













最近几周,发生过多起因为事务问题引起的服务报错。现象为数据库连接池连接占满,数据库连接长时间等待,最终导致请求线程hang住,服务大面积报错。这个时候,服务资源、数据库资源大量空闲,但就是进行不下去,影响是比较恶劣的。
谁来背锅?当然是架构师。因为这次所有的服务都活着,没运维什么事。
面试时,大家可能都会碰到关于事务相关的问题,升级版的可能是分布式事务的问题。在互联网行业中,一句马马虎虎的补偿事务就能蒙混过关,毕竟都是些短小精悍的接口。
但在很多企业级应用中,这行不通。我们必须直面惨淡的现实。
为什么要用长事务?
在许多业务非常复杂的后台系统,经常频繁操作DB,为了保证数据的一致性,能够在出错时回滚数据,通常会使用事务。
就拿最简单的单机数据库事务来说。
在事务操作期间,如果持续时间过长,只有等事务结束之后,DB连接才会释放,此类长时间占用DB连接的事务操作,称为长事务。一旦外部有大量请求,并发调用此操作,那么将会有大量的DB连接被持有而没有被释放掉,直到连接池爆满。
这个时候,如果有其他请求到来,那十有八九是以失败告终。
也就是说,连接资源被少数长事务操作占用。在这种情况下,即使是最简单接口查询,都不能够正常进行。
几粒老鼠屎,坏了一锅粥。
一些魔幻的反应
当你去排查这种问题的时候,可能会陷入僵局。jstack显示,多数请求其实是阻塞在tomcat的线程池上,而且是一些访问速度非常快的请求被阻塞。
比如,tomcat的200个线程,有180个阻塞在耗时不到1ms的/status接口上。
很多人就一脸懵逼。经验失灵。
jstack此时的输出结果,欺骗了我们。真正造成阻塞的,是那额外的20多个线程。
有哪些改善?
保证事务的短小是一个基本要求,包括但不限于:
应控制慢查询的调用频率,尽量减少慢查询。很多情况下,这条规则是自欺欺人的,需要业务做一些妥协。
事务内不应包含任何RPC调用,减少事务的粒度。通常,一些RPC调用,包括其他非事务资源的调用,耗时非常不可控。如果把它们也纳入事务的范围之内,势必会加剧资源的占用。事务内不应包含其他容易超时或者长时间阻塞的服务,如HTTP调用、IO操作。
次优先级服务如消息队列,不应该放在事务内,避免因为消息队列不可用引起的服务不可用。给类似消息队列的组件,设置一个合理的超时时间的非常有必要的,否则它就会一直等在那里。但即使是这样,也尽量不要把它们纳入到事务操作之内。
跨库、跨类型(如Redis),不应该放在同一事务中,可避免交叉影响。
你可以看到上面的这些描述,有些和我们所追求的数据一致性是相悖的。这不奇怪,依然是CAP原理的权衡。有些业务选择的是宁可卡死不再响应,也不能进入异常数据;有些则首先让业务运行下去,脏数据会通过补偿事务进行修正。
一切看你的选择。
设计总有人背锅,补偿总有人做出牺牲。
解决方式
那么如何来快速解决大事务造成的服务不可用问题呢?
除了扩容,其实是无解。重启大法也不见得好用。因为被阻断的请求,会以更凶猛的态势再次来袭。
你可能会想到调大连接池的大小。但在实践中得知,也不好用,大事务请求会迅速将连接池占满。
但我们可以提前进行防御。
以Spring为例,事务的使用方式大多数是使用@Transactional注解来控制的,或者是声明式事务方式。我建议以以下方式进行预防和发现:
1) 重新扫描或者Review业务代码,排查事务中是否有以上提到的各种情况。然后将除DB操作外的其他操作移动到事务之外。
2) 每个事务操作都给予足够重视,对于执行复杂度和时间复杂度不确定的事务,添加超时报警,及时发现引起的原因。
同时,还需要加强监控,辅助进行问题排查。
1) 业务可以考虑定时将数据库连接池的信息进行打印,通过看日志的方式进行初步排查。
2) 使用jstack查询执行栈,找出阻塞的点。
3) 排查并联系下游服务,找出主要原因
xjjdog倾向于使用监控快速发现问题。如图,通过连接池监控,可以看到数据库连接池连接数长时间保持在高位不释放,同时等待的线程数急剧增加。发生此种现象多数可以考虑是否是以上原因引起。
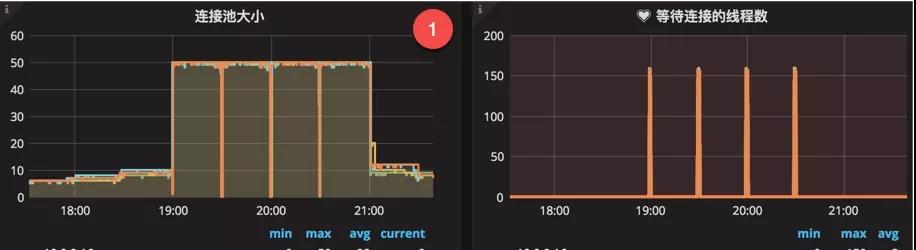
发生问题时,应及时(多次)使用jstack定位到线程的阻塞位置,然后排查下游服务是否有问题,或者是否存在慢查询。
最好的情况是服务已经进行了对代码的梳理,那么引起的原因大概率只剩下了慢查询。针对慢查询,druid数据库连接池,提供了sql的聚合,能够查看是每一类查询语句的具体执行情况。如图,短时间内SQL请求飙升,最大执行时长上升,连接池占满:
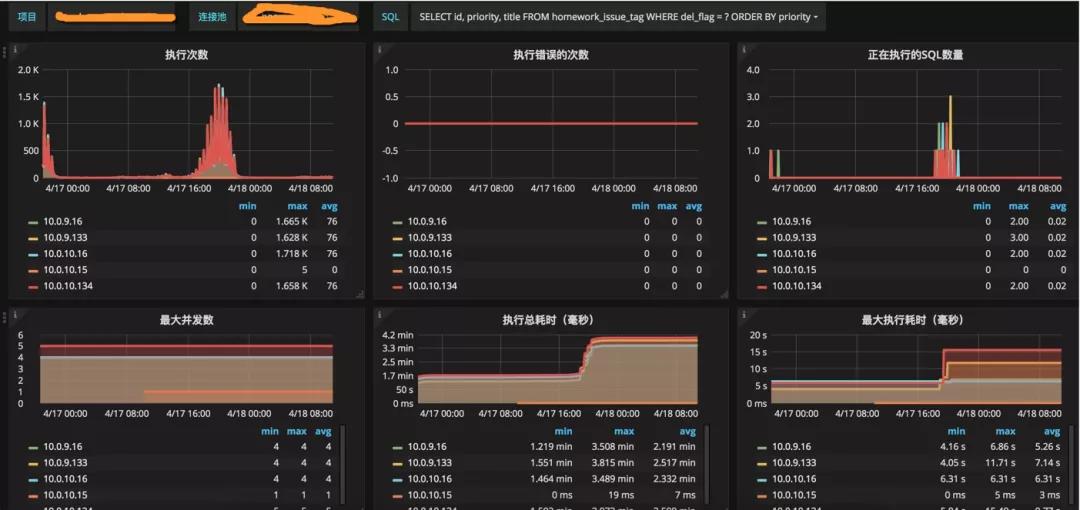
具体是哪一句SQL所引起的,一目了然。
End
长事务问题的危险级别属于高危型,通常会造成严重的后果,可以通过观察监控,防范于未然。
最优的解决方式,当然是业务模型的改进。但这东西第一涉及到开发成本,第二涉及到跨部门协作。
出钱的老板,无法听懂你这些梦话。
在一些公司内部,这两者都是让人抓狂的事情,还不如痛痛快快背个锅,来得实在。





















