读时模式和写时模式
Hive使用Hadoop来执行查询,其查询执行速度是很慢的,但是使用load data向Hive中导入数据却非常快,这是因为Hive采取的是读时模式(Schema On Read)。
- 读时模式:读取数据的时候,对数据的类型、格式做检查;
- 写时模式:写入数据的时候,对数据的类型、格式等规范做检查;
将数据存到Hive的数据表时,Hive采用的是“读时模式”,意思是针对写操作不会做任何校验,只是简单的将文件复制到Hive的表对应的HDFS目录。跟“读时模式”相对应的是“写时模式”,RDBMS一般采用“写时模式”,在将数据写入到数据表的时候会检查每一条记录是否合法,如果检查不通过会直接返回失败信息。
由于向Hive中存入数据的只是简单的文件复制和粘贴,所以导入数据速度非常的快。当读取、查询的时候,才会根据表模式来解释数据,这个时候如果遇到了不符合模式的数据,Hive会直接将数据解析成NULL。
读时模式的好处
Hive采用读时模式带来了以下几个好处:
- 向Hive表中新增数据非常的快,通常情况下对于外来数据,采用的方法是直接用Hadoop命令将文件上传到一个HDFS目录,Hive直接读这个目录;
- 一份数据可以被解析成多种模式,存储在Hive表中的数据跟Hive本身没有关系,数据也可以被其他工具比如Pig来处理;
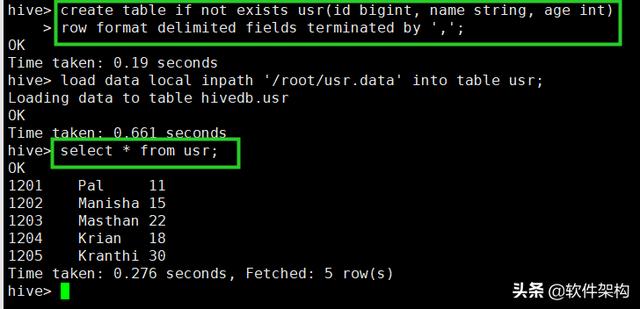
导入数据
- hive> load data local inpath '/root/usr.data' into table usr;