大数据处理的新趋势,流处理和批处理是非常重要的两个概念,而基于流处理和批处理的大数据处理框架,Flink和Spark,也是常常被大家拿来做比较的对象。而在实时流数据处理上,Flink性能似乎更加强劲,那么Flink为什么比Spark快呢,今天我们就来聊聊这个话题。
Spark和Flink都是针对于实时数据处理的框架,并且两者也都在实际的工作当中表现出色,但是如果要深究两者在大数据处理的区别,我们需要从Spark和Flink的引擎技术开始讲起。
Spark和Flink计算引擎,在处理大规模数据上,数据模型和处理模型有很大的差别。
Spark的数据模型是弹性分布式数据集RDD(Resilient Distributed Datasets)。RDD可以实现为分布式共享内存或者完全虚拟化(即有的中间结果RDD当下游处理完全在本地时可以直接优化省略掉)。这样可以省掉很多不必要的I/O,是早期Spark性能优势的主要原因。
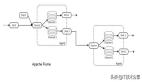
Spark用RDD上的变换(算子)来描述数据处理。每个算子(如map,filter,join)生成一个新的RDD。所有的算子组成一个有向无环图(DAG)。这就是Spark进行数据处理的核心机制。
而Flink的基本数据模型,则是数据流,及事件(Event)的序列。数据流作为数据的基本模型,这个流可以是无边界的无限流,即一般意义上的流处理。也可以是有边界的有限流,这样就是批处理。
Flink用数据流上的变换(算子)来描述数据处理。每个算子生成一个新的数据流。在算子,DAG,和上下游算子链接(chaining)这些方面,和Spark的基本思路是一样的。
但是在在DAG的执行上,Spark和Flink有明显的不同。
在Flink的流执行模式中,一个事件在一个节点处理完后的输出就可以发到下一个节点立即处理。这样执行引擎并不会引入额外的延迟。而Spark的micro batch和一般的batch执行一样,处理完上游的stage得到输出之后才开始下游的stage。
这也就是Flink为什么比Spark快的原因之一。并且Flink在数据流计算执行时,还可以把多个事件一起进行传输和计算,进一步实现数据计算的低延迟。所以Flink之所以快,其实也可以理解为比Spark的延迟性更低。