












EfficientDet 难复现,复现即趟坑。在此 Github 项目中,开发者 zylo117 开源了 PyTorch 版本的 EfficientDet,速度比原版高 20 余倍。如今,该项目已经登上 Github Trending 热榜。

去年 11 月份,谷歌大脑提出兼顾准确率和模型效率的新型目标检测器 EfficientDet,实现了新的 SOTA 结果。前不久,该团队开源了 EfficientDet 的 TensorFlow 实现代码。
如此高效的 EfficientDet 还能更高效吗?最近,有开发者在 GitHub 上开源了「PyTorch 版本的 EfficientDet」。该版本的性能接近原版,但速度是官方 TensorFlow 实现的近 26 倍!
目前,该项目在 GitHub 上获得了 957 颗星,最近一天的收藏量接近 300。
GitHub 地址:https://github.com/zylo117
EfficientDet 简介
近年来,在面对广泛的资源约束时(如 3B 到 300B FLOPS),构建兼具准确率和效率的可扩展检测架构成为优化目标检测器的重要问题。基于单阶段检测器范式,谷歌大脑团队的研究者查看了主干网络、特征融合和边界框/类别预测网络的设计选择,发现了两大主要挑战并提出了相应的解决方法:
挑战 1:高效的多尺度特征融合。研究者提出一种简单高效的加权双向特征金字塔网络(BiFPN),该模型引入了可学习的权重来学习不同输入特征的重要性,同时重复应用自上而下和自下而上的多尺度特征融合。
挑战 2:模型缩放。受近期研究的启发,研究者提出一种目标检测器复合缩放方法,即统一扩大所有主干网络、特征网络、边界框/类别预测网络的分辨率/深度/宽度。
谷歌大脑团队的研究者发现,EfficientNets 的效率超过之前常用的主干网络。于是研究者将 EfficientNet 主干网络和 BiFPN、复合缩放结合起来,开发出新型目标检测器 EfficientDet,其准确率优于之前的目标检测器,同时参数量和 FLOPS 比它们少了一个数量级。
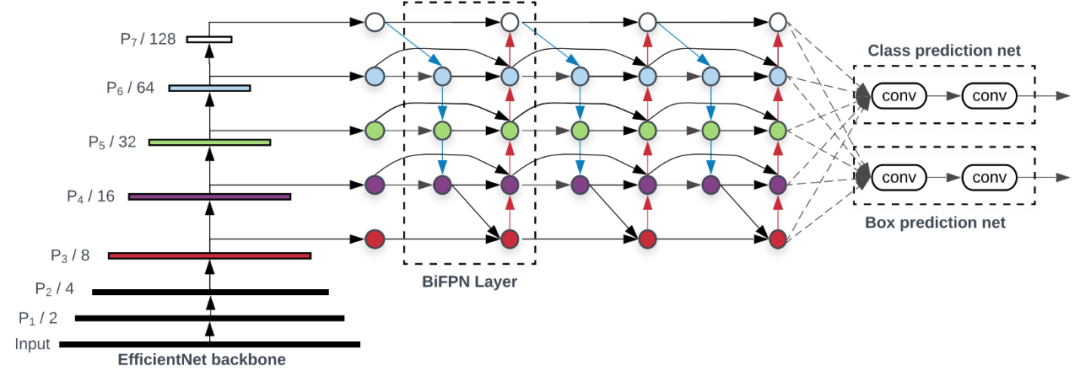
下图展示了 EfficientDet 的整体架构,大致遵循单阶段检测器范式。谷歌大脑团队的研究者将在 ImageNet 数据集上预训练的 EfficientNet 作为主干网络,将 BiFPN 作为特征网络,接受来自主干网络的 level 3-7 特征 {P3, P4, P5, P6, P7},并重复应用自上而下和自下而上的双向特征融合。然后将融合后的特征输入边界框/类别预测网络,分别输出目标类别和边界框预测结果。
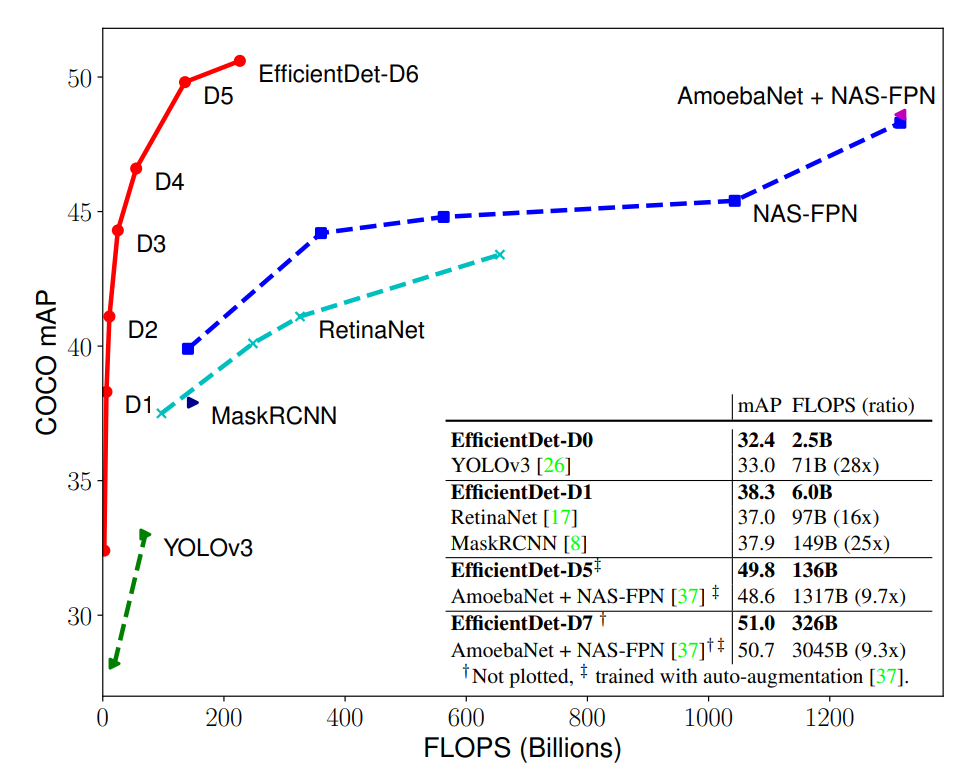
下图展示了多个模型在 COCO 数据集上的性能对比情况。在类似的准确率限制下,EfficientDet 的 FLOPS 仅为 YOLOv3 的 1/28、RetinaNet 的 1/30、NASFPN 的 1/19,所有数字均为单个模型在单一尺度下所得。可以看到,EfficientDet 的计算量较其他检测器少,但准确率优于后者,其中 EfficientDet-D7 获得了当前最优性能。
更详细的介绍,可参见机器之心文章:比当前 SOTA 小 4 倍、计算量少 9 倍,谷歌最新目标检测器 EfficientDet
「宅」是第一生产力
项目作者今年 1 月宅家为国出力时,开始陆续尝试各类 EfficientDet PyTorch 版实现,期间趟过了不少坑,也流过几把辛酸泪。但最终得出了非常不错的效果,也是全网第一个跑出接近论文成绩的 PyTorch 版。
我们先来看一下项目作者与 EfficientDet 官方提供代码的测试效果对比。第一张图为官方代码的检测效果,第二张为项目作者的检测效果。项目作者的实现竟然透过汽车的前挡风玻璃检测出了车辆里面的人?!!这样惊艳的检测效果不愧是目前 EfficientDet 的霸榜存在。

接下来我们来看一下 coco 数据集上目标检测算法的排名,多个屠榜的目标检测网络基于 EfficientDet 构建。一图以言之:
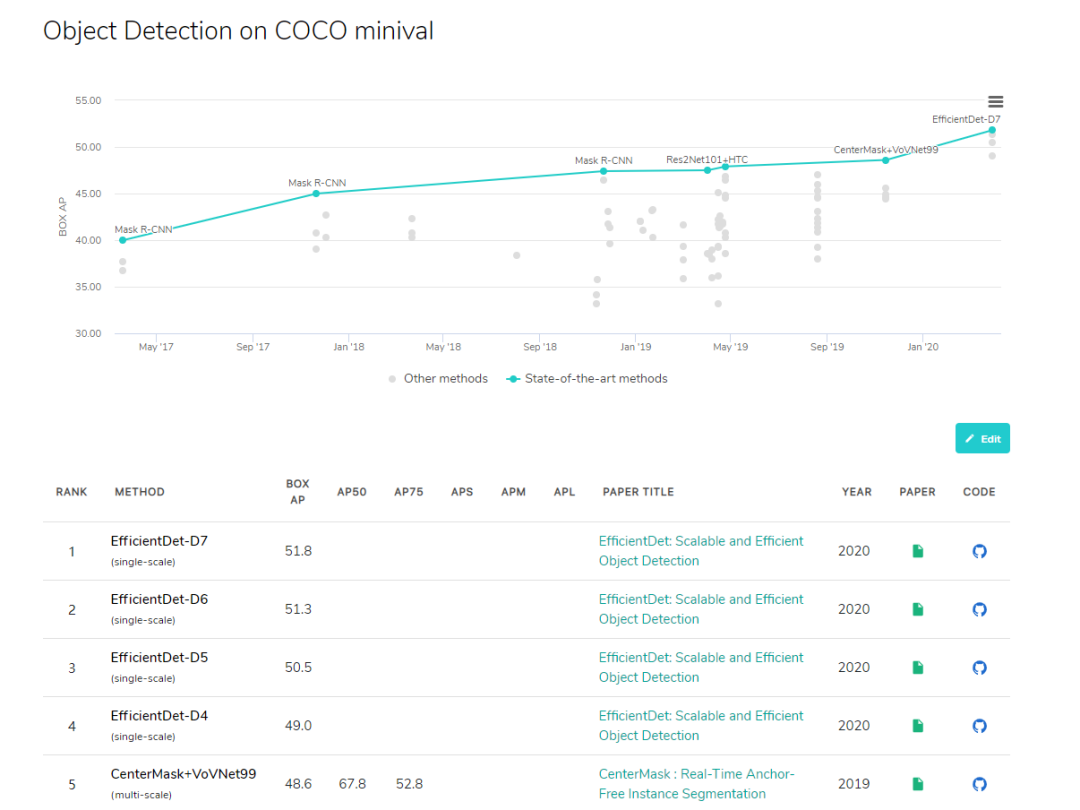
来自 paperswithcode
前五里包揽前四,屠榜之势不言而喻,也难怪各类炼金术士们跃跃欲试。但是,EfficientDet 的实现难度貌似与其知名度「成正比」,众炼金师纷纷表示「难训练」「至今未训练好」「谁复现谁被坑」。项目作者也表示「由于谷歌一直不发官方 repository,所以只能民间发力,那些靠 paper 的内容实现出来的真的不容易」。
假期三天,拿下 PyTorch 版 EfficientDet D0 到 D7
项目作者复现结果与论文中并没完全一致,但相较于其他同类复现项目来说,称的上是非常接近了(详细信息可参考项目链接)。
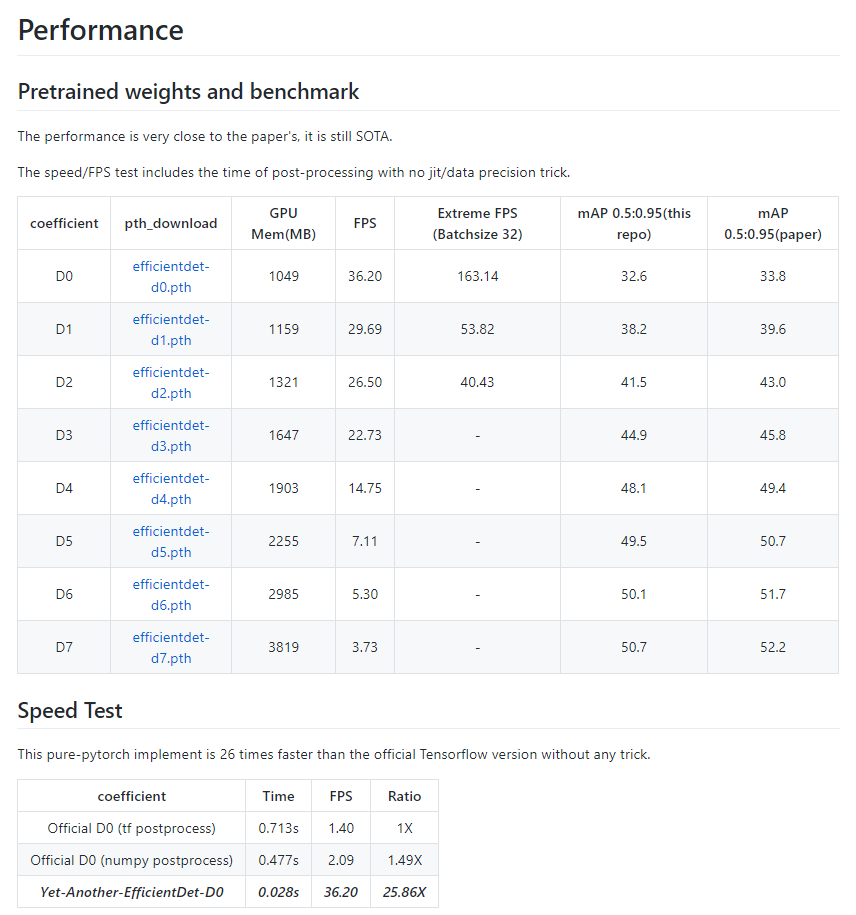
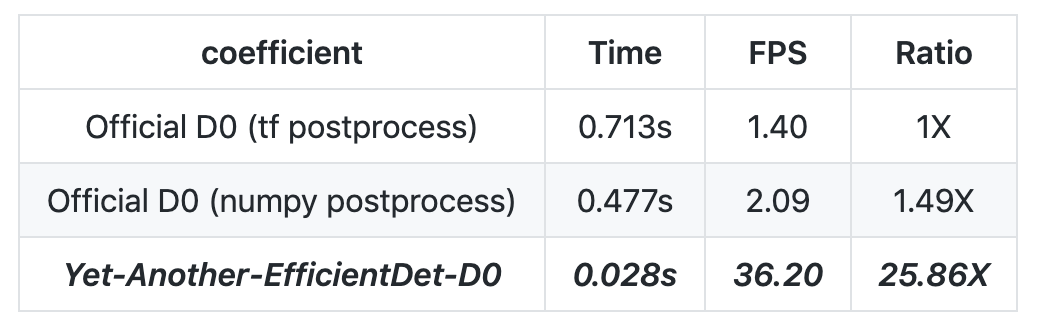
值得注意的是,此次项目处理速度比原版快了 20 余倍。
那么为什么之前都没有人复现 EfficientDet 的成绩?具体哪些细节需要注意?
「民间」EfficientDet 的取舍
作者前后试用了两个 GitHub 项目进行实现,但效果并不理想。首先采用的 star 量最高的一个,同时可能也说明了一点,不是 star 越高就越适合。
针对第一个项目,作者表示:「因为 EfficientDet 的特性之一是 BiFPN,它会融合 backbone 输出的任意相邻两层的 feature,但是由于有两层尺寸的宽高是不同的,所以会进行 upsample 或者 pooling 来保证它们宽高一致。而这个作者没有意识到,他不知道从 backbone 抽哪些 feature 出来,他觉得是 backbone 有问题,改了人家的 stride,随便挑了几层,去强迫 backbone 输出他想要的尺寸」
「改了网络结构,pretrained 权值基本就废了,所以作者也发现了,发现训练不下去了」。至此第一个项目画上句号,同时作者提供了官方参数与试用项目作者改后的参数对比链接,有兴趣的朋友可浏览参考链接。
而面向第二个项目,虽然 star 不及前者一半,但显然可靠度更甚前者。作者表示,第二个项目起码在 D0 上有论文成绩的支撑,同时 repo 也提供了 coco 的 pretrained 权值 31.4mAP。然而实操后作者得到 24mAP,同时社区普遍也在 20-22 范围中。
那么此次结果的原因是什么?作者经过反复的思考检测,得到以下 7 点总结,并就此 7 点复盘进行适当得调整,得到了当前项目不错的效果。
一波三折后的答案
针对第二个测试项目的复盘,作者表示一共有 7 个关键点需要额外注意:
- 第二个项目的 BN 实现有问题:BatchNorm 是有一个参数,叫做 momentum,用来调整新旧均值的比例,从而调整移动平均值的计算方式的。
- Depthwise-Separatable Conv2D 的错误实现。
- 误解了 maxpool2d 的参数,kernel_size 和 stride。
- 减少通道的卷积后面,没有进行 BN
- backbone feature 抽头抽错了
- Conv 和 pooling,没有用到 same padding
- 没有能正确的理解 BiFPN 的流程

来源于项目作者知乎账号,详情请见参考链接
作者还表示,其中有个非常关键点,「鸡贼的官方并没有表示这里是两个独立的 P4_0」。
简而言之,这篇知乎博客非常详细的介绍了各种复现注意事项,细节在此不再一一赘述。笔者认为对各炼金术师有一定参考价值,感兴趣的可以直接查看原文博客。
同时,机器之心对此项目也进行了实测。
项目实测
测试
我们在 P100 GPU,Ubuntu 18.04 系统下对本项目进行了测试。
首先将项目克隆到本地,并切换到相关目录下:
- !git clone https://github.com/zylo117/Yet-Another-EfficientDet-Pytorch
- import os
- os.chdir('Yet-Another-EfficientDet-Pytorch')
安装如下依赖环境:
- !pip install pycocotools numpy opencv-python tqdm tensorboard tensorboardX pyyaml
- !pip install torch==1.4.0
- !pip install torchvision==0.5.0
项目作者为我们提供了用于推断测试的 Python 脚本 efficientdet_test.py,该脚本会读取 weights 文件夹下保存的网络权重,并对 test 文件夹中的图片进行推断,之后将检测结果保存到同一文件夹下。首先,我们使用如下命令下载预训练模型:
- !mkdir weights
- os.chdir('weights')
- !wget https://github.com/zylo117/Yet-Another-Efficient-Pytorch/releases/download/1.0/efficientdet-d0.pth
之后把需要检测的图片放在 test 文件夹下,这里别忘了还要把 efficientdet_test.py 中对应的图像名称修改为我们想要检测图片的名称,运行 efficientdet_test.py 脚本即可检测图片中的物体,输出结果如下:

我们先用曾经爆火的共享单车,现如今倒了一大片沦为「共享单车坟场」测试一下效果如何。下图分别为原图与使用本项目的检测结果。


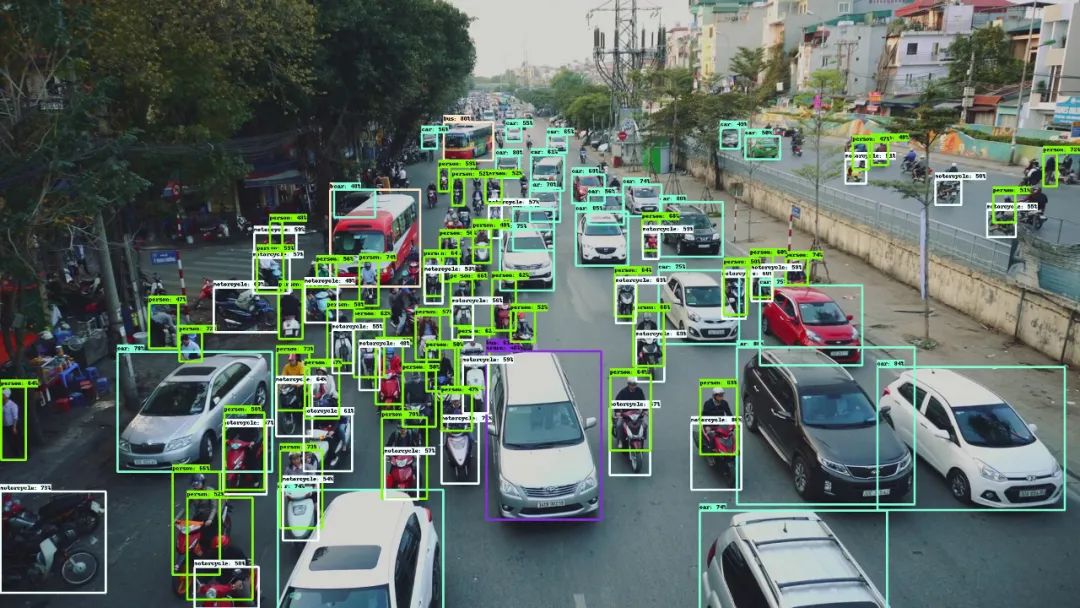
效果很不错,图片中的人与密密麻麻、横七竖八摆放的共享单车大多都检测了出来。接下来我们用一张国内常见的堵车场景来测试一下,车辆、非机动车、行人交错出现在画面中,可以说是非常复杂的场景了。从检测结果可以看出,基本上所有的行人、车辆、背包、袋子等物体都较好地检测了出来。


最后当然要在「开挂民族」坐火车的场景下测试一番,密集恐惧症慎入。虽然把旗子检测成了风筝(很多目标检测算法都容易出现这样的问题),但总体来说检测效果可以说是非常惊艳的。它检测出了图片中大部分的人物,和机器之心此前报道过的高精度人脸检测方法-DBFace 的准确率有得一拼。需要注意的是,DBFace 是专用于人脸检测的方法,而本项目实现的是通用物体检测。

训练
项目作者同时也提供了训练 EfficientDet 相关的代码。我们只需要准备好训练数据集,设置好类似于如下代码所示的训练参数,运行 train.py 即可进行训练。
- # create a yml file {your_project_name}.yml under 'projects'folder
- # modify it following 'coco.yml'
- # for example
- project_name: coco
- train_set: train2017
- val_set: val2017
- num_gpus: 4 # 0 means using cpu, 1-N means using gpus
- # mean and std in RGB order, actually this part should remain unchanged as long as your dataset is similar to coco.
- mean: [0.485, 0.456, 0.406]
- std: [0.229, 0.224, 0.225]
- # this is coco anchors, change it if necessary
- anchors_scales: '[2 ** 0, 2 ** (1.0 / 3.0), 2 ** (2.0 / 3.0)]'
- anchors_ratios: '[(1.0, 1.0), (1.4, 0.7), (0.7, 1.4)]'
- # objects from all labels from your dataset with the order from your annotations.
- # its index must match your dataset's category_id.
- # category_id is one_indexed,
- # for example, index of 'car' here is 2, while category_id of is 3
- obj_list: ['person', 'bicycle', 'car', ...]
在 coco 数据集上训练代码如下:
- # train efficientdet-d0 on coco from scratch
- # with batchsize 12
- # This takes time and requires change
- # of hyperparameters every few hours.
- # If you have months to kill, do it.
- # It's not like someone going to achieve
- # better score than the one in the paper.
- # The first few epoches will be rather unstable,
- # it's quite normal when you train from scratch.
- python train.py -c 0 --batch_size 12
在自定义数据集上训练:
- # train efficientdet-d1 on a custom dataset
- # with batchsize 8 and learning rate 1e-5
- python train.py -c 1 --batch_size 8 --lr 1e-5
项目作者强烈推荐在预训练的权重上对网络进行训练:
- # train efficientdet-d2 on a custom dataset with pretrained weights
- # with batchsize 8 and learning rate 1e-5 for 10 epoches
- python train.py -c 2 --batch_size 8 --lr 1e-5 --num_epochs 10
- --load_weights /path/to/your/weights/efficientdet-d2.pth
- # with a coco-pretrained, you can even freeze the backbone and train heads only
- # to speed up training and help convergence.
- python train.py -c 2 --batch_size 8 --lr 1e-5 --num_epochs 10
- --load_weights /path/to/your/weights/efficientdet-d2.pth
- --head_only True
【编辑推荐】

























