不知道开发的同学有没有遇到过类似这样的需求:
- 相同类型的数据在多个系统中,如果要得到全部的信息,就要连续调多个系统的接口;
- 业务复杂,一个需求需要关联几张表甚至几十张表才能得到想要的结果;
- 系统做了分库分表,但是需要统计所有的数据。
那么此类需求要如何满足呢?我们选择了“通过 ETL 提前进行数据整合”的方案。
什么是 ETL
说到ETL,很多开发伙伴可能会有些陌生,更多的时候 ETL 是用在大数据、数据分析的相关岗位;我也是在近几年的工作过程中才接触到ETL的,现在的项目比较依赖 ETL,可以说是项目中重要的一部分。
ETL 是三个单词的缩写:
- Extraction:抽取、提取;就是把数据从数据库里面取出来;
- Transformation:转换;包括但不限于:数据筛选校验、数据关联、数据内容及结构的修改、运算、统计等等;
- Loading:加载;将处理后的数据保存到目标数据库。
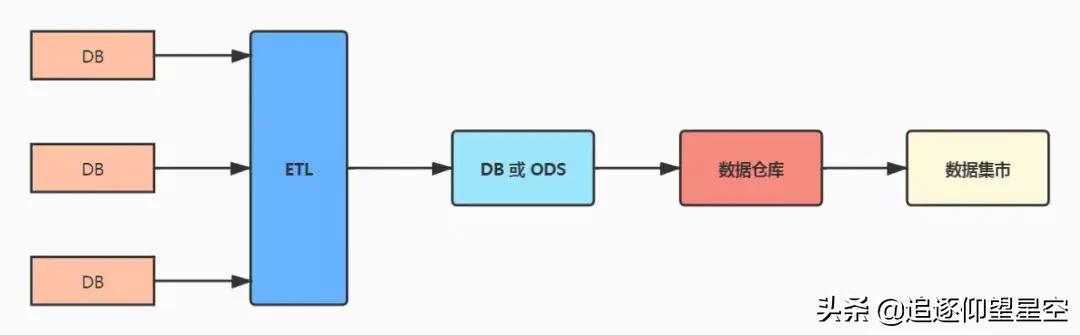
从这三个单词基本可以了解 ETL 的作用:将各个业务系统的数据,通过抽取、清洗、转换之后,将加工后的数据落地到数据库中(数据仓库);在这个过程中,ETL 可以将分散、零乱、标准不统一的数据整合到一起。
使用场景
我接触过的项目,使用 ETL 工具的场景有这个几种:
1. 报表、BI系统:
在公司建设的初期,业务比较少,系统也比较少,一台数据库就搞定了;随着公司业务的增加,业务系统被拆成很多系统;随着数据量的继续增加,单个系统的数据增加到一定程度的时候,也做了分库分表;
这时候领导、业务人员在用数据做分析的时候,数据来源可能是多个系统的多张表,这时候企图通过一个复杂的 SQL 跑出来结果就很困难了;通常公司会建立一个数据仓库,通过 ETL 工具把数据抽取到数据仓库中,再做数据的拟合和展示。
2. 跨系统的数据加工或查询:
我们现在所在公司,业务系统有几百个,由于业务流程比较复杂,前端系统在做业务操作的时候,在正式提交交易之前,有很多业务校验;
比如要查询客户在 X 系统的交易历史,在 Y 系统的交易历史,在 Z 系统的交易历史;那么就需要分别调用 X、Y、Z 系统的接口,这个对前端系统很不友好,那么通常的解决方案是什么?
- A 方案:做一个中间服务,中间服务去调用 X、Y、Z 系统的接口,客户端直接调用这个中间服务;这种方案只是把前端要做的事情,转移到了中间服务;
- B 方案:整合 X、Y、Z 三个系统,建服务中台;这种方法很好,但是极为难,对于很多公司来说,别说把 X、Y、Z 三个系统整合成一个中台系统,就是其中一个系统本身进行重构,都是非常困难的;
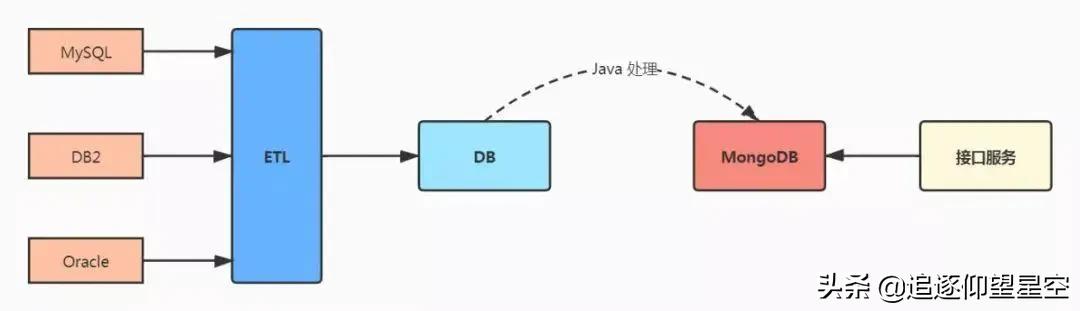
- C 方案:把 X、Y、Z 三个系统中需要的数据,通过 ETL 抽取加工到一个数据仓库中,对外提供服务;这个系统最大的好处是在不改造 X、Y、Z 三个系统的前提下,又可以实现跨系统的查询。
我们在 C 方案的基础上又往前做了一步,就是将落地后的数据又做了一次加工,将需要跨表关联的数据,提前关联好存入 MongoDB 中,对外提供查询服务;这样可以将多表关联查询,变成了单表查询。
吐数据 VS 抽数据
接上文中第二个例子中的 C 方案,有些同学可能会有个疑问:数据抽取,需要抽取哪些数据呢?为什么不让这些系统把数据吐出来呢?
答案也简单,“有的时候,数据不一定能吐出来”。
MySQL 数据库往外吐数据有比较成熟的中间件,比如 Canal,它可以通过监听 Mysql 的 binlog 日志来获取数据,binlog 设置为 row 模式,能够获取到每一条新增、删除、修改的日志,同时还能获取到修改前后的数据;
其他商用数据库,比如 Oracle、DB2 等,我也查阅过相关的资料,也是有触发器机制,可以当数据发生变化的时候通知出来,比如调用一段程序,将数据发送到消息队列中,再由其他程序监听消息队列做后续处理。
不管什么类型的数据库,这种“吐数据”的方案,对于基础设施的要求都比较高,并且对原有系统有一定的侵入性;所以我们采用了对原有系统侵入性更小的方案:主动抽数据。
ETL 方案的优缺点
1. 优点
- 侵入性较低,数据源系统只需要开通数据库的访问权限即可,为保证数据抽取对业务的影响,通常是访问源系统的备库,并且单独设置一个只读权限的数据库用户;
- 支持不同类型数据源的数据抽取,比如源库有 Mysql、DB2、Oracle,通过 ETL 也可以轻松搞定;
- 数据整合,将不同业务系统的相同数据整合在一起,比如有些系统 M/F 表示男女,有些系统 1/0 表示男女,ETL 在抽取加工后转换成统一的编码;
2. 缺点
- 比较致命的一个缺点,就是数据抽取和加工有一定的延迟,需要根据业务场景进行评估,是否接受这个延迟;
- 可能会受到源库表结构变化的影响;
- 如果源库中的表没有时间戳,或者时间戳不准确,那么增量抽取就变得很困难;
- 需要招聘 ETL 开发岗,从我目前的经验看,不是特别好招。