在写这篇文章之前,我一直在思考该用什么的方式能讲清楚前端为什么要向智能化方向切换的理由,真的反复思考很久,后来决定还是以我做前端的过去 10 年的所见所闻来做个解答吧,这样让大家也都更有些体感。
起源
这段是我跟前端的结缘,想必很多人也跟我一样,懵懵懂懂地就撞入了前端这个行业。
一脚入坑

我接触前端,那还是 2010 年的时候,在那个时候最火的是 网络三剑客 —— Adobe Dreamweaver、Adobe Flash、Adobe Fireworks。
这三款软件都很热门,第一款可以通过可视化编辑器拖拖拽拽、填填配配就可以搞定一张网页,虽然上手起来概念众多、也挺难用的,但至少是那个时代做网页最牛逼的软件了;
第二款是做 Flash 的,配备一门 ActionScript 的语言,当时网上下载了不少大牛做的很极客的 Flash 网站源码,不过代码读起来很吃力;
第三款是做海报的(因为海报图比较大、比较长,切割起来比较耗费内存,这块软件速度比较快)和 Gif 动画的,但我用的少,大部分时间都用 Photoshop CS4 来搞定。虽说这三款软件最火,但真正让我入坑前端(那个时候还没有“前端”这个称呼,有的就是“切图仔”)的理由,是因为我想当一位网页设计师。
当时,想当一位网页设计师的理由有二:
软件工程搞 Java、C++、C 真是挺枯燥无聊的,写一段程序,还得编译、部署,等上个两三分钟的,特别无语;而当初接触 Web 页面开发时(当时还是一位外教授课),发现网页这东西很神奇,在一个 Text 文本编辑器里敲上几行代码,改个扩展名,双击页面就展示出来了,这种所见即所得的美的视觉冲击力,当时让我向这个方向上蠢蠢欲动,埋下了祸根。在教育网庆幸地就是可以翻墙看了不少国外的网站,当时最大的感受就是美观、大气、留白充足,而国内的网页哪里是网页,UI 的设计简直龊的不要不要的,没什么美感,全是一堆文字 和 框,外加一堆闪来闪去的 gif(比如那个 “New”)堆砌,尤其是教育网的官网,那丑的简直不要不要的了。再加上当时的 QQ 空间很火,这块 DIY 自己的空间,但还是感觉不大气,所以当时就想着自己做出一款比较高端大气上档次的网页。大学期间,虽然自己学设计做网页这个想法被身边同学嘲笑说这应该是专科同学才去搞的东西,但的确还是坚持下来了。平时自己除了读专业课程和完成课程实践以外,就是在寝室、在图书馆、在选修课、实验室里抱着一堆影楼的 P 图视频宝典和一本影印版的厚厚的设计资料度过的。当时自学了 Photoshop ,也学会了设计中的三原色原理,并应用在班级日常校园种海报设计、照片美化等工作上,如今拿着单反拍个照 P 个图的本领也都那个时候积累下来的。
再然后就是在校园里找了个实验室的项目,跟一伙人做一个外卖网站,自己担任网页的开发部分。老实说那个时候对方都不信任我能搞定网页开发,毕竟我还是初级的小白。所以自己那个时候啃 W3C,在网上边学边做,虽然当时有个不错的 jQuery 的框架,但自己还是纯手工用 HTML4、CSS、Javascript 撸出了级联地域菜单选择器,而且 UI 也是自己设计的,顿时信心感爆棚,所以一发不可收拾的一个项目一个项目地走向了网页开发或者叫切图仔这个行业。 这大概就是我与前端埋下的不解之缘吧,算是一脚踏入了前端这个行业。
两脚入坑
而要说真正接触“前端”这 2 个字的时候,那还是在面试淘宝时面试官向我提起的。虽然当时还是听不懂前端到底是干嘛的,但一听面试官说能跟设计师一起工作,而且未来想做设计师也可以内转,我就没有再半点犹豫,当时一天就搞定了所有面试流程,签下了淘宝前端开发工程师的 Offer ,从此就两脚都踏入了前端这个行业了。

回顾:前端发展的黄金 10 年(浅水区)
当你真正从校园出来,沉浸于工作之后,就会发现时间过得速度远比你在学校里快了不止一倍,每时每刻都觉得时间不够用、业务完全做不完,感觉自己的时间都给了工作,我过去也在反思这个原因到底是什么,后来也渐渐想明白,这种快本身与互联网的发展相辅相成的,从 2G 到 3G,再到 4G,以及接下来的 5G、6G……,正因为互联网大潮的发展,以及我们这些推潮者的存在,我们的时间变快也就变得正常了。我知道很多人不理解,但在这个圈子里的人都会理解或有同样的声音存在。就比如以前端发展的这 10 年为例,你就会深有体会了。
以下就是详细介绍前端发展的这黄金 10年,有兴趣的读者可以细读,没有兴趣的可以通过这点概述绕过:前端在最初,仅仅是为了完成一张网页的开发,到后来,要能在同时完成 5 张、10 张甚至更多张页面的开发,对前端的挑战变大,所以前端作业内容从单纯的网页开发,拆分成模块式开发,拆分到前后端分离,过渡到可视化搭建系统等等,职能范围也从网页开发逐渐过渡到后端开发、全栈开发,领域范围也从网页开发细分到 PC 端开发、移动端开发、游戏/互动开发、Nodejs 开发、架构工程开发等,工程内容也从一段 jQuery 代码就搞定的阶段发展到前端也需要构建、打包、集成、测试、灰度等高度工程体系化的复杂程度。但生产力还以人肉为主,互联网前端行业还是劳动密集型作业方式。
阶段一:刀耕与火种 & 野蛮生长
2010 年的前端,IE6 还盛行,jQuery 是老大,YUI 虽然也不差,但用的人毕竟没有 jQuery 多。有个比较牛逼的工具叫 Firebug,这算是给前端的最大福利。这个时候的前端,在我看来应该还算刀耕火种阶段,虽然有 Dreamweaver 这样的网页可视化编辑工具,但产生的无用代码量真是挺多了,而且对接数据比较麻烦,维护成本也不低,在当时的网络条件下,用它的人可能也不少,但我一直不用它。
阶段二:模块化开发 & 框架升级
2011 年,来到阿里实习之后,发现天猫(当时还叫淘宝商城)的页面的确很高端、大气,而且也的确跟设计师在一起工作(当时还叫 UED),很兴奋。当时的前端规模不大(算上外包,15~20 人左右),YUI 在公司还比较盛行,KISSY 开始展露头角,看到前人大牛写的代码有条有理、的确非常膜拜,所以基本那半年的实习生活里大部分周末都泡在公司里或者加班或者自己学习前人的东西。与此同时,公司内还有一款非常牛逼的产品叫 TMS ,可以通过模块化以及模板化的思想,分分钟就可以搭出一张页面来,简直牛逼的不要不要的,那个时候淘宝商城的双 11(虽然很多人当时还把双 11 当光棍节)活动页面就是用这块大杀器搭建完成的。用模块化搭建的思路来解决页面批量生产的问题,这个思路在当时业界也算领先,而且这个思路一直延续到今天。所以如果阿里有个产品历史博物馆的话,TMS 绝对位列其中。

在 2011 ~ 2014 年之间的历史阶段里,模块化的思路占为主导。当时为了进行 Assets 资源加载器的设计,就制定了模块化的协议规范。当时比较流行的模块化协议就是 AMD(RequireJS)、CMD(Seajs 为代表)、KMD(Kissy 为代表)。在淘宝、天猫,Kissy 应用的很火,YUI 退出历史舞台,所以 KMD 主导天下;在支付宝及外部社区,Seajs 应用的很火,所以 CMD 主导天下,玉伯大大的名气和威望也在前端圈里特别高;而 AMD 在国外比较流行,但渐渐也被后来出现的 CommonJS 规范削弱了气势。

当时的前端借助模块化的思想和各路框架(YUI、jQuery、Kissy、……),来支撑着网页页面的生产,前端 Assets 资源已经不再跟服务端代码捆绑在一起发布了,但 doc 页面还在服务端的 web 容器内,前后端的生产需要联调、需要注意发布顺序。TMS 虽然好用,但还是在营销活动(比如 618、双 11)上优势比较强,数据还是偏向静态化的居多,在如频道、搜索、交易等这种产品态的复杂主链路上还起不到快速生产的作用。不过庆幸的是,那个时候的营销活动并没有那么密集,一年之内活动屈指可数,所以对前端的生产压力还没有那么明显。但痛苦在框架升级上,每年一次的 Kissy 升级,让所有业务的前端痛心疾首。
阶段三:浏览器加持 & 富体验化

伴随着浏览器大战,浏览器内核技术在向前发展(有兴趣地同学可以在网上自助看看浏览器的内核发展史,比如《全面了解浏览器(内核)发展史》),IE 逐渐跟不上 Firefox 、Safari 和 Chrome 的节奏。后起之秀 Chrome 非常关注 JavaScript 的引擎性能,觉得可以再提升 10 倍,所以自研一款高性能 JavaScript 引擎,名叫 V8,以 BSD 许可证开源,Chrome 在浏览器家族内的地位如日中天。给前端配套的 debug 工具链更加完善,通过控制台可以完成代码调试、性能检测、资源检测、网络检测、DOM 结构检测等等诸多工作, Chrome 在前端的眼里简直可以说是一款浏览器走天下,IDE 什么的完全通通不用。
因为 Chrome 的加持,前端的研发效能有所提升,外加 HTML5 + CSS3 诞生和浏览器对它的争先支持, Web 页面的性能体验也逐渐上了一个台阶,在网页上可以做的技术尝试也开始展露,如网页特效/动画、网页游戏。
阶段四:前后端分离 & 工程完善
这个思想的提出当时是一位阿里的前端高 P,这种思想的诞生目的就是为了解决前后端在 Web 容器上的过度耦合,导致前后端的研发效率相互制约,所以将这种耦合转变成对数据的耦合,面向数据编程,将 Web 部分彻底交给前端,这样前后端的研发效率会大有提升。
而这个思想的提出时机恰好是在 NodeJS 和 NPM 生态初步建立的阶段,阿里借助 NodeJS 做前后端的分离尝试,在后端诸多质疑声中,干掉了 PHP、废弃了 Java 的 Web 容器,一路拿下了前端在 Web 容器上的主动权。前端在 NodeJS 生态上,也开始有 express、koa、egg、begg 这样的 Web 应用框架开源,也开始有了借助 NodeJS 完成的工程脚手架套件(如 webpack ),同时也衍生了一个新的工种 NodeJS 开发工程师,基本阿里的所有 Java 中间件生态,在 NodeJS 生态上也有对应的一份了。

前后端分离,让前端主导 Web 容器,带来的直接益处就是前端可以从 Client 和 Server 两端进行一体化的生产工程设计,让前端的页面加载性能达到极致化。当然,前端职能的拓宽,也给前端带来了额外的工作负担,所以如果没有充分人力准备的部门,轻易不会尝试负责 WebServer 端,毕竟运维需要成本。但庆幸的是,随着 docker 容器化技术的发展和云基础设施运维能力的发展,从 IaaS 发展到 PaaS,再到 SaaS,服务端的运维成本大幅度降低,所以前端运维 WebServer 的成本就降低很多。
后话:如今发展到 FaaS 阶段,基本就是 Serverless 化的,运维基本对上透明,上层更加感知不到。
当然,前后端分离并没有对前端的研发效率上有太多的改观,倒是在前端工程体系上更加完善和健全。以前的前端可以被叫页面仔,但这个阶段前端已经不再是了,因为前端的工程体系(如 IDE、研发、构建、打包、集成、测试、灰度、生产服务等等)不比 Java 的差多少。
阶段五:终端碎片化 & 技术洗礼
2013 年,移动端兴起,阿里 All in Mobile,移动端浏览器的发展势弱,赶不上 App 的用户体验,多年在 PC 时代沉淀下的技术产物发现在移动端弱网的环境下难以应对,Mobile First 技术战略之下,很多基建又得从移动端开始重新设计。
比如:kissy 在移动端的 mini 版 kimi,但后来也因为 kissy 在业务前端的口碑形象下滑的厉害,以及社区内有 RN(React Native)和 Vue 的兴起,所以 kissy 的生态也在时代的车轮下渐渐消失。
再比如:上文提到的 TMS 系统,因为它对移动端的不适应,导致它在时代的车轮下渐渐消失,被新的产品替代,支撑住移动端的网页搭建。
随着 3G、4G 的发展和 iOS 和 Android 手机在市场的普及量大增,PC 业务主战场也逐渐过渡到移动端。前端的思维模式由 PC 转向了移动端,并向 App 的用户体验看齐。移动端的 HTML5 协议支持不完善,前端的生产配套不全,Android 的屏幕碎片化,所以那个时候的前端开发移动端页面适配的痛苦要远远超过 PC 时代。
阶段六:数据化驱动 & 框架之争

不过,庆幸地是有 Angular、React、Vue、RN (React Native) 这样的 MVVM 框架出现,让前端接受了数据驱动思想的洗礼之外,还借助 RN 完成了移动端的体验升级,包括后来的 Weex、Flutter。
在这个阶段,前端开始有了终端的底层架构组,开始构思前端页面在移动终端上的加载性能和用户体验表现。前端在移动端的研发上在 Web 和 Weex 容器上来回迁移和犹豫,增加了技术选择的负担,而且相互间无法复用。
所以为了解决多端复用的问题,Weex 又借助生态上的 Vue 框架,打通 webview 和 weex 两端,梦想着一套代码跑天下。但现实中就是打脸的,两种终端容器能力不对齐,相互制约,一套代码写得瞻前顾后。这个时候的前端,被终端技术折磨的苦不堪言。
但好在 Web 在移动端的发展越来越强,同时借助客户端的一些能力加持(如 hybird、cache、prefetch 等),web 页面的体验强到可以与 App 分庭抗礼。所以经历过煎熬的四五年时间,如今 web 的声音已经在移动端占主导地位。对应的移动端框架也确定下来。
同时,2016 年,小程序的概念开始提出到上线,一种轻 App 的开放解决方案开始在国内掀起浪潮,微信、支付宝、百度等一堆互联网大厂(包括如小米、华为等的手机硬件厂商)在这个大潮之下分食。所以一种小程序的新 DSL 诞生在前端眼前,前端要兼顾 web 及各个厂商之间的 小程序 DSL,痛苦又翻倍增加。有痛苦就有人解痛,像 WePY 、 mpvue 、Taro 等小程序框架如雨后春笋,相继出现(《小程序第三方框架对比 ( wepy / mpvue / taro )》)。
除了移动端,在 PC 的 C 端和中后台业务上,分别该用什么样的技术方案呢?要不要用 MVVM 框架呢?用React(包括 Preact)、Vue、Angular 具体哪个框架呢?
在经历过多方声音的反反复复多年的争吵下,最终总算确定了中后台全部采用 React ,PC 的 C 端采用跟移动端一样的同构方案。虽经历过几年的痛苦折磨期,但框架之争总算平静下来,前端的目光开始关注更上层的东西组件化物料(如 AntD、Fussion、ICE 中后台物料等)的建设以及前端行业领域的细分。
阶段七:领域细分 & 可视化搭建
经历过上述的争鸣和冷静之后,前端的行业领域开始更加细分,领域上层建设和深度建设也更在紧锣密鼓的进行着,除了上面提到的 NodeJS 领域方向以外,还有以下这样的垂直方向。
小前台
面向的是消费者端的 Web 与 轻 App 业务场景,在这个场景下,经历过多年营销活动的沉淀,面向运营、商家或 KOL 的页面的可视化搭建系统也非常成熟。所以营销活动基本靠这样的系统支撑。
中后台

面向的是企业 ERP、CRM 、OA 等业务场景,如供应链系统,在这个场景下,借助 AntD、Fusion、ICE 中后台物料,形成可视化的中后台搭建解决方案,为业务的前端、开发或产品角色提供一站式中后台生产解决方案。采用搭建,目的肯定是为了业务生产的提效。
数据可视化

面向的是企业的数据 BI 分析和可视化呈现场景,如 双 11 的阿里和商家的企业级数据实时大屏。在这个场景下,借助 echart、highcharts、 AntV 等数据可视化图表物料,形成一套数据可视化搭建系统,为业务的前端、开发或产品角色提供一站式数据可视化图表生产解决方案。采用搭建,目的肯定也是为了业务生产的提效。
互动内容
AR、VR、3D、网游、短视频、直播(WebRTC)等新技术在 web 上的衍生和普及,更多富导购的交互形式层出不穷,所以这个方向就是在面向未来的用户富交互体验做投资建设。
……
还有更多的垂直领域,在此不再细说。
回看这10 年,是互联网发展和终端发展最快的 10 年,也是前端发展最快的 10 年,更是前端程序员掉头发、白头发最快的 10 年。因为没有哪个技术领域,可以层出不穷地出现新轮子、可以反复不断的推翻升级升级推翻,但庆幸的是,经历过百家争鸣之后的前端行业在各个领域内的建设深度也愈发地趋渐成熟。与此同时,大家也会发现,这些复杂的建设也都是围绕着能解决业务问题和能提升自身生产效率的角度出发的。

展望:前端发展的未来 10 年(深水区)
解决业务问题不说,那么前端为什么要关注生产效率问题呢?
因为这直接与阿里的业务体量相关,阿里每一年的业务体量都是相比去年翻番的(比如出海、下沉、新业务……),所以如果生产力效率跟不上业务的发展节奏,那么在市场竞争上就不占优势,以 2019 年三四线下沉市场高度竞对的场景为例,如果前端撑不住业务发展的节奏,还是慢慢悠悠地搞生产,那么企业就很难占据市场了。
所以,每个前端身上背负的都是业务体量的成倍增加,如何能快速支撑住业务发展以及如何帮助业务突围和增长(2017 年手机出货量触顶下滑,移动端的自然用户增长红利达到顶峰,可以从《用户流量红利消退的下半场,淘宝如何保持高速增长?》便可感知到)是我们每时每刻都在思考的问题。
前端已到瓶颈!
我们知道,即便工程化能力已经成熟,但还是解决不了的问题就是“生产效率”的问题,试想:
假设 1 个中等水平的前端产出一张功能齐全的页面需要 1 周时间,1 个牛逼的前端可能只需 2 天时间;而即便都雇佣牛逼的前端,1 个前端单打独斗一周之内最多也就 4 张页面产出,如果仅是生产 10 张页面,那么雇佣 1~2 个牛逼的前端一周之内就搞定了,但如果是生产 100 张、1000 张页面呢?这个时候雇佣多少前端比较合适呢?高端人才的紧俏和招人成本的控制,都会导致厂内的前端的业务压力倍增。
解铃还须系铃人,所以业内开始不断地涌现 hardcode 向 lowcode 方向转变的提效热潮。不说外界,单以阿里为例,面向中后台、C 端、数据可视化方向的 lowcode 平台就层出不穷,虽说上手复杂度很高(毕竟解决问题的复杂度摆在那里,就像 Photoshop 一样),但也都在趋于成熟。
可这样就高枕无忧了嘛?其实并没有,因为业务的迭代速度太快了,即便有这些平台存在了,依然还是解决不了业务上的燃眉之急、前端效率问题依然是业内的瓶颈。
以我带的团队为例,我们服务的每一条线下的业务量和复杂度都是居高不下(每条线承接的是千万级流量,所以业务复杂度自然会高),除了日常产品迭代,每月至少有 1~2 次的营销活动同时进行,即便用了上述的 lowcode 产品,但还是解不了业务方频繁上诉要人的困局,甚至排期、砍需求这种传统小伎俩如今也对业务方没有药效了。
怎么办?一人难敌四手,更何况是一堆数都数不过来的手了。
前端如何突围?
要讲清楚这一块,我们换个视角看看。众所周知,市场是有清浊、淘汰机制的,任何一个行业都不是一成不变的,只要有先进的出现,那么就势必会将落伍的清理淘汰掉,而这个过程自变量仅是时间。
就像电商互联网兴起的那一刻,有多少实体从业者会意识到自己的饭碗会跟不上时代?就像移动端来临的那一刻,有多少公司及个人还在沉淫在 PC 的时代产物上,再后知后觉地意识到落后时已经被竞争者甩了好几条街了。
就像当 iOS、Android App 生态刚开始兴起阶段,不断地有客户端的人才在向市场输入,而今当 App 在市场饱和、用户分配在终端上安装的 App 数量有限,以及移动端 Web 和轻 App 技术的飞速发展等客观因素冲击下,客户端的从业者发现保住自己的饭碗越发的困难了。
就像 AI、区块链兴起,有一大批的算法从业者和新技术的创业公司输出到市场,而经过市场竞争的洗涤下,又发现算法人才饱和过剩、创业公司也死了一大片。
所以要看一个行业的未来发展怎样,就看这个行业的人才目前和未来在市场上被密集需要的地方在哪、规则最混浊或混乱的地方在哪。如果说这个行业的规则出奇地清晰、人才的供给又出奇的冷静,那么基本上来说,这个行业在市场的发展已经达到平衡状态,而能打破这种平衡重新建立平衡的也肯定是另外的行业的发展渗入。
所以回归到我们所处的前端行业,如今前端人才被需要的肯定是在互联网公司,尤其是大厂,因为业务发展需要,且被需要的很密集(劳动密集型产业),而且这个行业恰巧也是发展规则相对混乱的。为何混乱呢?一方面是因终端多元化趋势严重,比如智能穿戴设备和 IOT 智能家居、智慧医疗、智能建筑等新兴产业的市场冲击,另一方面是因业务的发展形态、发展规模、发展距离(国内到国外)等因素的影响,都导致着过去的终端的技术规则无法适应到新兴终端领域内,所以规则在变、技术在变、框架在变、从业者的领域也在变。
所以从这个角度看前端的职能领域只会越来越宽,人才的需求量只会越来越大,供给的能力要求只会越来越高。可以说这是市场对前端这个行业利好的信号,但同样也是对前端这个行业压力提醒的信号,如果在这个市场内的前端不能很好的解决市场压力问题,一旦有新兴技术手段形成的新生产力出现,那么前端的这个香饽饽的行业饭碗也就不保了。市场就是这样冷静残酷的,当市场出清淘汰一个行业的时候或许连一声招呼都不会打,没有为什么,这是发展的必须。
如今我们看清形势,再反观我们的生产力手段,可以说还是人肉劳动密集型的,就算招再牛逼的人才进来,如还是以这种的生产手段生产,那么早晚都会被淘汰,不管有多资深,哪怕是专家、研究员。所以前端发展到这个档口下,看似成熟,实则危机四伏。
我们需要反思,更需要一种全景视角的突破和自我革命。与其让别人革我们的命,那么真不如我们自己革自己命。所以接下来前端的发展势必会面临着一个最习以为常却又最为关键的挑战 —— 前端生产效率该如何翻倍的提升?
历史的经验告诉我们,一个行业的生产供给能力翻倍,那么一定跟这个行业的工艺手段脱不了关系。比如传统制造业制造一款鞋子、织一块布,都是人手工的,当这种供给达到瓶颈之后,就开始出现机械化来辅助人来生产,机械化达到一定程度就是自动化,自动化就可以完全脱离人工进行生产。
同样的道理,前端目前的生产工艺还是人肉的,即便有一定的程度的 lowcode 产品手段来辅助前端释放生产压力,但还是解决不了供不应求的问题,所以没有别的办法,只有一条路就是去人肉,改成完全自动化的生产手段,只有让供给能力远远超越需求的市场增长指数,那么才能彻底解决供不应求的问题。
那么,前端该如何将生产手段提升到自动化阶段呢?
首先,我们能想到的生产手段上肯定不能重度依赖人,那么剩下的也仅有机器,对于我们而言,肯定就是计算机了。
其次,我们要想的问题是该如何用计算机来解决我们所面临的生产问题,想到第一步不难,而最难的恰巧就是这一步。该怎么解呢(how)?
调研发现,市面上就 2 种形态的解决思路,一种就是堆人的 hardcode 方式,包括传统的组件化生态,也都停留在这个阶段上;再有一种解法是 lowcode 的方式,或者辅助自己或者辅助其他角色来做生产(换一句话来说就是生产关系转移到其他角色身上),这种方式在特定领域内能一定程度上提效,但一旦领域拓宽或稍有移植,就会面临着不适应,用它工作量反而比 hardcode 增加很多。目前我们就在第 2 阶段,但生产效率问题还是非常突出。所以我选择的解法是 nocode,虽然这个词也不是我新创的,但这个词的涵义足以表达我对生产力供给能力提升下一个阶段的看法。而能帮助前端实现 nocode 解法的技术,一定就是 AI(准确来说是机器学习)。Why?
互联网的发展就是带来了海量的数据,依靠人脑已经无法去分析清楚一个行业的特征了,至少我们都是凡人大众,那种类似爱因斯坦的天才毕竟还是少见,不可能哪个行业都要等着爱因斯坦出现才能找到解决方案。所以凡人大脑做不到的事情我们就交给计算机来做,如今的 云计算发展和 AI 发展,已经降低了我们应用 AI 来解决我们问题的门槛,所以入行 AI 也是迟早的事,不可能每天都蒙着眼睛装看不到,而且也一定程度上得承认 AI 比我们更聪明,所以逃避不了的事实我们干脆一些接受好了。AI 就是为海量数据和复杂问题而生的。
思维方式转变
那么前端究竟该怎样加持 AI 的能力呢?
这个问题对纯前端从业者来说很难,对算法从业者来说也很难,但对既懂前端又会算法的从业者来说就不难了。为了讲清楚这个问题,那么我首先来讲解下这两者解题思维的惯性差异是什么,帮助大家先从思想上进行转变,这样大家也就更易接受一些。
我们以一个具体的案例为例:当你的产品经理让你做一款类似下图这样过障的小游戏,管道洞口高度固定,且是匀速向左移动的,小鸟只会上下,同时受重力影响会跳动,你如何让这只小鸟自己会躲避障碍成功过关呢?
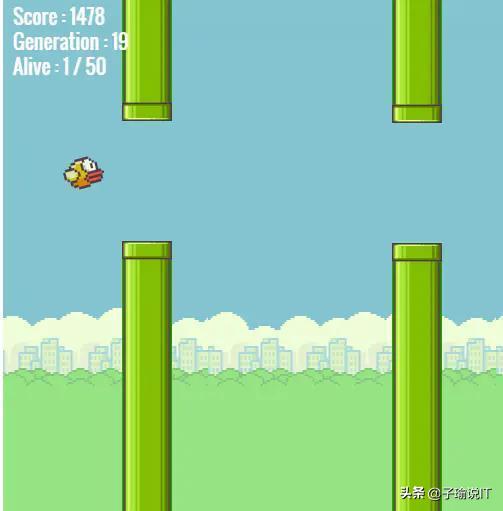
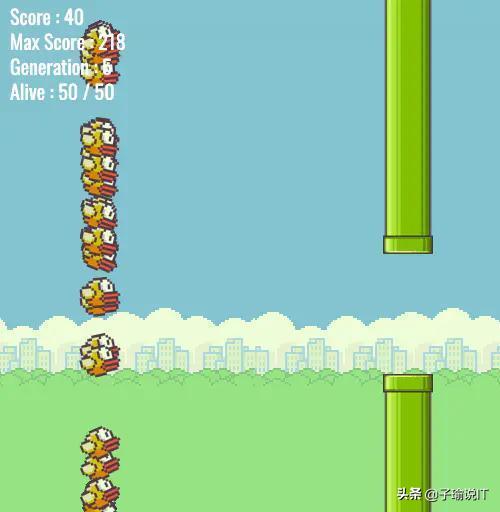
如果前端看到上面需求时,他的思维惯式一般是这样的:首先,要有一张画布,上面有小鸟、管道这两种对象(Object),小鸟对象中有 x、y、width、height、alive 等属性,x、y 代表它的水平和垂直位移,width、height 代表小鸟自身宽高,alive 代表小鸟的生死;管道对象中至少有 x、y、width、height、speed 5 个属性,x、y 代表管道的水平和垂直坐标位置,width、height 代表管道的宽高,speed 代表的是管道向左的移动速度。其次,要根据管道的移动速度给小鸟建立一个雷达预警机制,通过轮询的方式不断地探测正前方是否有障碍物,一旦有了就不断地在垂直方向上上下位移来做避障。最后,依次类推的方式达到终点。
如果算法看到上面需求时,他的思维惯式一般这样的:首先,需要找一款模型,拿 network 为例,可以利用遗传算法来解决上面的问题,具体就是通过 50 代小鸟不断地尝试碰撞,将每一代失败的小鸟的基因记录下来,然后遗传给下一代,形成遗传记忆,这样小鸟就不会以失败的方式过障,以此类推,直到没有失败的小鸟出现,那么成功的基因就训练完毕,这样的一代小鸟就可以完全过障了。
大家可以看到,前端的给的解题思路的代码里是有具体交代小鸟应该怎样判断过障的;而看算法解题思路的代码里其实并没有具体教小鸟过障的代码逻辑,有的只是将一些特征和反馈抽取传递给到 network,而真正的过障判断过程是模型去做的。而这就是这两种思路的关键差别,准确说是 程序员 和 AI 算法工程师的思维惯式差别,程序员的脑海里有着“我能用代码定义世界”的思维,而 AI 算法工程师脑海里有着“我该用什么样的数据训练模式让模型自己尽快掌握对错”的思维。前者是一种由自己来解问题的主观视角,所以写的代码纯粹是翻译给计算机要怎么去解这个问题;后者是一种由机器来替我解决问题的客观视角,所以写的代码纯粹是怎样把问题抛给计算机,并告知输入及结果对错,至于计算机是怎么解决这个问题的过程和规律算法工程师都不关心,只关心结果。
看到这里,想必大家对 2 种思维模式有了一个切身的体感,如果还有不太理解的,也可以看 甄子 老师的《前端智能化—思维转X变之路》文章,这更是对这个思维差异做了更深入的介绍。
重新审视求解
那么既然知道了 2 者的差异,我们就可以将前端领域内遇到的生产效率问题以最新的视角重新进行审视了。
前端,里面的关键字是“端”,所谓的“前”就是交代离用户最近的地方。所以用户接触到的终端(包括各种异形屏的、没屏幕的仅有传感器的终端等等)上面所呈现的任何人机交互内容(可视觉传达、听觉传达、肢体传达、甚至可能嗅觉传达等等)都可以认为是前端职责范围内的工作。面对这种形式多样的终端,要想快速产出人机交互的内容,我们用 AI 该怎么做呢?
鉴于话题有点大,我们还是聚焦在 Web 页面上(其他的以此类推),如果借助 AI 实现高效地生产呢?
一种思路是,首先,聚焦在网页上能呈现的内容形态看看到底有哪几种(空间轴上的语言),比如文字、图片、视频(视频可以理解为图片的逐帧动画,加上音频)、音频;然后,我们再看下网页上什么样的内容是经常变化的(时间轴上无序状态),什么样的内容是通过交互方式产生变化的(时间轴上的有序状态)。最后,我们的生产策略是,优先考虑将一组时间轴上的训练数据喂给一个模型让它识别出时间轴上的变化内容,然后再借助 CV 或 NLP 模型针对变化的内容进行实体识别(实体识别可能具体到一系列的模型存在,比如细化到商品图识别模型),再然后借助另外的 CV 或 NLP 模型来识别时间轴上不变的内容(往往这部分内容就是页面布局和容器框架),再通过一系列实体识别模型来做页面结构代码上的映射(高维空间向量余弦值相等)。理论上来说,如有大量的训练样本数据,那么模型针对时间轴上的有序状态(即事件响应)也是可以慢慢自己学习出规律出来的。
上面这种思路是纯算法的思路,其中没有借助前端的任何思维模式来影响,但具体效果怎样和实施难度上有多大呢,目前还不好说,至少我们自己也还没开始这种尝试。
也许上面思维未来是对的,但今天来说,前端还没有准备好,还在一步步进行思维上的转变和迭代,这的确是需要一个过程。而且机器学习也不是万能的,它受模型的制约因素很大,而模型往往也是一种算力的象征。我们可以把机器学习比作是一个拥有高复杂度并行密集计算能力(高维空间上的矩阵计算)的统计学计算器,而模型就是这款计算器的内核。也许它能在背后计算出
E=MC2
这样的宇宙规律,但至少也是进行了深度计算的,而这种深度的计算需要的就是海量的样本。而样本就是这款计算器内核塑造成型的灵魂,但这种海量样本的制造工作也绝非是一朝一夕依靠一个软件工程出身的技术人员搞得定的。样本本身就是数据,所以一定要有存量的数据才会有往深度学习方向上发展的可能性。否则人肉制造的样本,要不质量太差(不够客观)、要么就是量的规模不够。当然,也可以先把计算器搭起来,至于样本可以随着时间进行积累,这样的办法也不是不可以,就是等待的时日可能比较长,没法立竿见影收到奇效。
所以,针对商业行为来说,我们至少得有 2 套方案,一套是长远的(如上的方案)的准备,一套是短期眼前的方案。如果做短期的,就借助规则系统 + 机器学习的混合方式来做方案。但不管哪种,样本问题都是要解的。2 套方案也是 2 种选择,也许你还有第 3 种选择,都是选择,所以多与少没有什么差别,只是看能在选择之后投入多少和坚持多久。这种投入就涉及到知识和技能的储备了,所以前端至于前端想解决问题,还是得尽快上手机器学习。至于具体怎么上手在此就不做过多介绍了,网上的课程有很多,也可以看西瓜书上手,但关键是动手。可以先从 CV 领域入手,NLP 工程对个人来说单机部署有点难,得借助云(比如谷歌的 TPU 平台)。
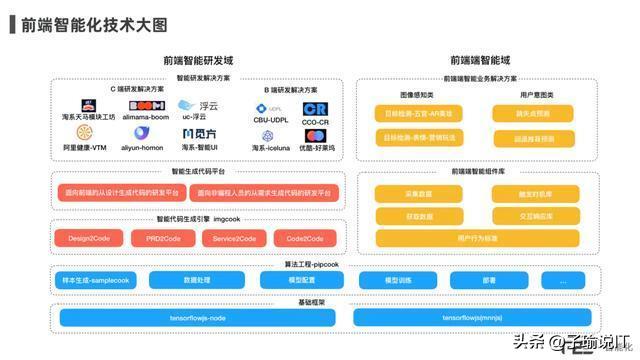
长远来看,前端 + AI 的这种前端智能化方向肯定是持续存在的,前端也会因为 AI 能力的加入,会产生诸多不一样的生产力变化(比如上图所标之处)。这种变化可能是阶段性的,也可能是终极的,总之生产力会慢慢向计算机身上过渡,前端做的工作是驱动这一切的更深层工作。这个方向没有退路,也绕不过去(专家系统不可能无敌),所以要解的问题直到彻底解决为止。