












在之前的文章当中我们已经介绍了好几个模型了,有朴素贝叶斯、KNN、KMeans、EM还有线性回归和逻辑回归。今天我们来和大家聊聊该怎么评估这些模型。
均方差
这个概念很简单,它和回归模型当中的损失函数是一样的。可以理解成我们预测值和真实值之间的偏差,我们用y表示样本的真实值,y_表示模型的预测值,那么均方差可以写成:
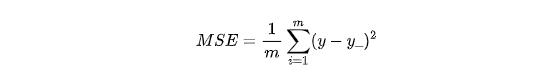
这里的m是样本的数量,是一个常数,我们也可以忽略,如果忽略的话就是平方差和,好像并没有一个专门的术语。而且如果不算均值的话,可能这个和会很大,所以通常我们会计算均值。
这里的MSE是mean square error的缩写,也就是平均方差的意思。我们都知道方差在统计学当中表示样本距离均值的震荡程度,方差越大,表示一个指标越不稳定,波动幅度越大。在回归模型的场景当中,我们衡量的不是距离均值的离散程度,而是距离实际值的离散程度。这两者的含义非常近似,应该不难理解。
均方差越小说明模型距离真实值越接近,所以它既可以作为模型训练时候的损失函数,又可以作为我们人工审查模型效果的参考。
回归模型一般使用的指标就是均方差,而分类模型则要复杂得多,会涉及好几个指标,我们一个一个来看。
TP, TN, FP和FN
这四个值看起来傻傻分不清楚,但是一旦我们理解了它们的英文,其实很好懂。T表示true,也就是真,那么F自然表示false,也就是假。P表示positive,可以理解成阳性,N就是negative,就是阴性。这里的阴阳没有逻辑上的含义,表示的只是类别,我们也可以理解成01或者是甲乙,因为没有逻辑因素,所以叫什么都一样。
所以这四个就是真假和阴阳的排列组合,有T的都表示真,可以理解成预测正确。比如TP就是真阳,也就是说检测是阳性,实际上也是阳性。同理,TN就是真阴,检测是阴性,实际上也是阴性。有F则表示预测错误,FP是假阳,也就是检测是阳性,但是实际上是阴性,表示检测错了。同理,FN是假阴,检测是阴性,但是实际上是阳性。
我们用医院检测代入这几个值当中一下就理解了,TP和TN表示检测试剂给力,检测准确,检测是阴就是阴,是阳就是阳。而FP和FN说明检测试剂不行,检测错了,要么就把没病的检测出了有病,要么就是明明有病没检测出来。显然在医疗检测的场景当中,假阳是可以接受的,假阴不行。因为假阳我们还可以再检测,来确定究竟是阴还是阳,如果假阴放过了病例会对病人产生不好的影响,所以一般来说医疗检测试剂都会比标准更加敏感,这样才能尽量不放过漏网之鱼。
召回率
召回率的英文是recall,我觉得这个词翻译得很好,中文的意思和英文基本一致,也有的教材当中翻译成查全率,我感觉差了点意思,还是叫召回率更加信雅达一些。
我们假设一个场景,比如说甲是一个排长,手下有10个小兵,有一个任务需要甲召集所有成员去执行。甲一声令下,召来了8个。那么召回率就是80%。我们放入机器学习的场景当中去也是一样的,在二分类场景当中,一般情况下模型考虑的主要都是正例。可以理解成沙里淘金,负例就是沙,一般价值不大,而金子就是正例,就是我们需要的。所以召回率就是我们预测准确的正例占所有正例的比例。
我们把上面的TP、TN、FP和FN代入计算,我们可以得到:
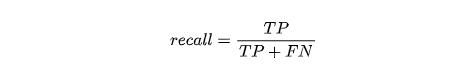
TP就是我们预测准确的正例,也就是被我们召回的部分,那么所有的正例有多少呢?答案是召回的正例加上没有召回的正例,没有召回的正例说明预测错了,预测成负例了。但是它们并不是负例,所以就是假阴性的样本,自然也就是FN。这里有一点点绕,关键点是召回是针对正例的,不操心负例的情况。就好比你去淘金,你显然不会关心沙子的情况,只会关心金子有没有捞到,一个意思。
精确率和准确率
你可能在很多机器学习的书本当中看到过这两个值,有可能你看的时候还记得它们之间的区别,但是看完之后就忘记了,甚至有可能从此陷入了混淆的状态。这并不稀奇,我也经历过,甚至我在面试的时候还搞错了。
这里面的原因很大一部分在于翻译问题,这两个值翻译得太接近了。我们从中文上很难区分出精确率和准确率有什么差别,在我们看来,这两个词是等价的,然而英文当中这两个词是做了区分的。所以我们要搞清楚这两者,需要来看英文的解释,而不是只是记住一个概念。
在英文当中,精确率的英文是precision,词典当中的解释是:precision is defined as the proportion of the true positives against all the positive results (both true positives and false positives). 翻译过来是所有预测为正例的样本当中,正确的比例。
准确率英文是accuracy,英文解释是:accuracy is the proportion of true results (both true positives and true negatives) in the population. 翻译过来也就是预测结果准确的概率,既然是预测结果准确,那么显然既包含了正例也包含了负例。
从英文的描述上我们可以明显地看出这两个概念的差异,两个都是预测正确的部分,但精确率只针对正例,而准确率针对的是所有样本,既包含正例也包含负例。我个人觉得这两者翻译成筛选正确率和判断正确率比较容易理解一些,如果只有精确率和准确率可能还好,再加上上面说的召回率,可能真的要晕菜的。
我们来举一个例子,来把这三个指标都说清楚。
假设在国共内战期间,tg要抓军统的特务,已经锁定了一个村子中的100个百姓,交给甲乙两个人去找出特务。其中甲挑选了18个人,其中有12个特务,乙呢挑选了10个人,其中有8个特务。假设我们知道一共有20个特务,那么请问,这两个人的召回、准确和精确率分别是多少?
我们先来看甲,我们先从简单的召回开始,既然一共有20个特务,甲找出了其中的12个,那么召回率就是12/20 = 0.6。精确是筛选正确率,我们一共筛选出了18人,其中有12个是正确的,所以精确率是12/18 = 2/3。准确率呢是整体的正确率,它判断正确了12个特务和80个普通百姓,准确率是(12 + 82 - 8) / 100,也就是86%。
我们再来看乙,它的召回率是8 / 20 = 0.4,精确率呢是8 / 10 = 0.8,准确率是(8 + 90 - 12) / 100 = 86%。
从上面这个例子当中,我们可以得到精确率和准确率的公式。
其中精确率是筛选正确的概率,就是筛选正确的数量除以筛选出来的样本数,筛选正确的数量自然就是TP,筛选出来的总数除了正确的还有错误的,筛选错误的也就是FP,所以:
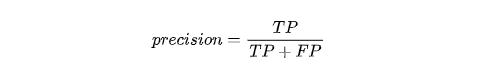
准确率是整体上来正确率,也就是所有正确的除以所有样本数量:
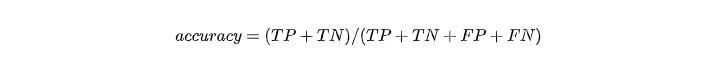
recall和precision的取舍
我们继续研究刚才的例子,从甲乙两人的结果当中我们会发现他们两人的准确率都很高,都是86%。但是你会发现这个值没什么意义,因为我如果一个特务也没抓出来,准确率一样可以有80%。因为负样本太多了,拉升了整体的准确率,并不能说明问题。如果负样本占据的比例还要大,那么准确率还会进一步提升。
比如在医疗行业当中,一些疾病的检测看准确率是没有用的,因为发病率本身并不高,大量的都是负样本。如果啥也检测不出来,一样可以得出很高的准确率。明白了这点之后,也会减少很多忽悠,比如很多假药或者假仪器骗子用准确率来说事欺骗消费者。
在负例不重要的场景当中,我们一般不会参考准确率,因为会受到负例的影响。那么recall和precision这两个值我们应该参考哪个呢?
我们再回到问题的场景当中,甲乙两个人,甲的召回更高,20个特务里找到了其中的12个。而乙的准确率更高,找出的10个人里面有8个是特务,命中率很高。那么这两个人究竟谁更强呢?
代入问题的场景,你会发现这个问题没有标准答案,答案完全取决于他们两人的上司。如果上司是一个利己主义者,更加注重业绩,宁可杀错不可放过,那么他显然会觉得甲更好,因为抓到的特务更多。如果上司是悲天悯人的仁者,他显然会更喜欢乙,少抓错一点就少给老百姓带来一些损伤。所以这并不是一个技术问题,而是一个哲学问题。
哪一个更好完全取决于看待问题的角度和问题的场景,如果我们换一个场景就不一样了。如果是疾病筛查的场景,我可能会希望召回更高的,这样可以尽可能多地召回正例。至于检测结果不准确,我们可以多测几次来增加置信度,但是如果放过了一些样本就会带来患者漏诊的风险。如果是风控场景,由于查到了作弊行为后往往会采取严厉的处罚,我们当然更关注精确率,因为一旦抓错会给用户带来巨大的损伤,可能就卸载app再也不来了,所以宁可放过也不可杀错。
有没有一个指标可以综合考虑召回和精确呢?还是有的,这个值叫做F1-score。
它的定义是:
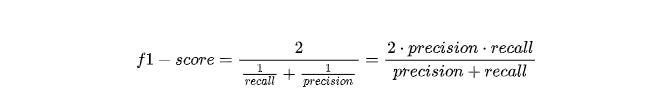
如果熟悉数学的同学会发现f1-score本质上是recall和precision的调合平均数,我们可以用它来均衡recall和precision,方便我们做取舍。我们也可以计算一下刚才甲和乙的f1-score,计算下来,甲的f1-score是0.631,乙的f1-score是0.533,所以整体上来说还是甲更好。
recall和precision的trade-off
我们继续刚才的例子,如果你们做过许多模型,你们会发现在机器学习领域当中,recall和precision是不可调和的两个值,一个模型精确率高了,往往召回就低,而召回高了,精确率就低,我们很难做到精确和召回一起提升,这是为什么呢?
我用逻辑回归模型举例,我们来看下下面这张图:
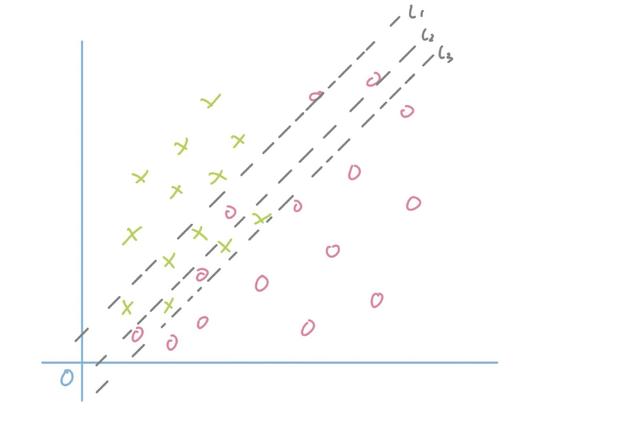
图中的l1,l2和l3可以看成是3个不同的模型,显然我们可以看得出来l1的精确率最高,但是召回最低,而l3的精确最低,但是召回最高。
这是由两个原因导致的,第一个原因是我们的样本存在误差,尤其是临界边缘的数据由于存在误差,会互相渗透。第二个原因是模型的拟合能力有限,比如在这个例子当中,我们用的是线性模型,我们只能以线性平面划分样本。如果扩大召回,就必然会导致混入更多错误样本,如果提升精度,必然召回会下降。
显然,这是一个交易,英文是trade-off,我们不能都要,必须要在两者之间做个选择。当然如果我们换成拟合能力更强大的模型,比如gbdt或者是神经网络,会取得更好的效果,但是也并非是没有代价的,越复杂的模型训练需要的样本数量也就越多。如果没有足够的样本,模型越复杂越难收敛。
这是一个考验算法工程师的经典场景,我们需要根据我们的场景做出合适的选择。究竟是要扩大召回,还是提高精确。以逻辑回归模型举例,我们以0.5位阈值来判断是正例还是负例,理论上来说,我们提升这个阈值,就可以提升模型的精确度,但是与此同时召回率也会下降。反之,如果我们降低这个阈值,我们会得到更多的正例,同时也意味着会有更多的负例被误判成了正例,精确度也就降低。
总结
今天介绍的这几个概念不仅是机器学习基础中的基础,更是面试当中的常客,作为一个合格的算法工程师,这是必须要理解的内容。
如果觉得迷糊了,可以想想那个抓间谍的例子,非常生动有效,一定可以帮助你们加深记忆。















