目前越来越多的网站、编辑器、编程语言都已支持一种叫“正则表达式”的字符串查找“公式”,有过编程经验的同学都应该了解正则表达式(Regular Expression 简写regex)是什么东西,它是一种字符串匹配的模式(pattern),更像是一种逻辑公式。
- 使用正则表达式去匹配字符串Hello World 中的 Hello
- 伪代码:/Hello/, "Hello World"
- 输出:Hello
如何写好一篇关于 正则表达式 的文章,我思考了一周的时间,从未有一篇文章能让猪哥如此费神。
因为我觉得正则表达式 :难记忆、难描述、广而深且不受重视,有人说正则表达式既好写也难写!
- 好写:无非写一些常用、实用的案例,说实话你们每个人都能写出这种:在网上百度一下然后结合一点自己的实际经验,一篇文章就出来了。
- 难写:很多人都认为正则简单,不用记,要用就百度一下。但是绝大多数人了解的只是正则的一个小面,真正的精髓却很少关注!
猪哥希望大家能知道正则的知识点其实非常非常多,尤其是正则引擎执行原理以及正则优化,这算是正则表达式的进阶知识点,面试中也可能会被问到。
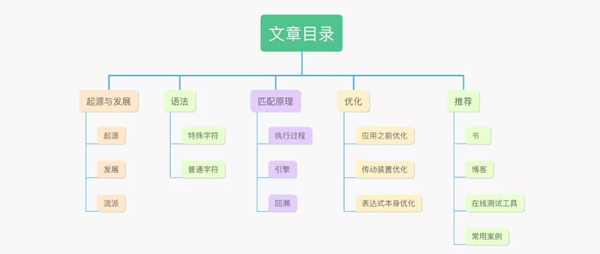
一、起源与发展
我们在学习一门技术的时候有必要了解其起源与发展过程,这对我们去理解技术本身有一定的帮助!
20世纪40年代:正则表达式最初的想法来自两位神经学家:沃尔特·皮茨与麦卡洛克,他们研究出了一种用数学方式来描述神经网络的模型。
1956年:一位名叫Stephen Kleene的数学科学家发表了一篇题目是《神经网事件的表示法》的论文,利用称之为正则集合的数学符号来描述此模型,引入了正则表达式的概念。正则表达式被作为用来描述其称之为“正则集的代数”的一种表达式,因而采用了“正则表达式”这个术语。
1968年:C语言之父、UNIX之父肯·汤普森把这个“正则表达式”的理论成果用于做一些搜索算法的研究,他描述了一种正则表达式的编译器,于是出现了应该算是最早的正则表达式的编译器qed(这也就成为后来的grep编辑器)。
Unix使用正则之后,正则表达式不断的发展壮大,然后大规模应用于各种领域,根据这些领域各自的条件需要,又发展出了许多版本的正则表达式,出现了许多的分支。我们把这些分支叫做“流派”。
1987年:Perl语言诞生了,它综合了其他的语言,用正则表达式作为基础,开创了一个新的流派,Perl流派。之后很多编程语言如:Python、Java、Ruby、.Net、PHP等等在设计正则式支持的时候都参考Perl正则表达式。

到这里我们也就知道为什么众多编程语言的正则表达式基本一样,因为他们都师从Perl。
注:Perl语言是一种擅长处理文本的语言,但因晦涩语法和古怪符号不利于理解和记忆导致很多开发者并不喜欢。
二、语法
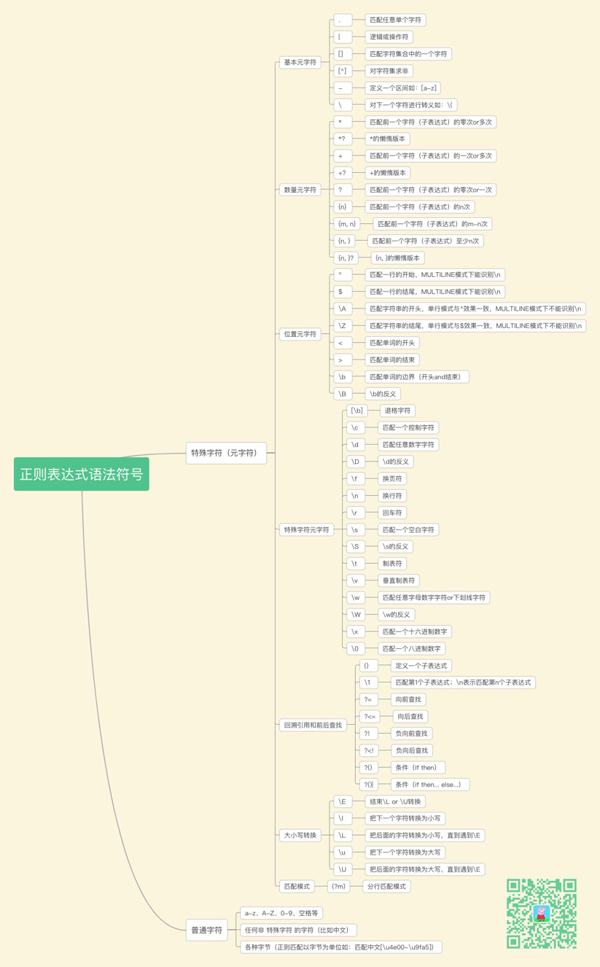
完整的正则表达式由两种字符构成:特殊字符(元字符)和普通字符。
ps:元字符表示正则表达式功能的最小单位,如 * ^ $ \d 等等
关于语法部分猪哥并不想过多的讲解,给大家做一个详细的归纳整理,供大家日后快速查找吧!
如果想系统学习正则表达式的语法部分,猪哥推荐 菜鸟教程: https://www.runoob.com/regexp/regexp-tutorial.html
三、匹配原理
匹配原理是猪哥想要重点讲解的部分,也希望同学们可以认真了解这部分的内容。
很多人觉得开车没必要了解车的构造原理,但是我们学编程的还真的需要了解原理。
因为了解原理,你才能调优,这往往也是初级工程师与中高级工程师之间的差别点之一!
1.执行过程
正则表达式的执行,是由正则表达引擎编译执行的,大致的执行流程猪哥也画了个流程图给大家看看。
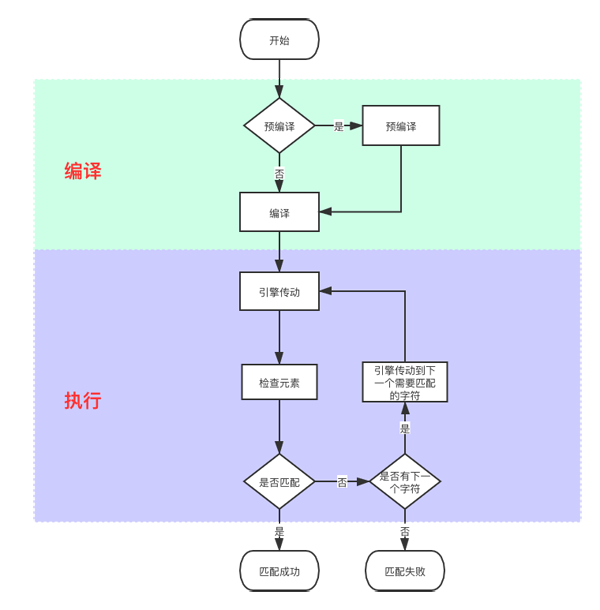
这里给大家提一点就是:预编译(pre-use compile)
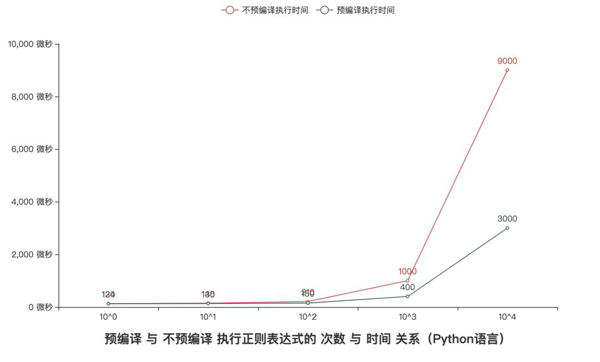
猪哥建议大家在生产环境中使用预编译功能,为什么呢?
以Python语言内置re模块举例:
- 通过re.compile(pattern)预编译返回Pattern对象,在后面代码中可以直接引用。
- 通过re.match(pattern, text)即用编译,虽然也会有缓存Pattern对象,但是每次使用都需要去缓存中取出,比预编译多一步取操作。
猪哥也通过实际测试来 验证预编译 确实比 即用编译 要快!
- pattern = r'http:\/\/(?:.?\w+)+'
- text = '<a href="http://www.xxx.com">xxx.com</a>'
2.引擎(重点)
既然正则表达式由执行引擎执行,那我们就来讲讲正则表达式的引擎吧,这一块是重点,希望大家仔细看看,弄懂了理解了才行!
正则引擎主要可以分为基本不同的两大类:
- DFA (Deterministic finite automaton) 确定型有穷自动机
- NFA (Non-deterministic finite automaton) 非确定型有穷自动机
ps:当然还有一种引擎为:POSIX NFA,这是根据NFA引擎出的规范版本,但因为使用较少所以我们这里也就不重点讲解。
这里需要和大家解释下何为确定型、有穷、自动机这几个名词:
- 确定型与非确定型:假设有一个字符串(text=abc)需要匹配,在没有编写正则表达式的前提下,就直接可以确定字符匹配顺序的就是确定型,不能确定字符匹配顺序的则为非确定型。
- 有穷:有穷即表示有限的意思,这里表示有限次数内能得到结果。
- 自动机:自动机便是自动完成,在我们设置好匹配规则后由引擎自动完成,不需要人为干预!
根据上面的解释我们可得知DFA引擎 和 NFA引擎 的一个很大区别就是:在没有编写正则表达式的前提下,是否能确定字符执行顺序!
DFA引擎执行原理:
为了大家能很清楚的理解DFA引擎执行原理,猪哥制作了一个简易的动态执行过程图给大家看看

根据上面的动图我们可以得出DFA引擎的一些特点:
- 文本主导:按照文本的顺序执行,这也就能说明为什么DFA引擎是确定型(deterministic)了,稳定!
- 记录当前有效的所有可能:我们看到当执行到(d|b)时,同时比较表达式中的d和b,所以会需要更多的内存。
- 每个字符只检查一次:这提高了执行效率,而且速度与正则表达式无关。
- 不能使用反向引用等功能:因为每个字符只检查一次,文本零宽度(位置)只记录当前比较值,所以不能使用反向引用、环视等一些功能!
NFA引擎执行原理:
猪哥同样画了一个简易的NFA引擎执行过程图方便大家理解

根据上面的动图我们可以得出NFA引擎的一些特点:
- 文表达式主导:按照表达式的一部分执行,如果不匹配换其他部分继续匹配,直到表达式匹配完成。
- 会记录某个位置:我们看到当执行到(d|b)时,NFA引擎会记录字符的位置(零宽度),然后选择其中一个先匹配。
- 单个字符可能检查多次:我们看到当执行到(d|b)时,比较d后发现不匹配,于是NFA引擎换表达式的另一个分支b,同时文本位置回退,重新匹配字符'b'。这也是NFA引擎是非确定型的原因,同时带来另一个问题效率可能没有DFA引擎高。
4. 可实现反向引用等功能:因为具有回退这一步,所以可以很容易的实现反向引用、环视等一些功能!
两种引擎比较
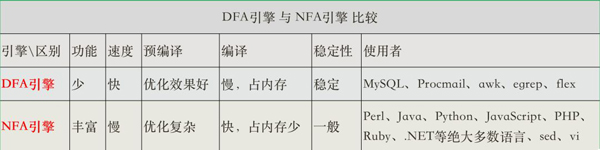
关于这两种引擎的总结,猪哥引用《精通正则表达式》书本中的一句话来概括:
DFA(电动机) 和NFA(汽油机) 都有很长的历史,不过,正如汽油机一样,NFA 的历史更长一些。也有些系统采用了混合引擎,它们会根据任务的不同选择合适的引擎(甚至对同一表达式中的不同部分采用不同的引擎,以求得功能与速度之间的最佳平衡)。 ——《精通正则表达式》
3.回溯(重点)
作为绝大多数编程语言都选择的引擎——NFA (非确定型有穷自动机) 引擎,我们当然要再详细了解一下它的精髓——回溯。

动图中,我们可以看到当某个正则分支匹配不成功之后,文本的位置需要回退,然后换另一个分支匹配,而回退这步专业术语就叫:回溯。
回溯的原理类似我们走迷宫时走过的路设置一个标志物,如果不对则原路返回,换另一条路。
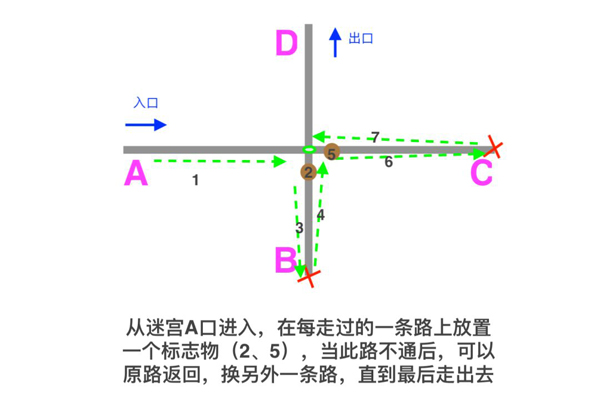
回溯机制不但需要重新计算正则表达式和文本的对应位置,也需要维护括号内的子表达式所匹配文本的状态(b匹配成功),保存到内存中以数字编号的组中,这就叫捕获组。
保存括号内的匹配结果之后,我们在后面的正则表达式中就可以使用,这就是我们所说的反向引用,在上面的案例中只有一个捕获,所以$1=b。
回溯陷阱:讲到回溯必须提到回溯陷阱,它导致的结果就是机器CPU使用率爆满(超100%),机器就卡死了。
举个例子:text=aaaaa,pattern=/^(a*)b$/,匹配过程大致是
- (a*):匹配到了文本中的aaaaa
- 匹配正则中的b,但是失败,因为(a*)已经把text都吃了
- 这时候引擎会要求(a*)吐出最后一个字符(a),但是无法匹配b
- 第二次是吐出倒数第二个字符(还是a),依然无法匹配
- 就这样引擎会要求(a*)逐个将吃进去的字符都吐出来
- 但是到最后都无法匹配b
这里的重点就在于 引擎会要求*匹配的东西一点一点吐回,我们假设如果文本长度为几万,那引擎就要回溯几万次,这对机器的CPU来说简直是灾难。
有些复杂的正则表达式可能有多个部分都要回溯,那回溯次数就是指数型。如果文本长度为500,一个表达式有两部分都要回溯,那次数可能是500^2=25万次,这谁受得了!
关于更多更详细的回溯介绍,推荐大家可以阅读《精通正则表达式》这本书!
四、优化
编写巧妙的正则表达式不仅仅是一种技能,而且还是一种艺术。
上面我们了解到,绝大多数的编程语言都采用的是NFA引擎,而NFA引擎的特点是:功能强大、但有回溯机制所以效率慢。所以我们需要学习一些NFA引擎的一些优化技巧,以减少引擎回溯次数以及更直接的匹配到结果!
针对NFA引擎的可优化的点其实挺多的,为了方便大家记忆,猪哥也画幅结构图归纳一下,方便大家收藏细看。
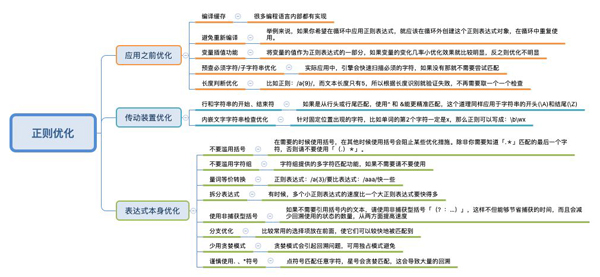
在面试过程中也许会被问到关于正则的优化,大家记住几点就可以。
五、推荐
上面我们讲解了关于正则表达式的诞生和发展、引擎、优化等知识,但是关于正则表达式的知识点远远不止这些,所以最后猪哥推荐一些好的学习资料,大家有空可以了解学习下。
1.书
推荐正则表达式的书,那必然是《精通正则表达式》 ,目前这本书已经出了第三版,豆瓣评分8.9。
内容虽然稍有啰嗦,但是对于正则新手很友好,唯一不足是Python案例少。

2.博客
入门:菜鸟教程:https://www.runoob.com/regexp/regexp-tutorial.html
深入:某不知名大佬:https://blog.csdn.net/lxcnn
3.在线测试工具
https://regex101.com/,这个网站可以选择不同编程语言的正则支持,有语义分析、匹配测试、参考列表等,非常实用。
4.常用案例
一些简单常用的小案例汇总,菜鸟教程:http://c.runoob.com/front-end/854

最后祝愿大家都能搞定正则表达式,处理文本可以得心应手!