0x00.前言
这是TCP/IP协议栈系列的第三篇文章,之前的一篇面试热点|理解TCP/IP传输层拥塞控制算法讲述了传统的拥塞控制算法基本原理,今天一起来学习下最新Linux内核中增加的拥塞控制算法:TCP BBR算法。
鉴于TCP拥塞控制算法背后有一套复杂的数学理论和控制策略,因此本文也只能是浅谈,通过本文你将了解到以下内容(温馨提示:文章较长需要一些耐心,也可以先收藏再阅读):
- 回顾传统拥塞控制算法
- TCP BBR算法的概况
- BBR算法的原理简介
0x01. 拥塞控制简史
大约在1988年之前TCP/IP是没有拥塞控制的,但是随着网络接入规模的发展之前仅有的端到端窗口控制已经无法满足要求,在1986年引发大规模网络瘫痪,此时就要提到一个重量级人物:Van Jacobson范·雅各布森。
这位力挽狂澜的人物入选了计算机名人堂Internet Hall of Fame,Van Jacobson大神提出并设计实施了TCP/IP拥塞控制,解决了当时最大的问题,来简单看下Van Jacobson的维基百科简介(笔者做了部分删减):
范·雅各布森Van Jacobson是目前作为互联网技术基础的TCP/IP协议栈的主要起草者,他以其在网络性能的提升和优化的开创性成就而闻名。
2006年8月,他加入了帕洛阿尔托研究中心担任研究员,并在位于相邻的施乐建筑群的Packet Design公司担任首席科学家。在此之前,他曾是思科系统公司首席科学家,并在位于劳伦斯伯克利国家实验室的网络研究小组任领导者。
范·雅各布森因为在提高IP网络性能提升和优化所作的工作而为人们所知,1988到1989年间,他重新设计了TCP/IP的流控制算法(Jacobson算法),他因设计了RFC 1144中的TCP/IP头压缩协议即范·雅各布森TCP/IP头压缩协议而广为人知。此外他也曾与他人合作设计了一些被广泛使用的网络诊断工具,如traceroute,pathchar以及tcpdump 。
范·雅各布森于2012年4月入选第一批计算机名人堂,计算机名人堂简介:https://www.internethalloffame.org/inductees/van-jacobson
如图为Van Jacobson计算机名人堂的简介:

笔者找了Van Jacobson和Michael J. Karels在1988年11月发布的关于拥塞避免和控制的论文,总计25页,感兴趣的读者可以查阅:
https://ee.lbl.gov/papers/congavoid.pdf
我们常用的tracetoute和tcpdump也是van-jacobson大神的杰作,作为互联网时代的受益者不由得对这些互联网发展早期做出巨大贡献的开拓者、创新者、变革者心生赞叹和敬意。
0x02.传统拥塞控制算法回顾
2.1 算法目的
看到一篇文章说到TCP 传输层拥塞控制算法并不是简单的计算机网络的概念,也属于控制论范畴,感觉这个观点很道理。
TCP拥塞控制算法的目的可以简单概括为:公平竞争、充分利用网络带宽、降低网络延时、优化用户体验,然而就目前而言要实现这些目标就难免有权衡和取舍。
但是现在的网络通信基础设施水平一直在飞速提高,相信在未来的某个时间点这些目标都可以达到,小孩子才选择,我们大人全都要!
2.2 算法分类
在理解拥塞控制算法之前我们需要明确一个核心的思想:闻道有先后 术业有专攻,笔者觉得这是一个非常重要的共识问题,把A踩在泥土里,把B吹捧到天上去,都不是很好的做法。
实际的网络环境十分复杂并且变化很快,并没有哪个拥塞控制算法可以全部搞定,每一种算法都有自己的特定和适用领域,每种算法都是对几个关键点的权衡,在无法兼得的条件下有的算法选择带宽利用率,有的算法选择通信延时等等。
在明确这个共识问题之后,我们对待各个拥塞控制算法的态度要平和一些,不要偏激地认为谁就是最好,几十年前的网络状况和现在是截然不同的,我们永远都是站在巨人的肩膀之上的,这也是科学和文明进步的推动力。
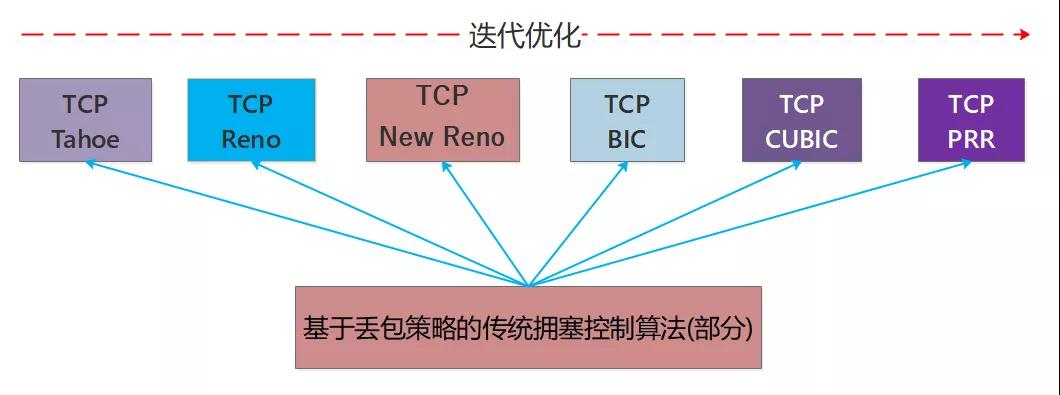
传统拥塞控制算法并不是一蹴而就的,复杂的网络环境和用户的高要求推动着拥塞控制算法的优化和迭代,我们看下基于丢包策略的传统拥塞控制算法的几个迭代版本,如图所示:
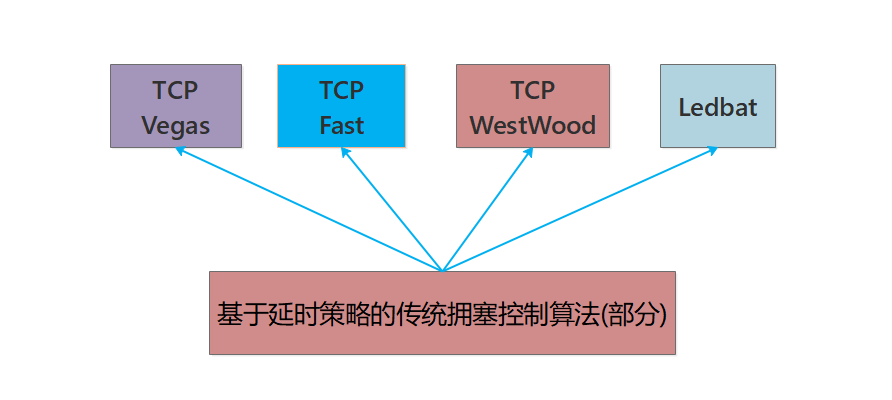
与此同时还有一类算法是基于RTT延时策略来进行控制的,但是这类算法在发包速率上可能不够激进,竞争性能不如其他算法,因此在共享网络带宽时有失公平性,但是算法速率曲线却是很平滑,我们暂且把这类算法当做君子吧!
其中比较有名的Vegas算法是大约在1995年由亚利桑那大学的研究人员拉里·彼得森和劳伦斯·布拉科夫提出,这个新的TCP拥塞算法以内华达州最大的城市拉斯维加斯命名,后成为TCP Vegas算法。
关于基于RTT的TCP Vegas算法的详细介绍可以查阅文档:
http://www.cs.cmu.edu/~srini/15-744/F02/readings/BP95.pdf
文档对Vegas算法和New Reno做了一些对比,我们从直观图形上可以看到Vegas算法更加平滑,相反New Reno则表现除了较大的波动呈锯齿状,如图所示:
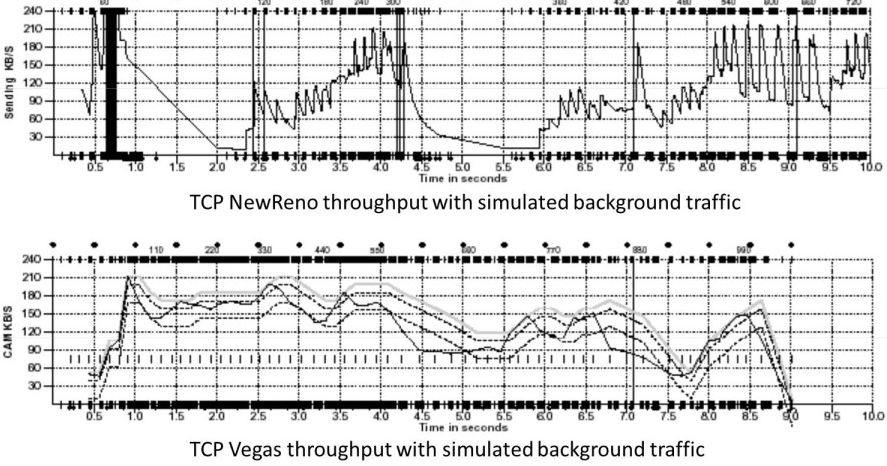
实际上还有更细粒度的分类,由于不是今天的重点,就不再深入展开了,当前使用的拥塞控制算法还是基于丢包Loss-Based作为主流。
2.3 算法原则
我们知道在网络链路中连接的数量是动态变化且数量巨大的,每一条连接都面临着一个黑盒子式的网络环境,这并不像我们平时出行时看看地图就知道哪里堵了,为了维护一个好的网络环境,每一条连接都需要遵守一些约定。
如果连接端都无所顾忌地发生数据包,那么网络链路很快就到了瓶颈了,数据通信完全无法保障,所以要到达一个稳定高效的网络环境还是需要费很大心思的,这其中有两个重要的概念:公平性和收敛性。
说来惭愧笔者在网络上找了很多资料去理解TCP拥塞控制的公平性和收敛性,但是仍然没有获得一个很好的权威解释,所以只能结合一些资料和自身的理解去阐述所谓的公平性和收敛性。
笔者认为公平性是相对于网络链路中的所有连接而言的,这些共享链路的连接启动和结束的时间不同,在实际的交互过程中每条连接占有带宽的机会是均等的,并且由于带宽限制连接双方通信的数据量是动态调整并且近似收敛于某个值,也就是呈现一个锯齿状或者更加平滑的波动曲线,对于基于丢包的拥塞控制算法而言AIMD线性增乘性减策略起了关键控制作用。
接下来我们来重点看下AIMD特性,先来贴一张经典的图,直观看AIMD的过程:
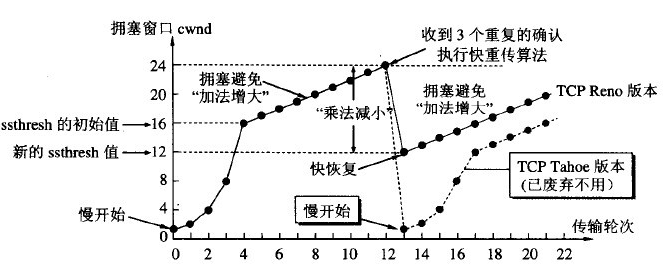
看看维基百科对于AIMD的定义:
The additive-increase/multiplicative-decrease(AIMD) algorithm is a feedback control algorithm best known for its use in TCP congestion control.
AIMD combines linear growth of the congestion window with an exponential reduction when congestion is detected.
Multiple flows using AIMD congestion control will eventually converge to use equal amounts of a shared link.
The related schemes of multiplicative-increase/multiplicative-decrease (MIMD) and additive-increase/additive-decrease (AIAD) do not reach stability.
简单翻译一下:线性增加乘性减少算法是一个反馈控制算法,因其在TCP拥塞控制中的使用而广为人知,AIMD将线性增加拥塞窗口和拥塞时乘性减少窗口相结合,基于AIMD的多个连接理想状态下会达到最终收敛,共享相同数量的网络带宽,与其相关的乘性增乘性减MIMD策略和增性加增性减少AIAD都无法保证稳定性。
AIMD相比MIMD和AIAD在连接进入拥塞避免阶段使用试探线性加策略而不是乘性加策略更加安全,在探测丢包时则大幅度乘性减少到1/2这样对于缓解拥塞会有比较好的效果更加快速,相反如果探测到丢包时采用线性减少AD可能拥塞持续的时间会更长,总体来说AIMD算是一个比较简单实用的工程版本的反馈控制,也具备可工程收敛性,因而被广泛实用。
2.4 弱网络环境下的AIMD
时间拉回20多年前,在互联网早期几乎所有的设备都是通过有线网络进行连接通信的,这也是拥塞控制在设计之后一直都起到不错作用的重要因素,有线连接的网络稳定性比较好,因此把丢包作为网络拥堵的一个特征也很正常。
再拉回到现在,从2010年之后移动互联网蓬勃发展,移动终端的持有量已经可以称为海量,无线网络的引入让网络环境变得更加复杂,因此不稳定丢包变得更加频繁,但是这时的丢包就不一定是网络拥堵造成的了,因为整个数据包经过多重路由、交换机、基站等基础通信设备每个环节都可能发生异常。
在弱网环境下,尤其是移动互联网中之前的基于AIMD的拥塞控制策略可能会由于丢包的出现而大幅降低网络吞吐量,从而对网络带宽的利用率也大大下降,这时我们采用更加激进的控制策略,或许可以获得更好的效果和用户体验。
恶意丢包的情况下,基于AIMD的拥塞控制确实就相当于被限速了,因为AIMD确实有些保守谨慎了,这个其实也很好理解的哈。
我们都知道在移动网络环境下是由终端以无线形式和附近的基站交互数据,之后数据传输至核心网,最后落到具体的服务器所在的有线网络,其中最后一公里的区域属于高延时场景,有线网络属于低延时高带宽场景。
在国外有相关实验证明弱网环境下RTT的变化对于使用传统拥塞控制算法下网络吞吐量的影响,数据和曲线如图所示:

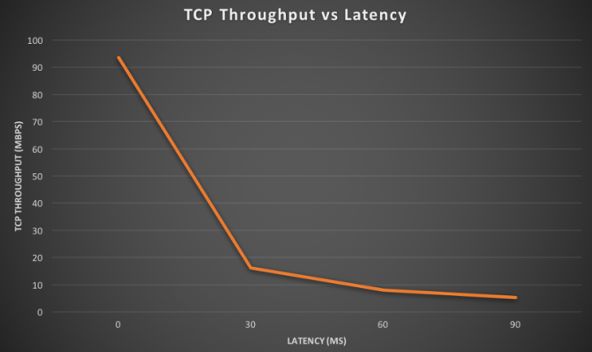
实验含义:RTT的增大影响了比如CUBIC这类拥塞控制算法的慢启动等阶段,我们知道慢启动阶段每经过1个RTT周期拥塞窗口cwnd将加倍,但是更大的RTT就意味着发送方以很低的速率发送数据,更多的时间是空闲的,发包的加速度极大将低了,所以整个吞吐量就下降很明显。
看下实验者的原文表述:
The delay before acknowledgment packets are received (= latency) will have an impact on how fast the TCP congestion window increases (hence the throughput).
When latency is high, it means that the sender spends more time idle (not sending any new packets), which reduces how fast throughput grows.
0x03 TCP BBR算法简介
BBR算法是个主动的闭环反馈系统,通俗来说就是根据带宽和RTT延时来不断动态探索寻找合适的发送速率和发送量。
看下维基百科对BBR算法的说明和资料:
相关文献:https://queue.acm.org/detail.cfm?id=3022184
TCP BBR(Bottleneck Bandwidth and Round-trip propagation time)是由Google设计,并于2016年发布的拥塞算法,以往大部分拥塞算法是基于丢包来作为降低传输速率的信号,而BBR基于模型主动探测。
该算法使用网络最近出站数据分组当时的最大带宽和往返时间来创建网络的显式模型。数据包传输的每个累积或选择性确认用于生成记录在数据包传输过程和确认返回期间的时间内所传送数据量的采样率。
该算法认为随着网络接口控制器逐渐进入千兆速度时,分组丢失不应该被认为是识别拥塞的主要决定因素,所以基于模型的拥塞控制算法能有更高的吞吐量和更低的延迟,可以用BBR来替代其他流行的拥塞算法例如CUBIC。Google在YouTube上应用该算法,将全球平均的YouTube网络吞吐量提高了4%,在一些国家超过了14%。BBR之后移植入Linux内核4.9版本,并且对于QUIC可用。
3.1 基于丢包反馈策略可能在的问题
基于丢包反馈属于被动式机制,根源在于这些拥塞控制算法依据是否出现丢包事件来判断网络拥塞做减窗调整,这样就可能会出现一些问题:
丢包即拥塞
现实中网络环境很复杂会存在错误丢包,很多算法无法很好区分拥塞丢包和错误丢包,因此在存在一定错误丢包的前提下在某些网络场景中并不能充分利用带宽。
缓冲区膨胀问题BufferBloat
网络连接中路由器、交换机、核心网设备等等为了平滑网络波动而存在缓冲区,这些缓存区就像输液管的膨胀部分让数据更加平稳,但是Loss-Based策略在最初就像网络中发生数据类似于灌水,此时是将Buffer全部算在内的,一旦buffer满了,就可能出现RTT增加丢包等问题,就相当于有的容量本不该算在其中,但是策略是基于包含Buffer进行预测的,特别地在深缓冲区网络就会出现一些问题。
网络负载高但无丢包事件
假设网络中的负载已经很高了,只要没有丢包事件出现,算法就不会主动减窗降低发送速率,这种情况下虽然充分利用了网络带宽,同时由于一直没有丢包事件出现发送方仍然在加窗,表现出了较强的网络带宽侵略性,加重了网络负载压力。
高负载丢包
高负载无丢包情况下算法一直加窗,这样可以预测丢包事件可能很快就出现了,一旦丢包出现窗口将呈现乘性减少,由高位发送速率迅速降低会造成整个网络的瞬时抖动性,总体呈现较大的锯齿状波动。
低负载高延时丢包
在某些弱网环境下RTT会增加甚至出现非拥塞引起丢包,此时基于丢包反馈的拥塞算法的窗口会比较小,对带宽的利用率很低,吞吐量下降很明显,但是实际上网络负载并不高,所以在弱网环境下效果并不是非常理想。
3.2 TCP BBR算法基本原理
前面我们提到了一些Loss-Based算法存在的问题,TCP BBR算法是一种主动式机制,简单来说BBR算法不再基于丢包判断并且也不再使用AIMD线性增乘性减策略来维护拥塞窗口,而是分别采样估计极大带宽和极小延时,并用二者乘积作为发送窗口,并且BBR引入了Pacing Rate限制数据发送速率,配合cwnd使用来降低冲击。
3.2.1 一些术语
BDP
BDP是Bandwidth-Delay Product的缩写,可以翻译为带宽延时积,我们知道带宽的单位是bps(bit per second),延时的单位是s,这样BDP的量纲单位就是bit,从而我们知道BDP就是衡量一段时间内链路的数据量的指标。这个可以形象理解为水管灌水问题,带宽就是水管的水流速度立方米/s,延时就是灌水时间单位s,二者乘积我们就可以知道当前水管内存储的水量了,这是BBR算法的一个关键指标,来看一张陶辉大神文章中的图以及一些网络场景中的BDP计算:
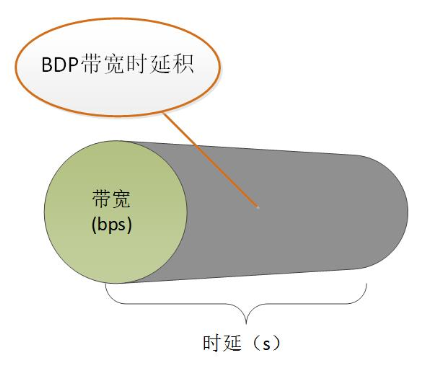
长肥网络
我们把具有长RTT往返时间和高带宽的网络成为长肥网络或者长肥管道,它的带宽延时积BDP很大大,这种网络理论上吞吐量很大也是研究的重点。
TCP Pacing机制
可以简单地理解TCP Pacing机制就是将拥塞控制中数据包的做平滑发送处理,避免数据的突发降低网络抖动。
3.2.2 带宽和延时的测量
BBR算法的一些思想在之前的基于延时的拥塞控制算法中也有出现,其中必有有名的是TCP WestWood算法。
TCP Westwood改良自New Reno,不同于以往其他拥塞控制算法使用丢失来测量,其通过对确认包测量来确定一个合适的发送速度,并以此调整拥塞窗口和慢启动阈值。其改良了慢启动阶段算法为敏捷探测和设计了一种持续探测拥塞窗口的方法来控制进入敏捷探测,使链接尽可能地使用更多的带宽。
TCP WestWood算法也是基于带宽和延时乘积进行设计的,但是带宽和延时两个指标无法同时测量,因为这两个值是有些矛盾的极值,要测量最大带宽就要发送最大的数据量但是此时的RTT可能会很大,如果要测量最小的RTT那么久意味着数据量非常少最大带宽就无法获得。
TCP BBR算法采用交替采样测量两个指标,取一段时间内的带宽极大值和延时极小值作为估计值,具体的实现本文就不展开了。
3.2.3 发送速率和RTT曲线
前面提到了BBR算法核心是寻找BDP最优工作点,在相关论文中给出了一张组合的曲线图,我们一起来看下:
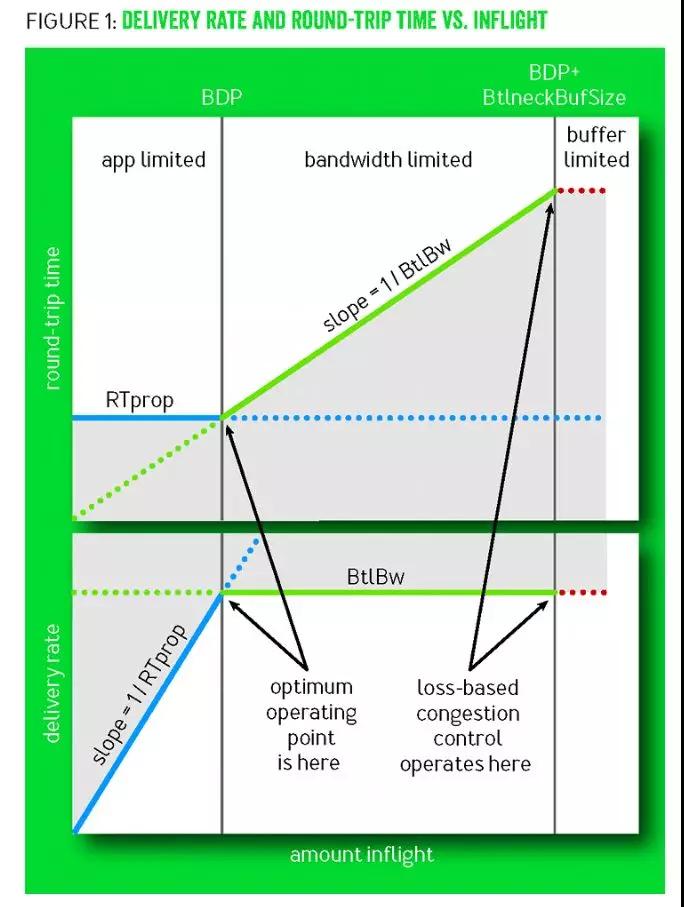
1.曲线图示说明:
这张图是由两个图组合而成,目前是展示[数据发送速率vs网络数据]和[RTTvs网络数据]的关系,横轴是网络数据数量。
两个纵轴从上到下分别为RTT和发送速率,并且整个过程分为了3个阶段:应用限制阶段、带宽限制阶段、缓冲区限制阶段。
2.曲线过程说明:
app limit应用限制阶段
在这个阶段是应用程序开始发送数据,目前网络通畅RTT基本保持固定且很小,发送速率与RTT成反比,因此发送速率也是线性增加的,可以简单认为这个阶段有效带宽并没有达到上限,RTT是几乎固定的没有明显增长。
band limit带宽限制阶段
随着发送速率提高,网络中的数据包越来越多开始占用链路Buffer,此时RTT开始增加发送速率不再上升,有效带宽开始出现瓶颈,但是此时链路中的缓存区并没有占满,因此数据还在增加,RTT也开始增加。
buffer limit缓冲区限制阶段
随着链路中的Buffer被占满,开始出现丢包,这也是探测到的最大带宽,这个节点BDP+BufferSize也是基于丢包的控制策略的作用点。
3.一些看法
网上有一些资料都提及到了这张图,其中的一些解释也并不算非常清晰,结合这些资料和自己的认识,笔者认为在网络链路的缓存区没有被使用时RTT为最小延时MinRTT,在网络链路缓冲区被占满时出现最大带宽MaxBW(链路带宽+链路缓存),但是此时的MaxBW和MinRTT并不是最优的而是水位比较高的水平,有数据表明按照2ln2的增益计算此时为3BDP,整个过程中MinRTT和MaxBW是分开探测的,因为这二者是不能同时被测量的。
3.2.4 BBR算法的主要过程
BBR算法和CUBIC算法类似,也同样有几个过程:StartUp、Drain、Probe_BW、Probe_RTT,来看下这几个状态的迁移情况:
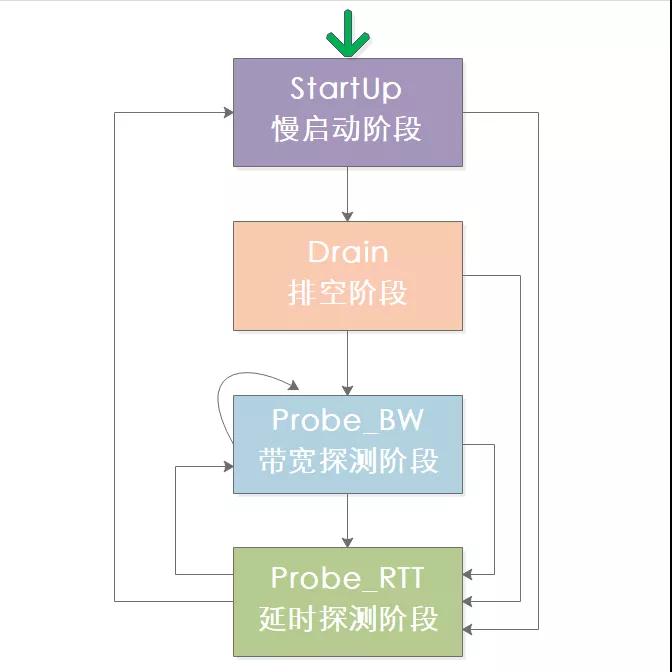
StartUp慢启动阶段
BBR的慢启动阶段类似于CUBIC的慢启动,同样是进行探测式加速区别在于BBR的慢启动使用2ln2的增益加速,过程中即使发生丢包也不会引起速率的降低,而是依据返回的确认数据包来判断带宽增长,直到带宽不再增长时就停止慢启动而进入下一个阶段,需要注意的是在寻找最大带宽的过程中产生了多余的2BDP的数据量,关于这块可以看下英文原文的解释:
To handle Internet link bandwidths spanning 12 orders of magnitude, Startup implements a binary search for BtlBw by using a gain of 2/ln2 to double the sending rate while delivery rate is increasing. This discovers BtlBw in log2BDP RTTs but creates up to 2BDP excess queue in the process.
Drain排空阶段
排空阶段是为了把慢启动结束时多余的2BDP的数据量清空,此阶段发送速率开始下降,也就是单位时间发送的数据包数量在下降,直到未确认的数据包数量
ProbeBW带宽探测阶段
经过慢启动和排空之后,目前发送方进入稳定状态进行数据的发送,由于网络带宽的变化要比RTT更为频繁,因此ProbeBW阶段也是BBR的主要阶段,在探测期中增加发包速率如果数据包ACK并没有受影响那么就继续增加,探测到带宽降低时也进行发包速率下降。
ProbeRTT延时探测阶段
前面三个过程在运行时都可能进入ProbeRTT阶段,当某个设定时间内都没有更新最小延时状态下开始降低数据包发送量,试图探测到更小的MinRTT,探测完成之后再根据最新数据来确定进入慢启动还是ProbeBW阶段。
我们来看一下这四个过程的示意图:
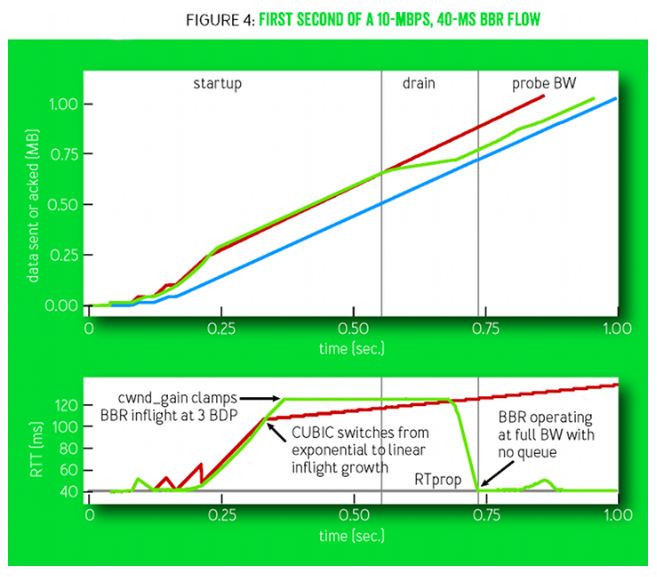
曲线说明:这两个坐标给出了10Mbps和40msRTT的网络环境下CUBIC和BBR的一个对比过程,在上面的图中蓝色表示接收者,红色表示CUBIC,绿色表示BBR,在下面的图中给出了对应上图过程中的RTT波动情况,红色代表CUBIC,绿色代表BBR。
0x04.TCP BBR算法的一些效果
有一些文章认为BBR有鲜明的特点,把拥塞控制算法分为BBR之前和BBR之后,可见BBR还是有一定影响,但是BBR算法也不是银弹,不过可以先看看BBR算法在谷歌推动下的一些应用效果,其中包括吞吐量、RTT、丢包率影响:
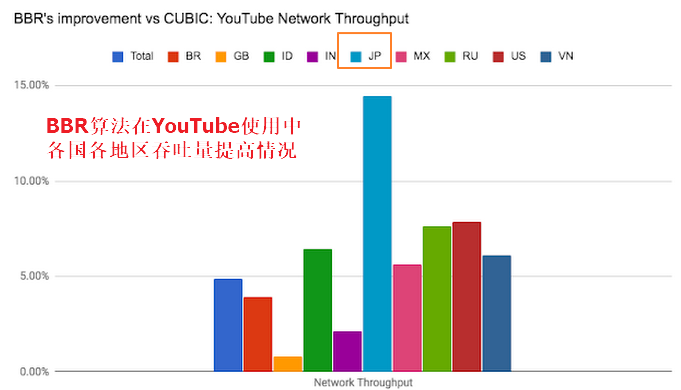
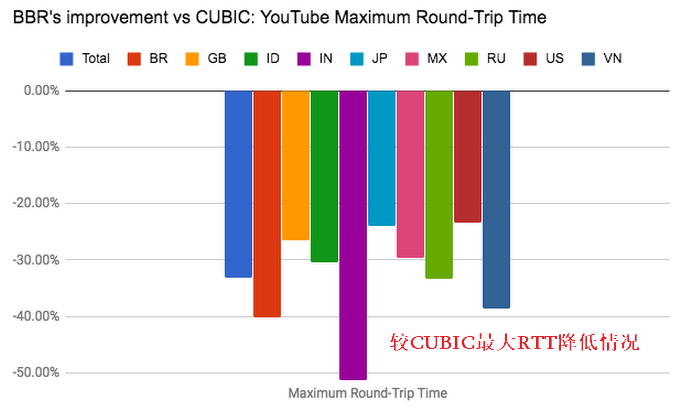
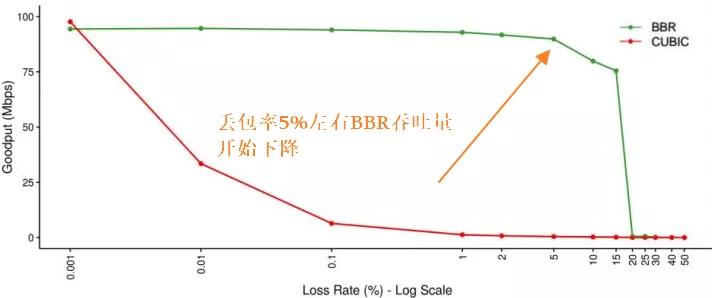
从图中我们可以看到在YouTube应用BBR算法之后,就吞吐量普遍有4%左右的提升,特别地在日本的提升达到14%,RTT的下降更为明显平均降低33%,其中IN(猜测是印度地区)达到50%以上,在丢包率测试中BBR并不想CUBIC那么敏感,在丢包率达到5%是吞吐量才开始明显下降。
0x05.总结
本文先回顾了以CUBIC为代表传统的拥塞控制算法,之后展开了对BBR算法的一些介绍。
网络上关于BBR的文章很多,笔者也尝试结合很多文章和外文资料进行理解和归纳,但是由于笔者工作经验和水平所致上述文字中可能存在一些问题,对此表达歉意,并且很多细节也并未展开,所以只能当做是一次浅谈了。
0x06.巨人的肩膀
https://cloud.tencent.com/developer/article/1369617
https://www.cnblogs.com/codingMozart/p/9497254.html
https://blog.csdn.net/dog250/article/details/57072103
https://my.oschina.net/piorcn/blog/806997
https://my.oschina.net/piorcn/blog/806994
https://my.oschina.net/piorcn/blog/806989
https://accedian.com/enterprises/blog/measuring-network-performance-latency-throughput-packet-loss/
https://mp.weixin.qq.com/s/BGWkvLl0AAx9slI1lSZMgw
https://www.zhihu.com/question/53559433
https://cloud.google.com/blog/products/gcp/tcp-bbr-congestion-control-comes-to-gcp-your-internet-just-got-faster
https://cloud.tencent.com/developer/article/1383232
https://queue.acm.org/detail.cfm?id=3022184
https://juejin.im/post/5e0894a3f265da33d83e85fe
https://zhuanlan.zhihu.com/p/63888741