在数据科学世界,Python 是一个不可忽视的存在,且有愈演愈烈之势。而其中主要的使用工具,包括 Numpy、Pandas 和 Scikit-learn 等。 Mars 在 MaxCompute 团队内部诞生,本文将分享如何通过 Mars 让 Numpy、pandas 和 scikit-learn 等数据科学的库能够并行和分布式执行,并和 RAPIDS 平台结合用 GPU 来加速数据科学。
Numpy
Numpy 是数值计算的基础包,内部提供了多维数组(ndarray)这样一个数据结构,用户可以很方便地在任意维度上进行数值计算。
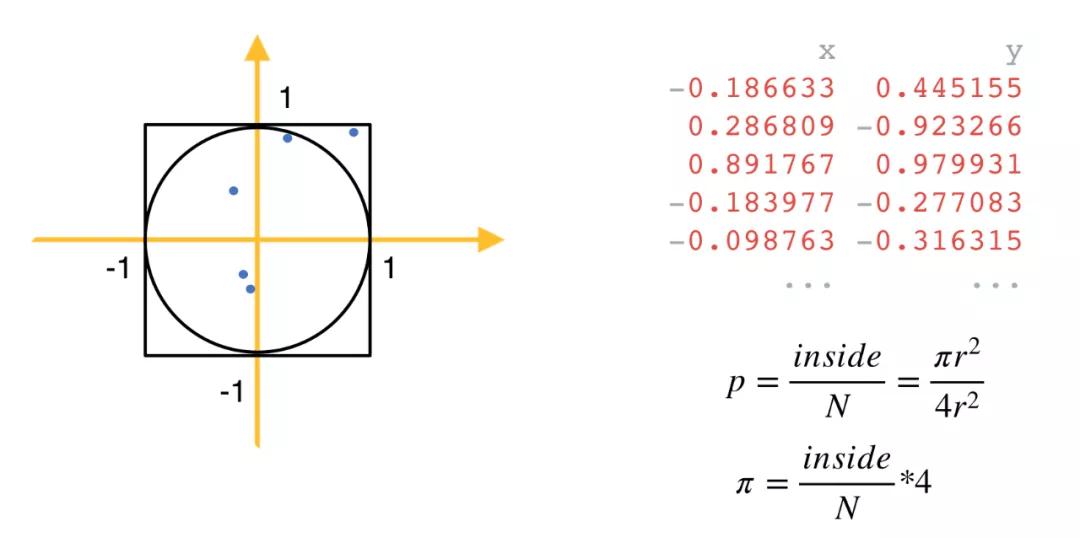
我们举一个蒙特卡洛方法求解 Pi 的例子。这背后的原理非常简单,现在我们有个半径为1的圆和边长为2的正方形,他们的中心都在原点。现在我们生成大量的均匀分布的点,让这些点落在正方形内,通过简单的推导,我们就可以知道,Pi 的值 = 落在圆内的点的个数 / 点的总数 * 4。
这里要注意,就是随机生成的点的个数越多,结果越精确。
用 Numpy 实现如下:
可以看到,用 Numpy 来进行数值计算非常简单,只要寥寥数行代码,而如果读者习惯了 Numpy 这种面相数组的思维方式之后,无论是代码的可读性还是执行效率都会有巨大提升。
pandas
pandas 是一个强大的数据分析和处理的工具,它其中包含了海量的 API 来帮助用户在二维数据(DataFrame)上进行分析和处理。
pandas 中的一个核心数据结构就是 DataFrame,它可以简单理解成表数据,但不同的是,它在行和列上都包含索引(Index),要注意这里不同于数据库的索引的概念,它的索引可以这么理解:当从行看 DataFrame 时,我们可以把 DataFrame 看成行索引到行数据的这么一个字典,通过行索引,可以很方便地选中一行数据;列也同理。
我们拿 movielens 的数据集 作为简单的例子,来看 pandas 是如何使用的。这里我们用的是 Movielens 20M Dataset.
通过一行简单的 pandas.read_csv 就可以读取 CSV 数据,接着按 userId 做分组聚合,求 rating 这列在每组的总和、平均、最大、最小值。
“食用“ pandas 的最佳方式,还是在 Jupyter notebook 里,以交互式的方式来分析数据,这种体验会让你不由感叹:人生苦短,我用 xx(😉)
scikit-learn
scikit-learn 是一个 Python 机器学习包,提供了大量机器学习算法,用户不需要知道算法的细节,只要通过几个简单的 high-level 接口就可以完成机器学习任务。当然现在很多算法都使用深度学习,但 scikit-learn 依然能作为基础机器学习库来串联整个流程。
我们以 K-最邻近算法为例,来看看用 scikit-learn 如何完成这个任务。
fit 接口就是 scikit-learn 里最常用的用来学习的接口。可以看到整个过程非常简单易懂。
Mars —— Numpy、pandas 和 scikit-learn 的并行和分布式加速器
Python 数据科学栈非常强大,但它们有如下几个问题:
- 现在是多核时代,这几个库里鲜有操作能利用得上多核的能力。
- 随着深度学习的流行,用来加速数据科学的新的硬件层出不穷,这其中最常见的就是 GPU,在深度学习前序流程中进行数据处理,我们是不是也能用上 GPU 来加速呢?
- 这几个库的操作都是命令式的(imperative),和命令式相对应的就是声明式(declarative)。命令式的更关心 how to do,每一个操作都会立即得到结果,方便对结果进行探索,优点是很灵活;缺点则是中间过程可能占用大量内存,不能及时释放,而且每个操作之间就被割裂了,没有办法做算子融合来提升性能;那相对应的声明式就刚好相反,它更关心 what to do,它只关心结果是什么,中间怎么做并没有这么关心,典型的声明式像 SQL、TensorFlow 1.x,声明式可以等用户真正需要结果的时候才去执行,也就是 lazy evaluation,这中间过程就可以做大量的优化,因此性能上也会有更好的表现,缺点自然也就是命令式的优点,它不够灵活,调试起来比较困难。
为了解决这几个问题,Mars 被我们开发出来,Mars 在 MaxCompute 团队内部诞生,它的主要目标就是让 Numpy、pandas 和 scikit-learn 等数据科学的库能够并行和分布式执行,充分利用多核和新的硬件。
Mars 的开发过程中,我们核心关注的几点包括:
- 我们希望 Mars 足够简单,只要会用 Numpy、pandas 或 scikit-learn 就会用 Mars。
- 避免重复造轮子,我们希望能利用到这些库已有的成果,只需要能让他们被调度到多核/多机上即可。
- 声明式和命令式兼得,用户可以在这两者之间自由选择,灵活度和性能兼而有之。
- 足够健壮,生产可用,能应付各种 failover 的情况。
当然这些是我们的目标,也是我们一直努力的方向。
Mars tensor:Numpy 的并行和分布式加速器
上面说过,我们的目标之一是,只要会用 Numpy 等数据科学包,就会用 Mars。我们直接来看代码,还是以蒙特卡洛为例。变成 Mars 的代码是什么样子呢?
可以看到,区别就只有两处:import numpy as np 变成 import mars.tensor as mt ,后续的 np. 都变成 mt. ;pi 在打印之前调用了一下 .execute() 方法。
也就是默认情况下,Mars 会按照声明式的方式,代码本身移植的代价极低,而在真正需要一个数据的时候,通过 .execute() 去触发执行。这样能最大限度得优化性能,以及减少中间过程内存消耗。
这里,我们还将数据的规模扩大了 1000 倍,来到了 100 亿个点。之前 1/1000 的数据量的时候,在我的笔记本上需要 757ms;而现在数据扩大一千倍,光 data 就需要 150G 的内存,这用 Numpy 本身根本无法完成。而使用 Mars,计算时间只需要 3min 44s,而峰值内存只需要 1G 左右。假设我们认为内存无限大,Numpy 需要的时间也就是之前的 1000 倍,大概是 12min 多,可以看到 Mars 充分利用了多核的能力,并且通过声明式的方式,极大减少了中间内存占用。
前面说到,我们试图让声明式和命令式兼得,而使用命令式的风格,只需要在代码的开始配置一个选项即可。
Mars DataFrame:pandas 的并行和分布式加速器
看过怎么样轻松把 Numpy 代码迁移到 Mars tensor ,想必读者也知道怎么迁移 pandas 代码了,同样也只有两个区别。我们还是以 movielens 的代码为例。
Mars Learn:scikit-learn 的并行和分布式加速器
Mars Learn 也同理,这里就不做过多阐述了。但目前 Mars learn 支持的 scikit-learn 算法还不多,我们也在努力移植的过程中,这需要大量的人力和时间,欢迎感兴趣的同学一起参与。
这里要注意的是,对于机器学习的 fit、predict 等高层接口,Mars Learn 也会立即触发执行,以保证语义的正确性。
RAPIDS:GPU 上的数据科学
相信细心的观众已经发现,GPU 好像没有被提到。不要着急,这就要说到 RAPIDS。
在之前,虽然 CUDA 已经将 GPU 编程的门槛降到相当低的一个程度了,但对于数据科学家们来说,在 GPU 上处理 Numpy、pandas 等能处理的数据无异于天方夜谭。幸运的是,NVIDIA 开源了 RAPIDS 数据科学平台,它和 Mars 的部分思想高度一致,即使用简单的 import 替换,就可以将 Numpy、pandas 和 scikit-learn 的代码移植到 GPU 上。
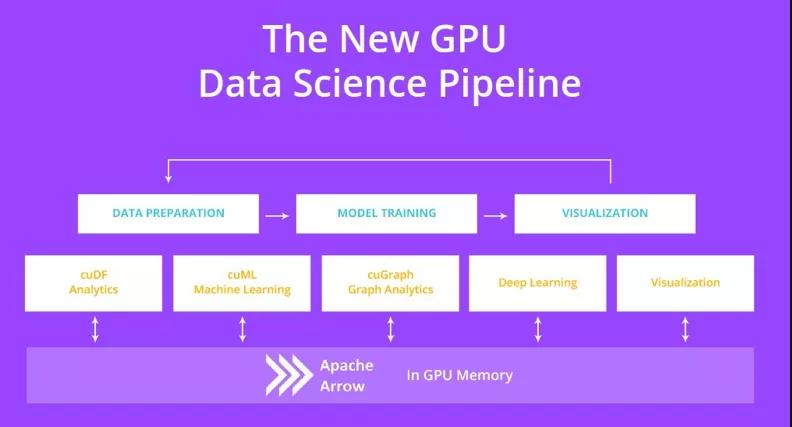
其中,RAPIDS cuDF 用来加速 pandas,而 RAPIDS cuML 用来加速 scikit-learn。
对于 Numpy 来说,CuPy 已经很好地支持用 GPU 来加速了,这样 RAPIDS 也得以把重心放在数据科学的其他部分。
CuPy:用 GPU 加速 Numpy
还是蒙特卡洛求解 Pi。
在我的测试中,它将 CPU 的 757ms,降到只有 36ms,提升超过 20 倍,可以说效果非常显著。这正是得益于 GPU 非常适合计算密集型的任务。
RAPIDS cuDF:用 GPU 加速 pandas
将 import pandas as pd 替换成 import cudf,GPU 内部如何并行,CUDA 编程这些概念,用户都不再需要关心。
运行时间从 CPU 上的 18s 提升到 GPU 上的 1.66s,提升超过 10 倍。
RAPIDS cuML:用 GPU 加速 scikit-learn
同样是 k-最邻近问题。
运行时间从 CPU 上 1min52s,提升到 GPU 上 17.8s。
Mars 和 RAPIDS 结合能带来什么?
RAPIDS 将 Python 数据科学带到了 GPU,极大地提升了数据科学的运行效率。它们和 Numpy 等一样,是命令式的。通过和 Mars 结合,中间过程将会使用更少的内存,这使得数据处理量更大;Mars 也可以将计算分散到多机多卡,以提升数据规模和计算效率。
在 Mars 里使用 GPU 也很简单,只需要在对应函数上指定 gpu=True。例如创建 tensor、读取 CSV 文件等都适用。
下图是用 Mars 分别在 Scale up 和 Scale out 两个维度上加速蒙特卡洛计算 Pi 这个任务。一般来说,我们要加速一个数据科学任务,可以有这两种方式,Scale up 是指可以使用更好的硬件,比如用更好的 CPU、更大的内存、使用 GPU 替代 CPU等;Scale out 就是指用更多的机器,用分布式的方式提升效率。
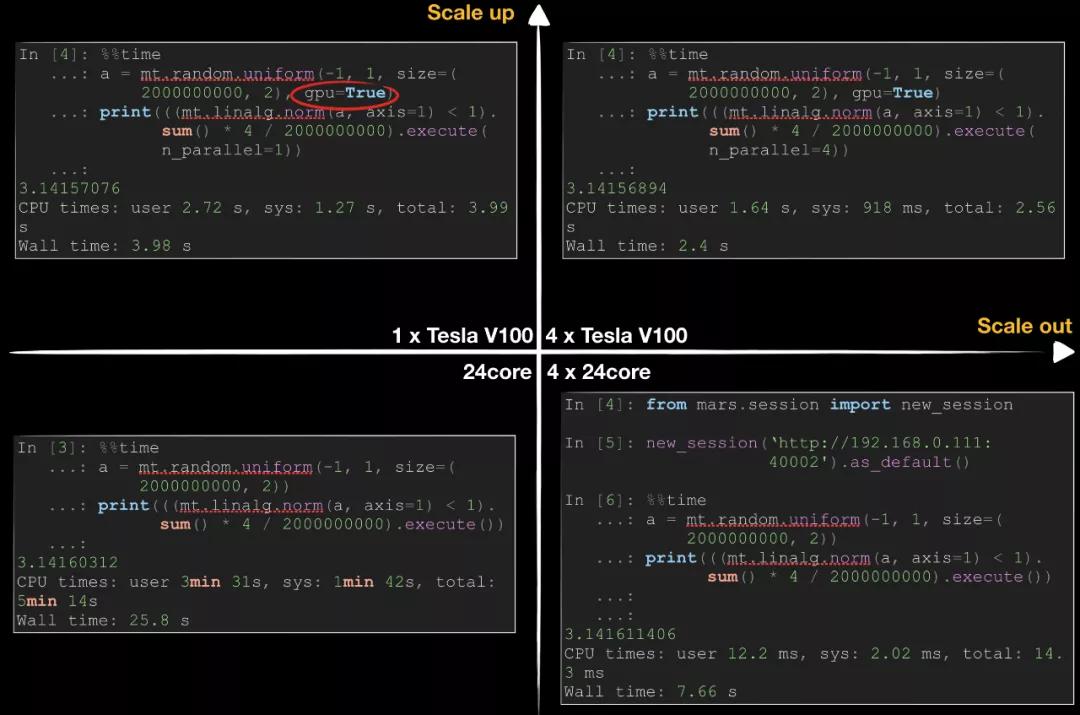
可以看到在一台 24 核的机器上,Mars 计算需要 25.8s,而通过分布式的方式,使用 4 台 24 核的机器的机器几乎以线性的时间提升。而通过使用一个 NVIDIA TESLA V100 显卡,我们就能将单机的运行时间提升到 3.98s,这已经超越了4台 CPU 机器的性能。通过再将单卡拓展到多卡,时间进一步降低,但这里也可以看到,时间上很难再线性扩展了,这是因为 GPU 的运行速度提升巨大,这个时候网络、数据拷贝等的开销就变得明显。
性能测试
我们使用了 https://github.com/h2oai/db-benchmark 的数据集,测试了三个数据规模的 groupby 和 一个数据规模的 join。而我们主要对比了 pandas 和 DASK。DASK 和 Mars 的初衷很类似,也是试图并行和分布式化 Python 数据科学,但它们的设计、实现、分布式都存在较多差异,这个后续我们再撰文进行详细对比。
测试机器配置是 500G 内存、96 核、NVIDIA V100 显卡。Mars 和 DASK 在 GPU 上都使用 RAPIDS 执行计算。
Groupby
数据有三个规模,分别是 500M、5G 和 20G。
查询也有三组。
查询一:
查询二:
查询三:
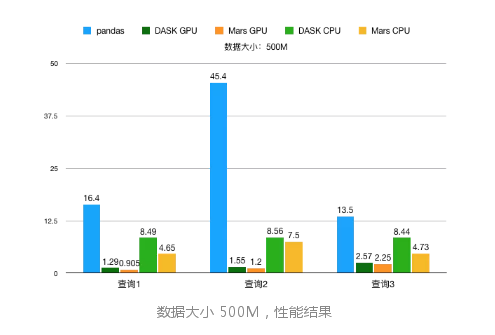
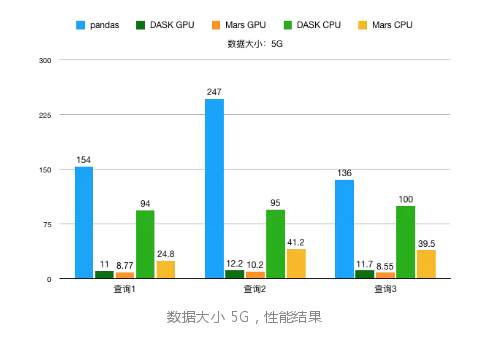
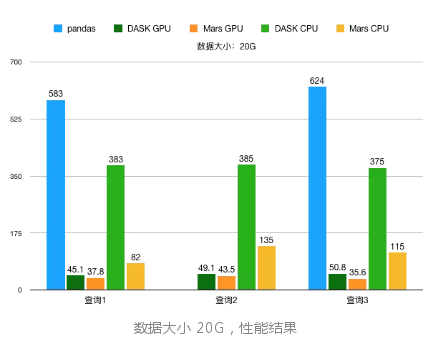
数据大小到 20G 时,pandas 在查询2会内存溢出,得不出结果。
可以看到,随着数据增加,Mars 的性能优势会愈发明显。
得益于 GPU 的计算能力,GPU 运算性能相比于 CPU 都有数倍的提升。如果单纯使用 RAPIDS cuDF,由于显存大小的限制,数据来到 5G 都难以完成,而由于 Mars 的声明式的特点,中间过程对显存的使用大幅得到优化,所以整组测试来到 20G 都能轻松完成。这正是 Mars + RAPIDS 所能发挥的威力。
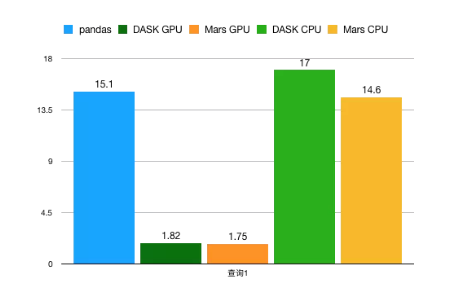
Join
测试查询:
测试数据 x 为 500M,y 包含 10 行数据。
总结
RAPIDS 将 Python 数据科学带到了 GPU,极大提升了数据分析和处理的效率。Mars 的注意力更多放在并行和分布式。相信这两者的结合,在未来会有更多的想象空间。
【本文为51CTO专栏作者“阿里巴巴官方技术”原创稿件,转载请联系原作者】