
- $hive>create table custs(id int , name string) ; -- 建表
- $hive>desc custs ; -- 查看表结构
- $hive>desc formatted custs ; -- 查看格式化表结构
- $hive>insert into custs(id,name) values(1,'tom'); -- 插入数据,转成mr.
- $hive>select * from custs ; -- 查询,没有mr
- $hive>select * from custs order by id desc ; -- 全排序,会生成mr.
- $hive>exit ; -- 退出终端
- 查看mysql中的元信息:
- select * from dbs ; -- 存放库信息
- select * from tbls ; -- 存放表信息
2、Hive表------内部表、外部表、分区表的创建
所谓内部表就是普通表,创建语法格式为:

实际操作:
外部表(external table)的创建语法格式为:

注意:最后一行写到的是目录dir,文件就不用写了,Hive表会自动到dir目录下读取所有的文件file
我在实际的操作过程当中发现,location关联到的目录下面必须都是文件,不能含有其余的文件夹,不然读取数据的时候会报错。

实际操作:
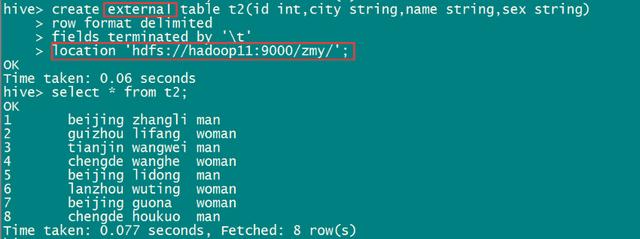
内部表与外部表的区别:
- 内部表在加载数据的过程中,实际数据会被移动到数据仓库目录中(hive.metastore.warehouse.dir),之后用户对数据的访问将会直接在数据仓库目录中完成;删除内部表时,内部表中的数据和元数据信息会被同时删除。
- 外部表在加载数据的过程中,实际数据并不会被移动到数据仓库目录中,只是与外部表建立一个链接(相当于文件的快捷方式一样);删除外部表时,仅删除该链接。
补充:在工作中发现,对于外部表,即使hive中的表删除了,但是在HDFS中表的location仍然存在。
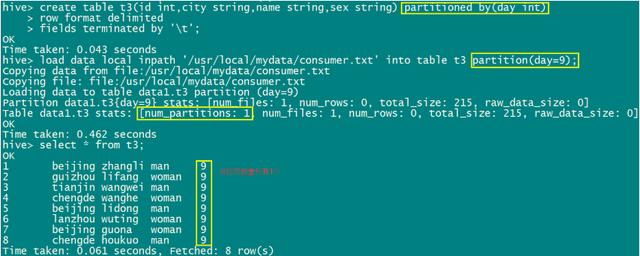
分区表的概念:指的是我们的数据可以分区,即按照某个字段将文件划分为不同的标准,分区表的创建是通过在创建表时启用partitioned by来实现的。
分区表的创建语法格式为:

注意:分区表在加载数据的过程中要指定分区字段,否则会报错,正确的加载方式如下:
- load data local inpath ‘/usr/local/consumer.txt’ into table t1 partition (day=2) ;
其余的操作和内部表、外部表是一样的。
实际操作:
参考2:
- CREATE EXTERNAL TABLE `fdm_buffalo_3_5_task_exec_time`(
- `task_id` int COMMENT '任务id',
- `task_version` string COMMENT '任务版本',
- `exec_time` string COMMENT '平均执行时长')
- PARTITIONED BY (
- `dt` string)
- ROW FORMAT DELIMITED
- FIELDS TERMINATED BY '\t';
- 实际:
- hive> show create table fdm_buffalo_3_5_task_exec_time;
- OK
- CREATE EXTERNAL TABLE `fdm_buffalo_3_5_task_exec_time`(
- `task_id` int COMMENT '任务id',
- `task_version` string COMMENT '任务版本',
- `exec_time` string COMMENT '平均执行时长')
- PARTITIONED BY (
- `dt` string)
- ROW FORMAT DELIMITED
- FIELDS TERMINATED BY '\t'
- STORED AS INPUTFORMAT
- 'org.apache.hadoop.mapred.TextInputFormat'
- OUTPUTFORMAT
- 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
- LOCATION
- 'hdfs://ns5/user/dd_edw/fdm.db/fdm_buffalo_3_5_task_exec_time'
- TBLPROPERTIES (
- 'mart_name'='dd_edw',
- 'transient_lastDdlTime'='1555384611')
- Time taken: 0.036 seconds, Fetched: 17 row(s)
3、将数据文件加载(导入)到Hive表中
在Hive中创建完表之后,我们随后自然要向表中导入数据,但是在导入数据的时候和我们的传统数据库(MySql、Oracle)是不同的:Hive不支持一条一条的用insert语句进行插入操作,也不支持update的操作。Hive表中的数据是以load的方式,加载到建立好的表中。数据一旦导入,则不可修改。要么drop掉整个表,要么建立新的表,导入新的数据。
导入数据的语法格式为:
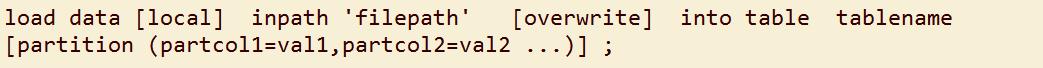
导入数据时要注意一下几点:
- local inpath表示从本地linux中向Hive表中导入数据,inpath表示从HDFS中向Hive表中导入数据
- 默认是向原Hive表中追加数据,overwrite表示覆盖表中的原数据进行导入
- partition是分区表特有的,而且在导入数据数据时是必须添加的,否则会报错
- load 操作只是单纯的复制/移动操作,将数据文件复制/移动到 Hive 表对应的位置,即Hive 在加载数据的过程中不会对数据本身进行任何修改,而只是将数据内容复制或者移动到相应的表中
导入示例代码:(注意overwrite的用法)
- hive> load data local inpath "/home/dd_edw/zmy_project/task_relations.txt" overwrite into table fdm.chevrolet_buffalo_task_recusion_relations partition(dt='2019-05-28');
- Loading data to table fdm.chevrolet_buffalo_task_recusion_relations partition (dt=2019-05-28)
- Moved: 'hdfs://ns5/user/dd_edw/fdm.db/chevrolet_buffalo_task_recusion_relations/dt=2019-05-28/task_relations.txt' to trash at: hdfs://ns5/user/dd_edw/.Trash/Current
- Moved: 'hdfs://ns5/user/dd_edw/fdm.db/chevrolet_buffalo_task_recusion_relations/dt=2019-05-28/task_relations_copy_1.txt' to trash at: hdfs://ns5/user/dd_edw/.Trash/Current
- Partition fdm.chevrolet_buffalo_task_recusion_relations{dt=2019-05-28} stats: [numFiles=1, numRows=0, totalSize=272475104, rawDataSize=0]
- OK
- Time taken: 3.381 seconds
- hive> dfs -ls hdfs://ns5/user/dd_edw/fdm.db/chevrolet_buffalo_task_recusion_relations/*/ ;
- Found 1 items
- -rwxr-xr-x 3 dd_edw dd_edw 272475104 2019-05-29 20:08 hdfs://ns5/user/dd_edw/fdm.db/chevrolet_buffalo_task_recusion_relations/dt=2019-05-28/task_relations.txt
4、Hive添加分区操作:
正确语句:
- hive> ALTER TABLE fdm_buffalo_3_5_task_exec_time ADD IF NOT EXISTS PARTITION (dt='2019-04-15');
- OK
- Time taken: 0.059 seconds
错误语句:
- hive> alter table fdm_buffalo_3_5_task_exec_time if not exists add partition (dt='2019-04-15');
- NoViableAltException(132@[])
- at org.apache.hadoop.hive.ql.parse.HiveParser.alterTableStatementSuffix(HiveParser.java:8170)
- at org.apache.hadoop.hive.ql.parse.HiveParser.alterStatement(HiveParser.java:7635)
- at org.apache.hadoop.hive.ql.parse.HiveParser.ddlStatement(HiveParser.java:2798)
- at org.apache.hadoop.hive.ql.parse.HiveParser.execStatement(HiveParser.java:1731)
- at org.apache.hadoop.hive.ql.parse.HiveParser.statement(HiveParser.java:1136)
- at org.apache.hadoop.hive.ql.parse.ParseDriver.parse(ParseDriver.java:202)
- at org.apache.hadoop.hive.ql.parse.ParseDriver.parse(ParseDriver.java:166)
- at org.apache.hadoop.hive.ql.Driver.compile(Driver.java:411)
- at org.apache.hadoop.hive.ql.Driver.compile(Driver.java:320)
- at org.apache.hadoop.hive.ql.Driver.compileInternal(Driver.java:1372)
- at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:1425)
- at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1150)
- at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1093)
- at org.apache.hadoop.hive.cli.CliDriver.processLocalCmd(CliDriver.java:241)
- at org.apache.hadoop.hive.cli.CliDriver.processCmd(CliDriver.java:191)
- at org.apache.hadoop.hive.cli.CliDriver.processLine(CliDriver.java:551)
- at org.apache.hadoop.hive.cli.CliDriver.executeDriver(CliDriver.java:969)
- at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:912)
- at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:824)
- at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
- at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
- at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
- at java.lang.reflect.Method.invoke(Method.java:606)
- at org.apache.hadoop.util.RunJar.run(RunJar.java:221)
- at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
- FAILED: ParseException line 1:43 cannot recognize input near 'if' 'not' 'exists' in alter table statement
5、查看某个分区
- desc formatted bdm.bdm_dispatch_1_d_task_da partition(dt='2019-07-14');
三:Hive与Hbase的区别
其实从严格意义上讲,Hive与Hbase就不应该谈区别,谈区别的原因无非就是Hive与Hbase本身都涉及到了表的创建、向表中插入数据等等。所以我们希望找到Hive与Hbase的区别,但是为什么两者谈不上区别呢,原因如下:
- 根据上文分析,Hive从某种程度上讲就是很多“SQL—MapReduce”框架的一个封装,即Hive就是MapReduce的一个封装,Hive的意义就是在业务分析中将用户容易编写、会写的Sql语言转换为复杂难写的MapReduce程序。
- Hbase可以认为是hdfs的一个包装。他的本质是数据存储,是个NoSql数据库;hbase部署于hdfs之上,并且克服了hdfs在随机读写方面的缺点。
因此若要问Hive与Hbase之前的区别,就相当于问HDFS与MapReduce之间的区别,而HDFS与MapReduce两者之间谈区别意义并不大。
但是当我们非要谈Hbase与Hive的区别时,可以从以下几个方面进行讨论:
Hive和Hbase是两种基于Hadoop的不同技术–Hive是一种类SQL的引擎,并且运行MapReduce任务,Hbase是一种在Hadoop之上的NoSQL 的Key/vale数据库。当然,这两种工具是可以同时使用的。就像用Google来搜索,用FaceBook进行社交一样,Hive可以用来进行统计查询,HBase可以用来进行实时查询,数据也可以从Hive写到Hbase,设置再从Hbase写回Hive。
Hive适合用来对一段时间内的数据进行分析查询,例如,用来计算趋势或者网站的日志。Hive不应该用来进行实时的查询。因为它需要很长时间才可以返回结果。
Hbase非常适合用来进行大数据的实时查询。Facebook用Hive进行消息和实时的分析。它也可以用来统计Facebook的连接数。