












本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
4月9日,英伟达x量子位分享了一期nlp线上课程,来自NVIDIA的GPU计算专家、FasterTransformer 2.0开发者之一的薛博阳老师,与数百位开发者共同探讨了:
- FasterTransformer 2.0 新增功能介绍
- 如何针对Decoder和Decoding进行优化
- 如何使用Decoder和Decoding
- Decoder和Decoding能够带来什么样的加速效果
应读者要求,我们将分享内容整理出来,与大家一起学习。文末附有本次直播回放、PPT链接,大家也可直接观看。
以下为本次分享的内容整理:
大家好,今天为大家介绍的是FasterTransformer 2.0的原理与应用。
什么是FasterTransformer?
首先,参加本期直播的朋友对Transformer架构应该都有了一定了解。这个架构是在“Attention is All You Need”这篇论文中提出的。在BERT Encoder中使用了大量Transformer,效果很好。因此,Transformer已成为 NLP 领域中非常热门的深度学习网络架构。
但是,Transformer计算量通常是非常大的。因此,Transformer的时延往往难以满足实际应用的需求。
△Attention is All You Need截图
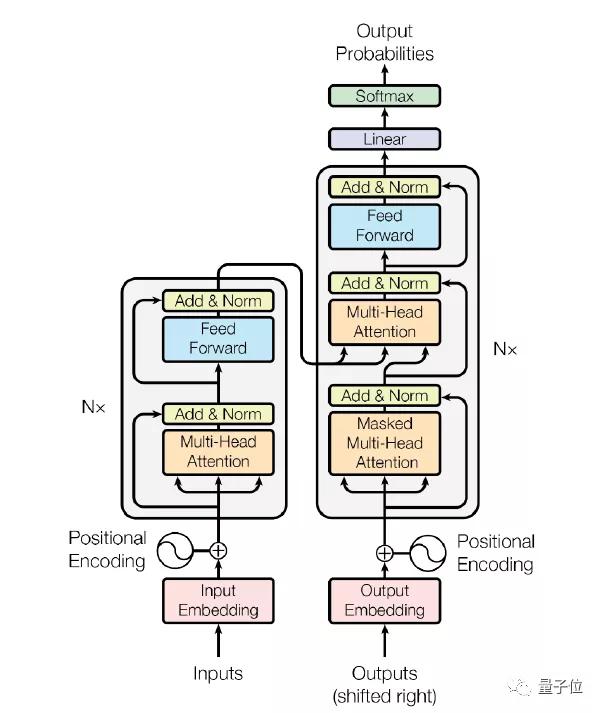
Transformer架构可以应用于Encoder或Decoder上。在Encoder中,Transformer包含1个multi-head attention和1个feed forward网络,在Decoder中,包含2个multi-head attention和1个feed forward网络。
其中,纯Encoder架构在目前的很多应用中都有很好的表现,比如Q&A系统、广告推荐系统等,因此,针对Encoder的优化是非常有必要的。
而在一些场景中,如翻译场景,我们需要Encoder和Decoder架构。在这种架构下,Decoder消耗的时间占比是非常高的,可能达到90%以上,是推理的主要瓶颈。因此,针对Decoder的优化也是一项重要的工作,能带来明显的加速效果。
实际应用中,FasterTransformer 1.0版本针对BERT中的Encoder为目标做了很多优化和加速。在2.0版本中,则主要新增了针对Decoder的优化,其优越的性能将助力于翻译、对话机器人、文字补全修正等多种生成式的场景。

上表比较了Encoder和Decoder计算量的不同。当我们需要编解码一个句子的时候,Encoder可以同时编码很多个字,甚至可以直接编码一个句子。
但是Decoder是一个解码的过程,每次只能解码一个字,因此,解码一个句子时我们需要多次Decoder的forward,对GPU更不友善。
△Faster Transformer框架
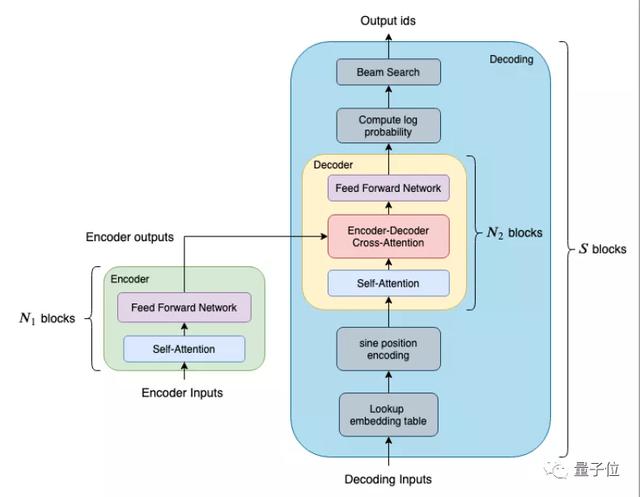
上图列出了FasterTransformer中针对BERT优化的模块。在编码方面,以BERT为基准,提供了一个单层的、等价于BERT Transformer 的模块,供使用者做调用。当我们需要多层的Transformer时,只需调用多次Encoder即可。
解码方面更为复杂,为了兼顾灵活性与效率,我们提供两个不同大小和效果的模块:
Decoder(黄色区块) 由单层的 Transformer layer 组成,它包含两个attention和一个feed forward 网络;而Decoding(蓝色区块)除了包含多层的 Transformer layer 之外,还包括了其他函数,例如 embedding_lookup、beam search、position Encoding 等等。
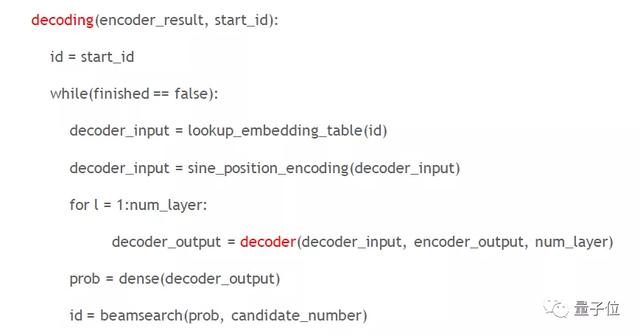
我们用一个简单的虚拟码展示Decoder和Decoding的区别。
在Decoding中通常有两个终止条件,一是是否达到预先设定的最大的sequence length,第二个条件是所有的句子是否都已经翻译完毕,未终止时会不断循环。
以句子长度为128的句子翻译场景为例,若其 Decoder 是由6层的 Transformer layer 组成的,总共需要调用 128x6=768 次的Decoder;如果是使用 Decoding 的话,则只需要调用一次Decoding,因此Decoding的推理效率更高。
小结

首先,FasterTransformer提供了高度优化过的Transformer layer:在Encoder方面是基于BERT实现的;在Decoder方面基于OpenNMT-TensorFlow开源的库做为标准;Decoding包含了翻译的整个流程,也是基于OpenNMT-TensorFlow。
其次,FasterTransformer 2.0的底层由CUDA和cuBLAS实现,支持FP16 和 FP32 两种计算模式,目前提供C++ API和TF OP。
现在,FasterTransformer 2.0已经开源,大家可以在DeepLearningExamples/FasterTransformer/v2 at master · NVIDIA/DeepLearningExamples · GitHub获取全部源代码。
如何进行优化?
先以Encoder为例。
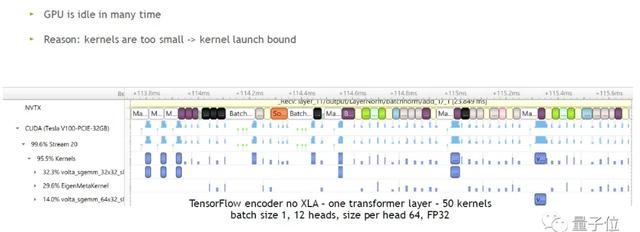
△TF Encoder Transformer layer
参数:no XLA,batch size 1,12 heads,size per head 64,FP 32
图中蓝色方块表示GPU在实际运行,空白的表示GPU在闲置,因此GPU在很多时间是闲置状态。造成GPU闲置的原因是kernels太小,GPU要不断闲置以等待CPU启动kernel的时间,这也称为kernel launch bound问题。
如何解决这个问题?

我们尝试开启TF的XLA,其他参数不变。图中我们看到,从原本计算1层Transformer layer需要50个kernel缩减到24个左右。大部分kernel变得比较宽,虽有加速,但是闲置的时间还是比较多。
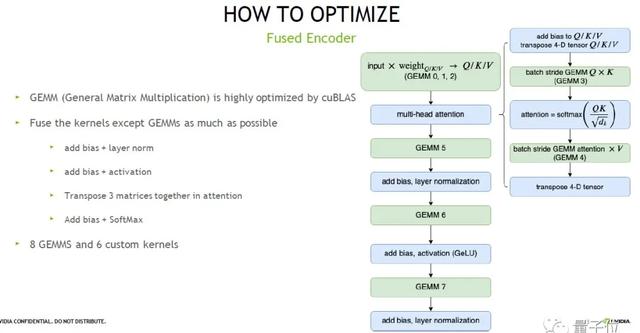
因此,我们提出FasterTransformer针对Encoder进行优化。
首先,我们把矩阵计算部分挑选出来,用NVIDIA高度优化的库cuBLAS 来计算,此外的部分,我们把能融合的kernel都尽可能融合起来。
最终的结果如上图右边,经过整体的优化后,我们只需要8个矩阵计算加6个kernel就可以完成单层Transformer layer计算,也就是说所需kernel从24个减少到14个。
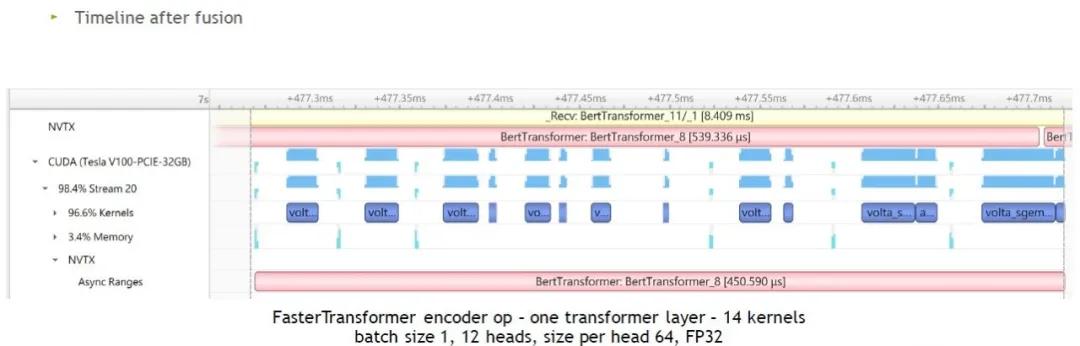
我们可以看到,优化后每一个 kernel 都相对比较大,时间占比小的kernel也减少了。但还是有很多空白的片段。

我们直接调用C++ API,如图,GPU闲置的时间几乎没有了。因此,小batch size情况下,我们推荐使用C++ API以获得更快的速度。当batch size比较大时,GPU闲置时间会比较少。
接下来我们看下Decoder。
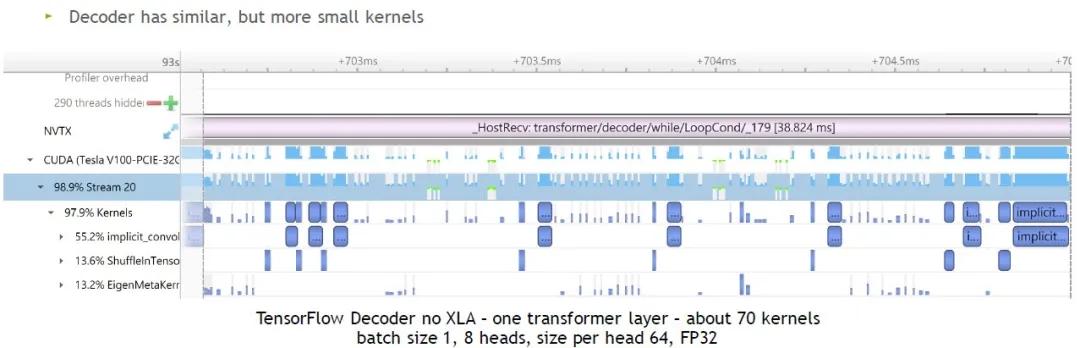
参数:no XLA,batch size 1,8 heads,size per head 64,FP32
经过统计,TF需要使用70个左右kernel来计算1层Transformer layer。直观来看,非常小、时间占比非常短的kernel更多。因此,batch size比较小的情况下,优化效果会更明显。
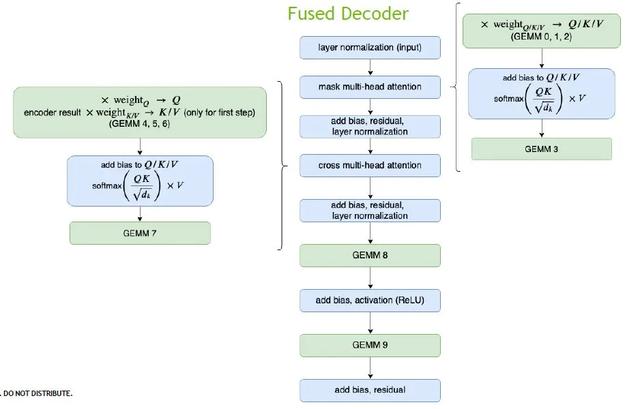
Decoder的优化同上述Encoder,特别之处是,Decoder里面的矩阵计算量非常少,因此我们把整个multi-head attention以一个kernel来完成。经过优化之后,原本需要70个kernel才能完成的计算,只需要使用16个kernel就能够完成。
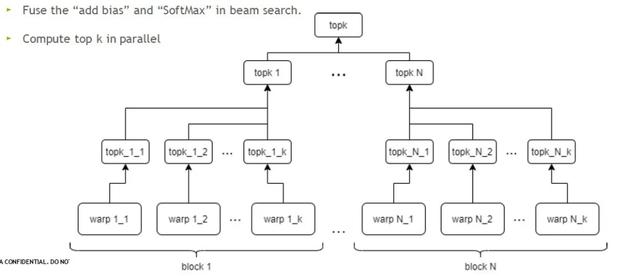
在更大的Decoding模块中,另一个时间占比较多的kernel是beam search,这里我们针对top k做出优化。在GPU中可以同时执行多个block和多个warp,并行运算,大大节省时间。

△更多优化细节
如何使用FasterTransformer?
大家可以在DeepLearningExamples/FasterTransformer/v2 at master · NVIDIA/DeepLearningExamples · GitHub根目录下找到对应资料:

针对 Decoder 和 Decoding,FasterTransformer 分别提供了 C++ 和 TensorFlow OP 这两种接口。
C++接口
首先创建一个Eecoder,超参数如图:

其次,设定训练好的模型权重;
设置好后,直接调用forward即可。
TF OP接口
首先,我们需要先载入OP。这里以Decoder为例,会自动创建TF需要使用的库,调用接口时先导入.so文件(图中已标红):

然后调用Decoder,放入input、权重、超参数,然后针对out put 做Session run。
这里需要注意的是,参数里有一个虚拟的输入 (pseudo input)。这个输入是为了避免 TensorFlow 的 decoder 和 FasterTransformer Decoder 发生并行,因为我们发现并行执行时,Decoder中的memory可能会被污染。实际应用的时候可以将这个输入拿掉。
优化效果
最后我们来看下优化的效果如何。首先测试环境设置:

使用的GPU是NVIDIA的Tesla T4和V100。
Encoder模块在Tesla V100的结果
超参数设置:12 layers,32 sequence length,12 heads,64 size per head(BERT base),under FP 16
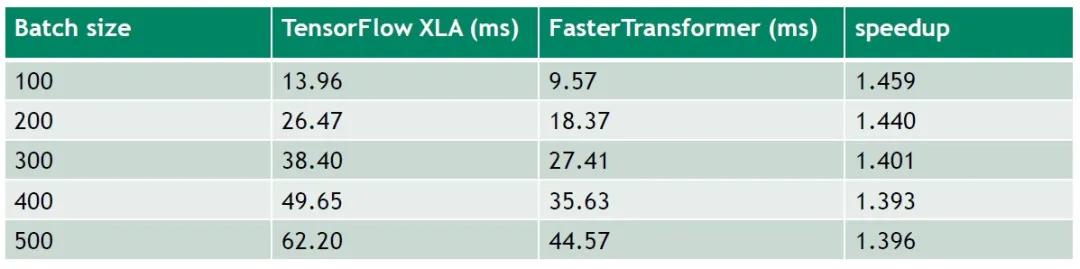
结果如上图,batch size从100逐步增加到500的过程中,FasterTransformer对比TF开启XLA,大概可以提供1.4倍的加速。
Decoder和Decoding模块在Tesla T4的结果
超参数设置:Batch size 1,beam width 4,8 heads,64 size per head,6 layers,vocabulary size 30000,FP 32
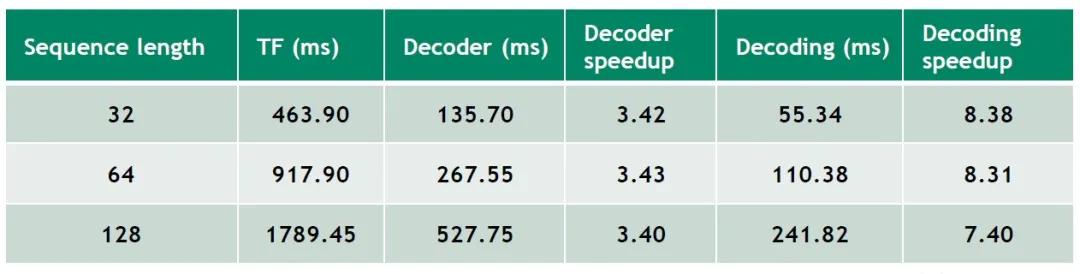
结果如上图,不同的sequence length下,相比于TF,FasterTransformer Decoder可以带来3.4倍左右的加速效果,Decoding可以带来7-8倍的加速,效率更高。
超参数设置:Batch size 256,sequence length 32,beam width 4,8 heads,64 size per head,6 layers,vocabulary size 30000

结果如上图,把batch size固定在较高值时,不同的FP下,FasterTransformer Decoder和Decoding也带来一定的加速效果。


















