本文转载自公众号“读芯术”(ID:AI_Discovery)
2020年注定是不平凡的一年。开年伊始的新冠疫情打乱了所有人、行业、甚至国家的节奏。
人们通常把极端异常的事件成为“黑天鹅事件”,新冠这只“黑天鹅”,不仅在爆发时让人措手不及,人们为了遏制疫情而采取的措施,正在世界全方位的系统中产生巨大的连锁反应,包括卫生健康、商业、金融、交通和旅行等等。
黑天鹅事件也给机器学习模型带来了不小的挑战。ML模型基于先前观测到的数据,从而可以预测到未来的场景。然而,这些模型如今遇到的事件,和它们接受过的训练却大相径庭。
以信贷和金融领域为首的许多企业组织中,运行着百余个甚至上千个实时生产模型,这些模型对数据做出了错误的决策,进而会影响接下来的业务成效。未来几天、几个月可能出现问题的模型包括信贷、房屋定价、资产定价、需求预测、转换/流失模型、零售公司的供求关系、广告定价等等。
标准模型训练过程会在模型中给出尽可能多的数据,帮助其适应通用跨事件的数据结构,预测在训练数据中未见过的场景是困难的。而真正的黑天鹅事件正是这样,没法在其他事件中学习结构,靠人们去填补数据和模型的空白。那该怎么办?
本文将试图给出答案。事实上,已经有一些出色的实践,通过对生产模型进行强有力的监视、分析和故障排除来掌握离群值事件。
当前的环境有多极端?
极端到了极点了。
从天气、失业率、交通模式、用户支出等输入特性数据进入生产模型时,你会发现这些数据与模型的训练数据相差甚远。
首先看看刚刚发布的失业率数据。申请失业人数高达328万,比第二峰值高出4-5倍,是西格玛事件的25倍不止。
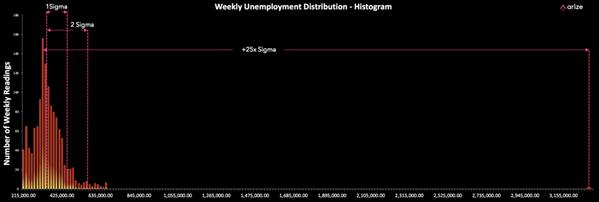
美国就业与培训管理局1995年至今图表
任何使用失业数据作为输入并依此做出决策的模型,都使用了超出预期值20个希格玛的特征。而这是每10万年才会发生一次的事件!这只是系列极端事件中的一个,并且被应用于日常商业决策的模型中而已。
模型不可能完美处理所有预期外的输入。因此,重要的是考虑整个系统处理这些输入的弹性程度,以及出现问题时排除故障的能力。
团队最重要的事情是拥有可观测的模型;不会观测,就学不会适应。这意味着要对模型决策进行检测和分析。
模型可观测性要求:
- 能检测到异常值的事件,并自动展示
- 能把离群值事件和用于排除模型故障反应的分析相联系
很明显,失业数据将彻底散乱分布。
再来看看汽车交通的数据:
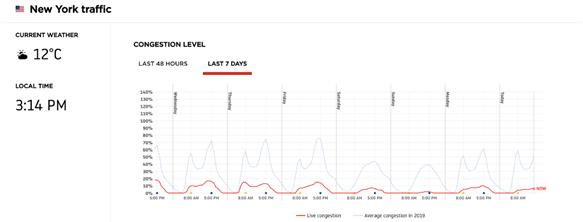
素材来源:TomTom International
上图为纽约3月18日至3月24日的交通量,交通量已经跌至每日交通量的20%,去往任何地方的交通量都跌为先前的1-10%。
降幅远超预期中的日值,而这只是模型预期值的一小部分。
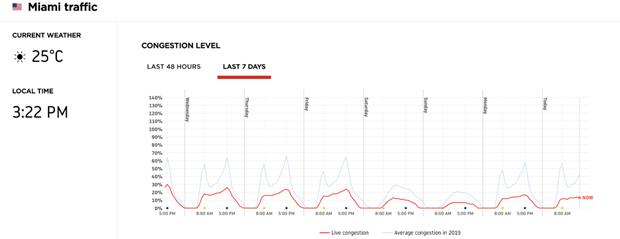
素材来源:TomTom International
迈阿密的交通量并没有像纽约下降的那么多。看起来迈阿密的居民并没有像纽约那样积极采取隔离措施。在这种情况下,进行城市特定预测的ML模型,在使用交通量作为输入时,会因为城市的不同而产生变化。
模型可观测性要求:
- 能监控到输入数据的分布偏移
- 模型输入强有力的剪切和过滤能力
从目前的表现看,面对冠状病毒带来的影响,AI并没有做好准备。天气预报不准确,银行也认为人工智能模型可能无法应对市场低迷。
在极端时期建立弹性机制
对于突逢巨变的企业来说,目前正应用于生产的AI/ML模型所依据的训练数据,与现如今的情况大不相同。
当模型以前没有经历过这些情况时,企业应该怎么做呢?当过去与现在脱节,我们该如何预测未来?
图源:unsplash
新冠状病毒持续影响许多人类系统,利用AI/ML的企业将不得不在其生产环境中建立弹性机制。模型性能会不断波动,企业需要对生产模型进行实时监控,了解模型输入是如何变化的,以及模型在哪些方面仍有欠缺。
输入的东西必须反应在输出
一切要从输入数据用于生成预测的模型开始。
如果这个罕见事件和其他极端事件有相似之处,那么就有办法将预测结果组合,创建基准周期并进行分析。
如果罕见事件在输入数据结构后,与训练集中的任何其他数据组都没有关系,那仍然需要监测它是如何影响模型的。
在新冠病毒肺炎的案例中,这些场景并非单次的异常值,而是出现在世界各地不同城市,呈数以百万计的快速发展趋势,每个趋势都有不同的时间线和反应。展开情景的规模需要大量不同的分析和检查,跨越许多不同的预测子群。
以下是AI/ML模型在生产中应该具备的输入级观测:
- 输入检查,以确定特性的值和分布是否与正常基准周期大相径庭
- 检测模型最敏感的特性是否已经发生了巨大的变化
- 检测用于确定特性与训练集之间的差距的统计数据
- 检查单个事件或少量最近发生的事件,发现分布问题
图源:unsplash
模型反应怎么样?
了解输入发生的变化后,接下来要监视的就是模型如何对极端输入做出反应。
检查特定预测子类的模型性能,诸如能源、航空或旅游业等某些行业可能面临的重大风险,需要针对不同的预测组进行快速的在线检查。
利用以前产生最坏情况的情景和基本情况的情景,然后与结果进行比较。实时监控收到的每个新的真实事件,获得真实世界预测的反馈。如果由于时间滞后,无法得到真实世界的反馈,可以使用代理度量标准,这样可以通过预测和测量来决定模型的性能。
极端环境下ML模型生产的优秀实践
在Arize人工智能,我们每天都在思考ML的可观察性和弹性,目的就是在这个不确定的时期把我们的一些经验传授给更多的团队。
ML生产模型的最佳实践离生产软件的最佳实践并不遥远,只需构建可观测工具,以了解当模型或软件激活时会发生什么,在其影响客户之前捕捉到会发生的问题。
从在许多公司部署的AI/ML模型背景来看,我们正在分享这些极端环境下生产ML模型的一些优秀实践。
1. 跟踪和识别异常事件
这包括跟踪输入数据和异常事件的模型性能。在为未来的极端环境收集训练数据时,给这些事件加注释,筛选异常事件是大有帮助。考虑是否将异常事件包括在数据中,以便将来进行模型训练也很重要。这个模型将积极应对未来的极端情况,但它也可能认为极端情况是新的常态。
2. 决定模型后备计划
在过去,当模型没有什么可以学习的时候,它在做什么?
了解模型在过去极端环境中的表现,有利于理解模型现在是如何执行的。如果模型表现不佳,你能根据最后的n分钟或n天设置一些简单的预测,并将模型表现与这个简单模型进行比较吗?
3. 寻找相似的事件
能够观察过去类似的事件为当前的情况建立相似的模型吗?例如,如果模型采用了失业数据作为输入,或许可以利用类似的经济衰退时的失业数据,比如2008年的经济衰退。
4. 建立多样化的模型组合,比较模型的性能
对外部世界做出反应的实时模型,如今可能比批量预测表现得更好。拥有多样化的模型组合,使团队能够将模型性能及路由流量,与能够更好应对极端环境的模型进行比较。
5. 模型性能无法改善时,了解模型预测的不确定性。
有时候可能并没有好的模型,这种情况下,如何知道你的模型有多不确定吗?此时,可以利用贝叶斯方法返回模型的预测及其置信水平。
监测是最重要的。驯服“黑天鹅”,或许不是天方夜谭。