前言:
日常学习和工作中,经常会遇到导数据的需求。比如数据迁移、数据恢复、新建从库等,这些操作可能都会涉及大量数据的导入。有时候导入进度慢,电脑风扇狂转真的很让人崩溃,其实有些小技巧是可以让导入更快速的,本篇文章笔者会谈一谈如何快速的导入数据。
注:本篇文章只讨论如何快速导入由逻辑备份产生的SQL脚本,其他文件形式暂不讨论。
1.尽量减小导入文件大小
首先给个建议,导出导入数据尽量使用MySQL自带的命令行工具,不要使用Navicat、workbench等图形化工具。特别是大数据量的时候,用MySQL自带的命令行工具导出和导入比用Navicat等图形化工具要快数倍,而且用Navicat等图形化工具做大数据量的操作时很容易卡死。下面简单介绍下怎么用MySQL自带的命令行工具做导入导出。
# 导出整个实例
mysqldump -uroot -pxxxxxx --all-databases > all_database.sql
# 导出指定库
mysqldump -uroot -pxxxxxx --databases testdb > testdb.sql
# 导出指定表
mysqldump -uroot -pxxxxxx testdb test_tb > test_tb.sql
# 导入指定SQL文件 (指定导入testdb库中)
mysql -uroot -pxxxxxx testdb < testdb.sql
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
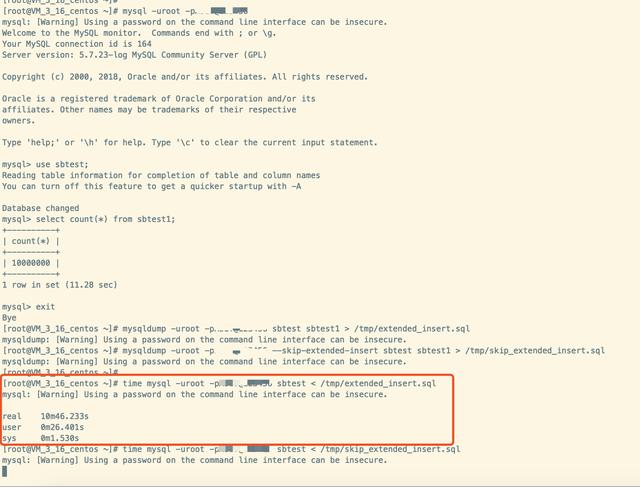
导入的SQL脚本内容大多是先建库建表,然后插入数据,其中耗时最长的应该是insert插入数据了。为了减小文件大小,推荐使用扩展插入方法,即多行一起批量insert,类似这样:insert into table_name values (),(),(),...,(); 。使用扩展插入比一条条插入,文件大小要小很多,插入速度要快好几倍。使用mysqldump导出的文件默认是使用批量插入的方法,导出时可使用--skip-extended-insert 参数改为逐条插入。下面以一张一千万的数据表为例,测试下不同方式导出的文件插入时的速度。
截图
上图可以看出,使用扩展插入的SQL脚本导入大概需要10分钟左右,而一条条插入的SQL脚本导入时间过长,大概1个小时仍然没有导完,一个2个多G的文本导入一个多小时仍未结束,等不及的笔者就手动取消了 不过还是可以看出多条一起insert比一条条插入数据要节省数倍的时间。
2.尝试修改参数加快导入速度
在MySQL中,有一对大名鼎鼎的“双一”参数,即 innodb_flush_log_at_trx_commit 与 sync_binlog 。为了安全性这两个参数默认值为1,为了快速导入脚本,我们可以临时修改下这两个参数,下面简单介绍下这两个参数:
innodb_flush_log_at_trx_commit默认值为1,可设置为0、1、2
如果innodb_flush_log_at_trx_commit设置为0,log buffer将每秒一次地写入log file中,并且log file的flush(刷到磁盘)操作同时进行.该模式下,在事务提交的时候,不会主动触发写入磁盘的操作。 如果innodb_flush_log_at_trx_commit设置为1,每次事务提交时MySQL都会把log buffer的数据写入log file,并且flush(刷到磁盘)中去. 如果innodb_flush_log_at_trx_commit设置为2,每次事务提交时MySQL都会把log buffer的数据写入log file.但是flush(刷到磁盘)操作并不会同时进行。该模式下,MySQL会每秒执行一次 flush(刷到磁盘)操作。
sync_binlog默认值为1,可设置为[0,N)
当sync_binlog =0,像操作系统刷其他文件的机制一样,MySQL不会同步到磁盘中去而是依赖操作系统来刷新binary log。 当sync_binlog =N (N>0) ,MySQL 在每写 N次 二进制日志binary log时,会使用fdatasync()函数将它的写二进制日志binary log同步到磁盘中去。
这两个参数可以在线修改,若想快速导入,可以按照下面步骤来操作:
# 1.进入MySQL命令行 临时修改这两个参数
set global innodb_flush_log_at_trx_commit = 2;
set global sync_binlog = 2000;
# 2.执行SQL脚本导入
mysql -uroot -pxxxxxx testdb < testdb.sql
# 3.导入完成 再把参数改回来
set global innodb_flush_log_at_trx_commit = 1;
set global sync_binlog = 1;
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
还有另外一种场景是你的需求是新建从库,或者是不需要产生binlog,这时候导入SQL脚本时可以设置暂时不记录binlog,可以在脚本开头增加 set sql_log_bin=0; 然后再执行导入,这样速度会进一步加快。如果你的MySQL实例没有开启binlog则不需要再执行该语句了。
总结:
本篇文章主要介绍快速导入数据的方法,可能还有其他方法快速导入数据,比如load data或者写程序多线程插入。本文中介绍的方法只适合手动导入SQL脚本,下面总结下本文中提到的方法。
- 使用MySQL自带的命令行工具进行导出导入。
- 使用扩展插入方法,一个insert对于多个值。
- 临时修改innodb_flush_log_at_trx_commit和sync_binlog参数。
- 关闭binlog或者临时不记录binlog。
其实还有一些其他方案,比如先不创建索引,插入数据后再执行添加索引操作;或者先将表改为MyISAM或MEMORY引擎,导入完成后再改为InnoDB引擎。不过这两种方法实施起来较为麻烦且不知效果如何。以上方法只是笔者依据个人经验总结得出,可能不太全面,欢迎各位补充哦。