1、 YARN的产生
在之前文章中介绍过hadoop1与hadoop2架构的区别是hadoop2将资源管理功能从MapReduce框架中独立出来,也就是现在的YARN模块。
在没有 YARN 之前,是一个集群一个计算框架。比如:MapReduce 一个集群、Spark 一个集群、HBase 一个集群等。
造成各个集群管理复杂,资源的利用率很低;比如:在某个时间段内 Hadoop 集群忙而Spark 集群闲着,反之亦然,各个集群之间不能共享资源造成集群间资源并不能充分利用。
并且采用"一个框架一个集群"的模式,也需要多个管理员管理这些集群, 进而增加运维成本;而共享集群模式通常需要少数管理员即可完成多个框架的统一管理; 随着数据量的暴增,跨集群间的数据移动不仅需要花费更长的时间,且硬件成本也会大大增加;而共享集群模式可让多种框架共享数据和硬件资源,将大大减少数据移动带来的成本。
解决办法:
将所有的计算框架运行在一个集群中,共享一个集群的资源,按需分配;Hadoop 需要资源就将资源分配给 Hadoop,Spark 需要资源就将资源分配给 Spark,进而整个集群中的资源利用率就高于多个小集群的资源利用率;
2、 YARN的基本构成
Master/Slave 结构,1 个ResourceManager(RM)对应多个 NodeManager(NM);YARN 由 Client、ResourceManager、NodeManager、ApplicationMaster (AM)组成;Client 向 RM 提交任务、杀死任务等;
AM由对应的应用程序完成;
每个应用程序对应一个 AM,AM向RM申请资源用于在NM上启动相应的 Task;NM 向 RM通过心跳信息:汇报 NM健康状况、任务执行状况、领取任务等;
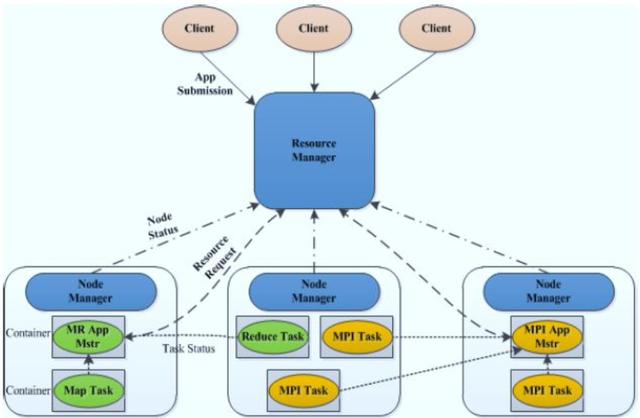
RM:整个集群只有一个,负责集群资源的统一管理和调度
1)处理来自客户端的请求(启动/杀死应用程序);
2)启动/监控 AM;一旦某个 AM 挂了之后,RM 将会在另外一个节点上启动该 AM;
3)监控 NM,接收 NM的心跳汇报信息并分配任务到 NM去执行;一旦某个 NM挂了,标志下该 NM 上的任务,来告诉对应的 AM 如何处理;
4)负责整个集群的资源分配和调度;
NM:整个集群中有多个,负责单节点资源管理和使用
1)周期性向 RM汇报本节点上的资源使用情况和各个 Container 的运行状;
2)接收并处理来自 RM 的 Container 启动/停止的各种命令;
3)处理来自 AM的命令;
4)负责单个节点上的资源管理和任务调度;
AM:每个应用一个,负责应用程序的管理
1)数据切分;
2)为应用程序/作业向 RM 申请资源(Container),并分配给内部任务;
3)与 NM通信以启动/停止任务;
4)任务监控和容错(在任务执行失败时重新为该任务申请资源以重启任务);
5)处理 RM发过来的命令:杀死 Container、让 NM重启等;
Container:对任务运行环境的抽象
1)任务运行资源(节点、内存、CPU);
2)任务启动命令;
3)任务运行环境;任务是运行在Container中,一个Container中既可以运行AM也可以运行具体的 Map/Reduce/MPI/Spark Task;
3、 YARN的工作原理
1)用户向 YARN 中提交应用程序/作业,其中包括 ApplicaitonMaster 程序、启动ApplicationMaster 的命令、用户程序等;
2)ResourceManager 为作业分配第一个 Container,并与对应的 NodeManager 通信,要求它在这个 Containter 中启动该作业的 ApplicationMaster;
3 )ApplicationMaster 首 先 向 ResourceManager 注 册 , 这 样 用 户 可 以 直 接 通 过ResourceManager 查询作业的运行状态;然后它将为各个任务申请资源并监控任务的运行状态,直到运行结束。即重复步骤 4-7;
4)ApplicationMaster 采用轮询的方式通过 RPC 请求向 ResourceManager 申请和领取资源;
5)一旦 ApplicationMaster 申请到资源后,便与对应的 NodeManager 通信,要求它启动任务;
6)NodeManager 启动任务;
7)各个任务通过 RPC 协议向 ApplicationMaster 汇报自己的状态和进度,以让ApplicaitonMaster 随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;在作业运行过程中,用户可随时通过 RPC 向 ApplicationMaster 查询作业当前运行状态;
8)作业完成后,ApplicationMaster 向 ResourceManager 注销并关闭自己;
4、 YARN的容错性
ResourceMananger基于 ZooKeeper 实现 HA 避免单点故障;
NodeManager执行失败后,ResourceManager 将失败任务告诉对应的 ApplicationMaster;
由 ApplicationMaster 决定如何处理失败的任务;
ApplicationMaster执行失败后,由 ResourceManager 负责重启;
ApplicationMaster 需处理内部任务的容错问题;
RMAppMaster 会保存已经运行完成的 Task,重启后无需重新运行。
5、 YARN的调度框架
1、双层调度框架
1)ResourceManager 将资源分配给 ApplicationMaster;
2)ApplicationMaster 将资源进一步分配给各个 TASK;
2、基于资源预留的调度策略
1)资源不够时,会为 Task 预留,直到资源充足;描述:当一个 Task 需要 10G 资源时,各个节点都不足 10G,那么就选择一个节点,但是某个 NodeManager上只有 2G, 那么就在这个 NodeManager上预留, 当这个 NodeManager上释放其他资源后,会将资源预留给 10G 的作业,直到攒够 10G 时,启动 Task;缺点:资源利用率不高,要先攒着,等到 10G 才利用,造成集群的资源利用率低;
2)与"all or nothing"策略不同(Apache Mesos)描述:当一个作业需要 10G 资源时,节点都不足 10G,那就慢慢等,等到某个节点上有 10G 空闲资源时再运行,很可能会导致该 Task 饿死。