之前开源的「人脸变卡通」项目往往可以提供很多鬼畜素材,要么嘴歪眼斜,要么脸型扭曲,甚至让你的五官看上去是随便放到脸盘里的,完全不像阳间该有的画风……但小视科技最近开源的一个项目似乎改变了这种印象,不仅可以生成逼真的卡通头像,还能利用微信小程序做成动图表情包,普通人也可以零门槛上手。
这个项目名叫「人像卡通化 (Photo to Cartoon)」,已经在 GitHub 上开源。但对于不想动手下载各种软件、数据集、训练模型的普通用户,该公司开放了一个名为「AI 卡通秀」的小程序,可以生成各种风格的卡通照片、gif 表情包,完全可以满足社交需求。
先来看一下小程序的生成效果:



看上去好像还不错。但考虑到明星照可能会被用作训练数据,机器之心小编决定用自己的照片试一下:

效果依然传神!而且,除了常规卡通头像之外,你还可以选择生成图像的滤镜和风格,如怀旧、字云、素描、剪纸、豹纹等。
小姐姐能完美转换,那小哥哥呢?我们拿象牙山 F4 之一的谢广坤测试了一下(众所周知,广坤叔的颜值还是很能打的):

由于照片中人物右侧下巴的边界不太明显,生成的卡通头像略有瑕疵,但还是一眼就能看出人物特征。当然,这还不是最欢乐的。接下来,你还可以做表情包!


话说回来,这种需要上传照片的应用常常引发大家对于隐私问题的担忧。有了「Zao」的前车之鉴,「AI 卡通秀」在《用户协议》中表示,「除非为了改善我们为您提供的服务或另行取得您的再次同意,否则我们不会以其他形式或目的使用上述内容(头像照片等)」。

如果你还是担心隐私问题,可以直接去 GitHub 上获取开源数据和代码,训练自己的模型进行测试。
项目地址:https://github.com/minivision-ai/photo2cartoon
接下来,我们就来看看这一应用背后的技术细节。
这么好玩的效果是怎么做到的呢?
人像卡通风格渲染的目标是,在保持原图像 ID 信息和纹理细节的同时,将真实照片转换为卡通风格的非真实感图像。
但是图像卡通化任务面临着一些难题:
- 卡通图像往往有清晰的边缘,平滑的色块和经过简化的纹理,与其他艺术风格有很大区别。使用传统图像处理技术生成的卡通图无法自适应地处理复杂的光照和纹理,效果较差;基于风格迁移的方法无法对细节进行准确地勾勒。
- 数据获取难度大。绘制风格精美且统一的卡通画耗时较多、成本较高,且转换后的卡通画和原照片的脸型及五官形状有差异,因此不构成像素级的成对数据,难以采用基于成对数据的图像翻译(Paired Image Translation)方法。
- 照片卡通化后容易丢失身份信息。基于非成对数据的图像翻译(Unpaired Image Translation)方法中的循环一致性损失(Cycle Loss)无法对输入输出的 id 进行有效约束。
那么如何解决这些问题呢?
小视科技的研究团队提出了一种基于生成对抗网络的卡通化模型,只需少量非成对训练数据,就能获得漂亮的结果。卡通风格渲染网络是该解决方案的核心,它主要由特征提取、特征融合和特征重建三部分组成。
整体框架由下图所示,该框架基于近期研究 U-GAT-IT(论文《U-GAT-IT: Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalization for Image-to-Image Translation》。
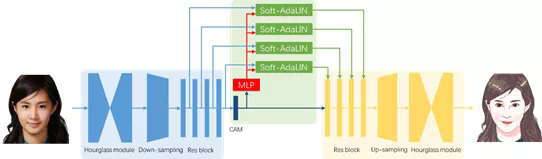
模型结构方面,在 U-GAT-IT 的基础上,研究者在编码器之前和解码器之后各增加了 2 个 hourglass 模块,渐进地提升模型特征抽象和重建能力。
特征提取
特征提取部分包含堆叠的 Hourglass 模块、下采样模块和残差模块。
Hourglass 模块常用于姿态估计,它能够在特征提取的同时保持语义信息位置不变。该方法采用堆叠的 Hourglass 模块,渐进地将输入图像抽象成易于编码的形式。4 个残差模块则用于编码特征并提取统计信息,用于后续的特征融合。
特征融合
近期论文 U-GAT-IT 提出了一种归一化方法——AdaLIN,能够自动调节 Instance Norm 和 Layer Norm 的比重,再结合注意力机制实现人像日漫风格转换。
研究人员基于此提出了 Soft-AdaLIN(Soft Adaptive Layer-Instance Normalization)归一化方法。先将输入图像的编码特征统计信息和卡通特征统计信息融合,再以 AdaLIN 的方式反归一化解码特征,使卡通画结果更好地保持输入图像的语义内容。
不同于原始的 AdaLIN,这里的「Soft」体现在不直接使用卡通特征统计量来反归一化解码特征,而是通过可学习的权重 w_μ 和 w_σ 来加权平均卡通特征和编码特征的统计量,并以此对归一化后的解码特征进行反归一化。
编码特征统计量 μ_en 和 σ_en 提取自特征提取阶段中各 Resblock 的输出特征,卡通特征统计量则通过全连接层提取自 CAM(Class Activation Mapping)模块输出的特征图。加权后的统计量为:
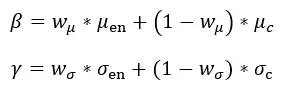
Soft-AdaLIN 操作可以表示为:
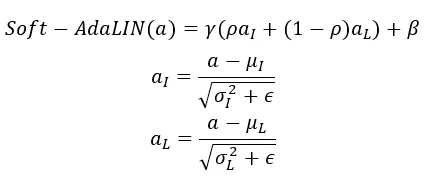
特征重建
特征重建部分负责从编码特征生成对应的卡通图像。
这部分采用与特征提取部分对称的结构,通过解码模块、上采样模块和 Hourglass 模块生成卡通画结果。
损失函数
如上所述,照片卡通化后容易丢失身份信息。为了使输出结果体现人物信息,除了常规的 Cycle Loss 和 GAN Loss,研究人员还引入了 ID Loss:使用预训练的人脸识别模型来提取输入真人照和生成卡通画的 id 特征,并用余弦距离来约束,使卡通画的 id 信息与输入照片尽可能相似。
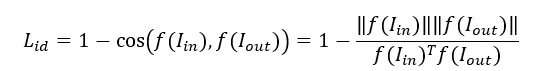
如何实现?
安装依赖库
项目所需的主要依赖库如下:
- python 3.6
- pytorch 1.4
- tensorflow-gpu 1.14
- face-alignment
- dlib
Clone
- git clone https://github.com/minivision-ailab/photo2cartoon.git
- cd ./photo2cartoon
下载资源
资源地址:
- https://drive.google.com/open?id=1eDNGZT3jszHLXQ9XGIUPtcu72HdBmHuX
- https://pan.baidu.com/s/1DxWWBAoaBpsei_rynZUZzw 提取码:z2nm
- 人像卡通化预训练模型:photo2cartoon_weights.pt,存放在 models 路径下。
- 头像分割模型:seg_model_384.pb,存放在 utils 路径下。
- 人脸识别预训练模型:model_mobilefacenet.pth,存放在 models 路径下。(From: InsightFace_Pytorch)
- 卡通画开源数据:cartoon_data,包含 trainB 和 testB。
测试
将一张测试照片(亚洲年轻女性)转换为卡通风格:
- python test.py --photo_path ./images/photo_test.jpg --save_path ./images/cartoon_result.png
训练
1. 数据准备
训练数据包括真实照片和卡通画像,为降低训练复杂度,团队对两类数据进行了如下预处理:
- 检测人脸及关键点。
- 根据关键点旋转校正人脸。
- 将关键点边界框按固定的比例扩张并裁剪出人脸区域。
- 使用人像分割模型将背景置白。

团队开源了 204 张处理后的卡通画数据,用户还需准备约 1000 张人像照片(为匹配卡通数据,尽量使用亚洲年轻女性照片,人脸大小最好超过 200x200 像素),使用以下命令进行预处理:
- python data_process.py --data_path YourPhotoFolderPath --save_path YourSaveFolderPath
将处理后的数据按照以下层级存放,trainA、testA 中存放照片头像数据,trainB、testB 中存放卡通头像数据。
- ├── dataset
- └── photo2cartoon
- ├── trainA
- ├── xxx.jpg
- ├── yyy.png
- └── ...
- ├── trainB
- ├── zzz.jpg
- ├── www.png
- └── ...
- ├── testA
- ├── aaa.jpg
- ├── bbb.png
- └── ...
- └── testB
- ├── ccc.jpg
- ├── ddd.png
- └── ...
2. 训练
重新训练:
- python train.py --dataset photo2cartoon
加载预训练参数:
- python train.py --dataset photo2cartoon --pretrained_weights models/photo2cartoon_weights.pt