本文转自雷锋网,如需转载请至雷锋网官网申请授权。
本文是对 ICLR 2020 论文《NEURAL TANGENTS: FAST AND EASY INFINITE NEURAL NETWORKS IN PYTHON》的解读,作者来自谷歌。

-
论文地址:https://arxiv.org/pdf/1912.02803.pdf
-
开源地址:https://github.com/google/neural-tangents
深度学习在自然语言处理,对话智能体和连接组学等多个领域都获得了成功应用,这种学习方式已经改变了机器学习的研究格局,并给研究人员带来了许多有趣而重要的开放性问题,例如:为什么深度神经网络(DNN)在被过度参数化的情况下仍能如此良好地泛化? 深度网络的体系结构、训练和性能之间的关系是什么? 如何从深度学习模型中提取显著特征?
近年来,该领域取得进展的一个关键理论观点是:增加 DNN 的宽度会带来更有规律的行为,并使这些行为更易于理解。最近的许多结果表明,能够变得无限宽的DNN聚合到另一种更简单的模型类别上的过程,称为高斯过程。
在这一限制下,复杂的现象(如贝叶斯推理或卷积神经网络的梯度下降动力学)可以归结为简单的线性代数方程。这些无限宽网络的一些思路,也被频繁地扩展到有限的网络上。 因此,无限宽网络不仅可以用作研究深度学习的维度,其本身也是非常有用的模型。
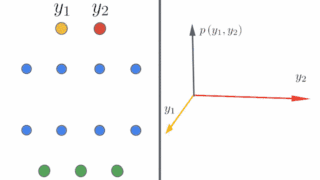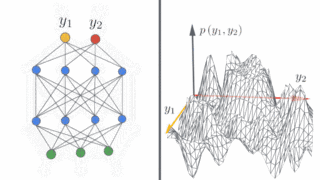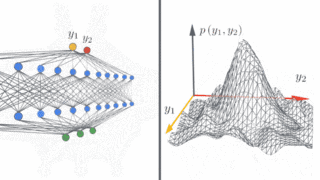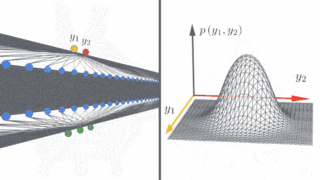
左图:示意图显示了深度神经网络在无限宽的情况下如何产生简单的输入/输出映射。
右图:随着神经网络宽度的增加,我们看到网络在不同的随机实例上的输出分布变为高斯分布。
不幸的是,推导有限网络的无限宽度限制需要大量的数学知识,并且必须针对研究的每种体系结构分别进行计算。一旦无限宽的模型被推导出来,想进一步提出一个有效的和可扩展的实现还需要很高的工程能力。总之,将有限宽的模型转换成相应的无限宽网络的过程可能需要几个月的时间,并且可能它本身就是研究论文的主题。
为了解决这个问题,并加速深度学习的理论进展,谷歌研究者提出了一种新的开源软件库“神经正切”(Neural Tangents),允许研究人员像训练有限宽的神经网络一样容易地构建和训练无限宽的神经网络。其核心是:神经正切提供了一个易于使用的神经网络库,可以同时构建有限和无限宽的神经网络。
先举个神经切线的应用示例,想象一下在某些数据上训练一个完全连接的神经网络。 通常,神经网络是随机初始化的,然后使用梯度下降进行训练。对这些神经网络进行初始化和训练可以得到一个集成网络。
研究人员和从业人员通常会把集成的不同部分的预测情况平均,以获得更好的表现。另外,可以从集成的不同部分预测的方差中估计其不确定性。这种方法的缺点是,训练一个网络集成需要大量的计算预算,因此很少使用这种方法。但是,当神经网络变得无限宽时,通过高斯过程描述该集成,它的均值和方差在整个训练过程中便能被计算出来。
使用神经正切,只需五行代码就可以构造和训练这些无限宽网络集成! 训练过程如下所示,可以前往以下地址使用进行此实验的交互式协作notebook :
https://colab.sandbox.google.com/github/google/neural-tangents/blob/master/notebooks/neural_tangents_cookbook.ipynb
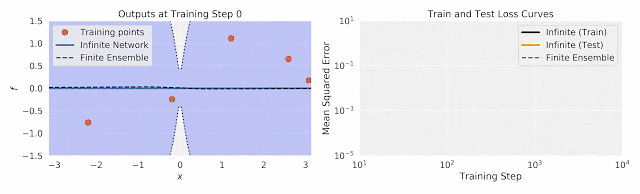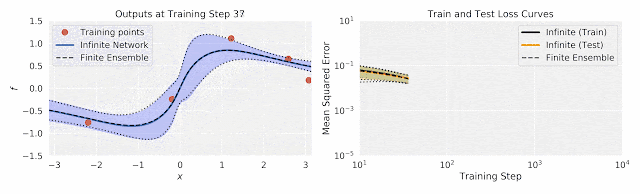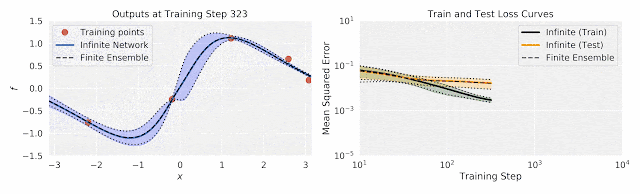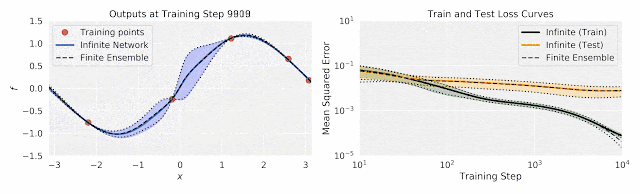
在这两个图中,作者将有限神经网络集成的训练与相同结构的无限宽度集成进行了比较。前者的经验均值和方差用两条浅黑色虚线之间的黑色虚线表示;后者的闭合形式的均值和方差由填充颜色区域内的彩色线表示。在这两个图中,有限宽和无限宽的网络集成非常接近,乃至于难以区分。 左:随着训练的进行,在输入数据(水平x轴)上输出(垂直f轴)。 右图:训练过程中由于不确定因素而导致的训练和测试损失。
尽管无限宽网络集成是由一个简单的闭式表达控制的,但它与有限宽网络集成有显著的一致性。而且由于无限宽网络集成是一个高斯过程,它自然提供了闭合形式的不确定性估计(上图中的彩色区域)。这些不确定性估计与预测变化非常匹配:训练有限宽网络的大量不同的副本时观察到的结果(虚线)。
上述示例显示了无限宽神经网络在捕捉训练动态方面的能力。 然而,使用神经正切构建的网络可以应用于任何问题,即可以应用一个常规的神经网络来解决这些问题。
例如,下面将使用CIFAR-10数据集来比较图像识别上的三种不同的无限宽神经网络架构。 值得注意的是,谷歌研究者可以在梯度下降和全贝叶斯推理(有限宽网络机制中的一项艰巨任务)下,对高度复杂的模型进行评估,例如闭合形式的无限宽残差网络。
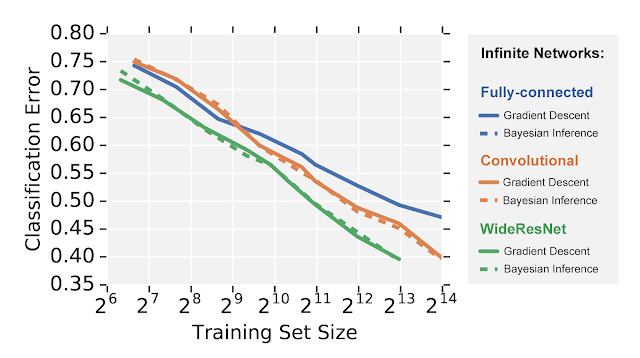
我们可以看到,无限宽网络模仿有限宽神经网络,其性能等级与性能比卷积网络更差的全连接网络相似,而卷积网络的性能又比宽残差网络差。
然而,与常规训练不同的是,这些模型的学习动态是完全可以在闭合形式下进行处理的,这使研究者们对这些模型的行为有了前所未有的了解。 雷锋网雷锋网雷锋网(公众号:雷锋网)
via https://ai.googleblog.com/2020/03/fast-and-easy-infinitely-wide-networks.html