













一、故障及故障管理定义
业界故障管理均基于ITIL演化而来,根据实际情况精简流程以适配互联网的精益迭代。
1、ITIL中的定义
故障:①非计划性的IT服务中断,或者IT服务性能的下降。②配置项的失效,即便没有影响到服务。
故障管理:对所有故障进行处理的流程。
故障管理的目标:尽快恢复服务到正常运行,并且最小化对业务运营的不利影响,从而尽可能地保证服务质量和可用性的水平。
2、业界较完善定义
故障:除用户方环境或者用户自身操作引起的外,其他无论什么原因导致服务中断、服务品质下降或者用户服务体验下降。
故障管理:围绕故障生命周期采取的一系列活动和流程,包括故障等级定义、故障发现、故障响应、故障应急、故障恢复、故障复盘及持续改进。
故障管理的目标:预防可预知的问题,快速恢复不能预知的问题,不再重复已发生的问题。
二、为什么要做故障管理
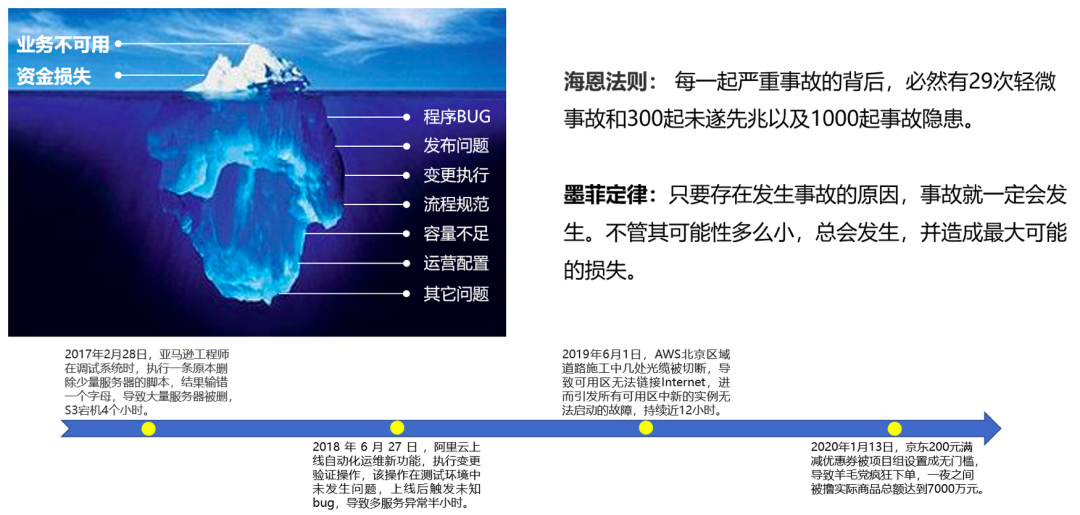
无论是理论还是实践,均证明故障只要有发生的可能,它总会发生。所以为了保障业务稳定性,需提前发现、解决风险,及时发现、定位原因、快速恢复故障,同时要确保改进措施有效落地、避免故障重复发生,我们需要建立一个规范可遵循、闭环的故障管理体系。
三、故障管理怎么做
故障管理就是围绕故障全生命周期管理,形成体系闭环、持续改进。
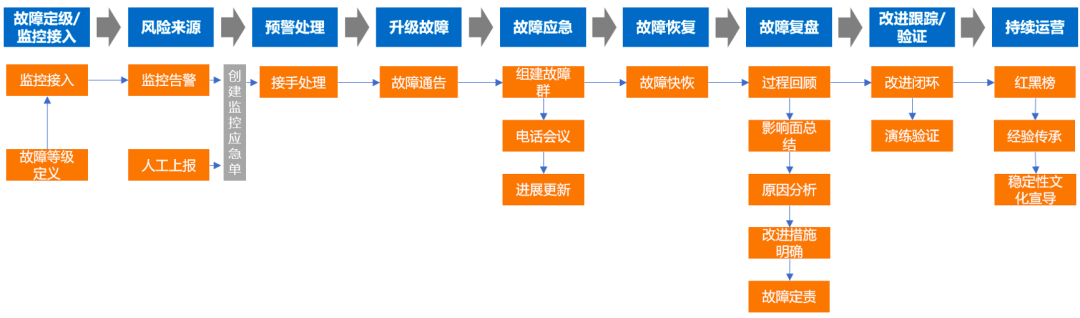
无论是理论还是实践,均证明故障只要有发生的可能,它总会发生。所以为了保障业务稳定性,需提前发现、解决风险,及时发现、定位原因、快速恢复故障,同时要确保改进措施有效落地、避免故障重复发生,我们需要建立一个规范可遵循、闭环的故障管理体系。
1、故障等级定义
1.1 故障序列
故障管理部门(例如质量部门、NOC、运维管理部门等)可根据实际情况定义故障序列,以下为目前业界可参考的序列,一类序列一般分为4级,级别数字越小严重程度越高。
- P(PRIORITY)序列:技术基础序列,为故障处理的综合优先级。
- D(DATA)序列:数据质量序列,综合数据资产等级与数据影响因素。
- R(RISK)序列:舆情风险序列。
- S(SLA)序列:衡量影响SLA严重程度。
1.2 故障定级
以P序列举例:
故障定级建议分为通用型和业务型两类,业务线型故障定级标准不得低于通用型故障定级标准。
通用型故障等级由故障管理部门定义,可包含受影响用户数、受影响商家数、客诉增量、资金损失等通用指标。通用型故障场景在业务线型故障场景未覆盖情况下兜底。
业务型故障等级由故障管理部门联合业务团队基于用户视角共同定义,以下为业务型故障定级举例。公司内部工具也可按照此模板定义故障级别以纳入故障管理。
2、监控告警
核心是业务监控关联故障等级定义做到故障及时发现。
告警本身要做到智能告警以提升告警准确率,例如智能阈值、智能基线、根因算法等。
3、故障应急
问题升级为故障后,由故障管理部门及时通告故障信息,拉起故障处理群/电话会议,协调、跟进、监督故障处理直至恢复。
由于故障管理部门需要7X24应急响应,有条件的公司可以参考google的SRE、阿里的GOC组建团队,成员分布不同时区,实现日出而作,日落而息。
4、故障恢复
故障发生后的第一要务是恢复业务,预案、重启、降级、隔离、切流、饱和式应急等,都是可选的方案。
5、故障复盘
5.1、故障复盘时效
为确保问题、风险能够得到足够重视,并及时制定改进措施,建议P1P2级别故障1个工作日内完成复盘,P3P4故障3个工作日完成复盘,其他序列故障可参考P序列时效性。
5.2、故障复盘准备工作
为提升复盘会议效率,故障管理人(复盘会议主持人)应该在会议之前整理如下信息:
- 故障处理过程:必须包含故障注入、故障发生、故障发现、故障响应、初因定位、恢复执行、故障恢复、根因定位等核心时间点及操作,其他关键时间点及操作视实际情况补充。
- 影响业务:具体到下跌时段、下跌比例,资金损失金额。
- 用户/商家影响情况:理论影响量,来电、在线咨询量
- 故障根因及对应根因分类:设备故障、代码问题、流程规范、应急灾备、容量等。
5.3、故障复盘重要关注点
- 故障预防:是否变更触发
- 故障发现:发现时长,发现来源,监控优化
- 应急响应:响应时长
- 故障恢复:恢复时长,恢复措施沉淀,改进
- 改进措施:基于以上信息制定可验的证改进措施,完成时间点,负责人
6、持续运营
持续运营是个广义的概念,除了故障数据各种维度晾晒、经验传承、文化宣导外,最主要的是通过故障数据分析,识别故障各个生命阶段的薄弱点、风险点,针对薄弱点、风险点有专项改进。
比如多次未灰度直接发布引起重大故障,变更制度、变更平台是否可强管控;故障恢复主要依赖代码发布导致恢复慢,是否可打造及时恢复文化,针对常见故障场景是否能沉淀快恢预案等。
四、对故障管理工作者的建议
故障管理路长且艰,以下给故障管理同学的建议,希望共勉。
1. 积极主动、认真负责
- 风险、问题跟进不到位,演变成故障的数量会增多
- 故障跟进不到位,影响面会扩大
- 故障根因不明确,改进措施可能无效
- 改进措施无效,故障还会重复发生
2. 敢于质疑
- 监控发现是否及时
- 故障处理过程是否可优化,有没有人为失误
- 业务影响面统计是否真实
- 故障原因是否是本次故障的根因
- 改进措施制定是否合理
3. 自我提升
故障管理者不是统计、记录文员,要以架构师严格要求自己,能够指出故障各个阶段存在的问题,并能够独立承担对应优化专项。





















