随着互联网的兴起,Web技术逐渐成为主流,各种技术流派蓬勃发展,当Web遇上鲲鹏又会发生哪些事情?
金蝶天燕作为中国领先的软件基础设施提供商,其业务主要涵盖政府财政财务应用、政务大数据服务、云基础设施等领域,在共建“鲲鹏生态”的过程中,如何才能提供更高的效能,将由金蝶天燕首席架构师马震为大家带来精彩分享。
一、Web服务器架构分解
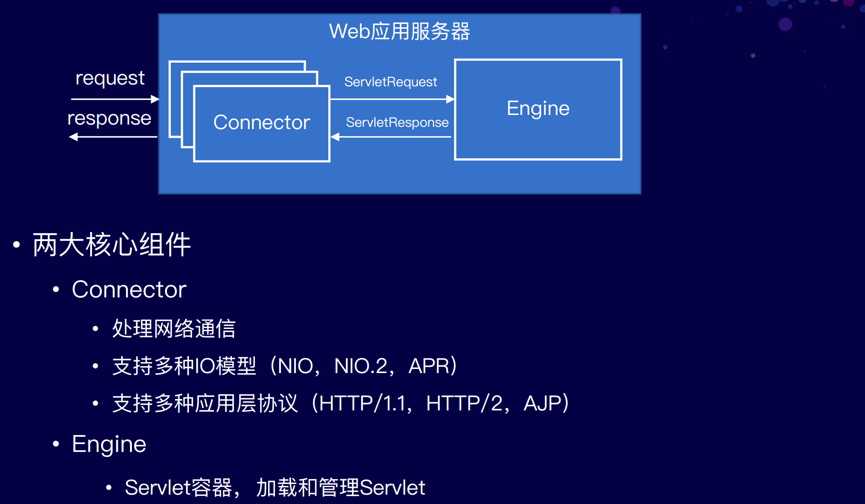
Connector和Engine是Tomcat最核心的两个组件。
Connector负责处理网络通信,以及应用层协议(HTTP,AJP)的解析,生成标准的ServletRequest和ServletResponse对象,然后传递给Engine处理。每个Connector监听不同的网络端口。
Connector支持多种 I/O 模型:
- NIO:使用Java NIO实现
- NIO.2:异步I/O,使用JDK NIO.2实现
- APR:使用了Apache Portable Runtime (APR)实现
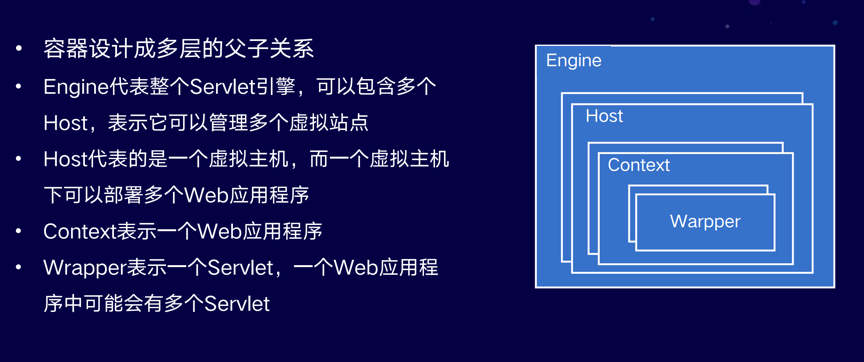
Engine代表整个Servlet引擎,可以包含多个Host,表示它可以管理多个虚拟站点。Host代表的是一个虚拟主机,而一个虚拟主机下可以部署多个Web应用程序,Context表示一个Web应用程序。Wrapper表示一个Servlet,一个Web应用程序中可能会有多个Servlet。
二、Web调优与加速技术
对于跑在Web容器里的应用进行调优,首先要对应用的性能进行剖析。Linux平台性能分析的技术和工具可以分为以下四类:
1. Counter:

内核维护各种统计信息就会被称为Counter,它用于对事件进行计数,例如网络接收数据包的数据量,发出的磁盘I/O请求,以及执行的系统调用次数,均用作统计次数,而常用工具是vmstat、mpstat、iostat、netstat。
2. Tracing:

是收集每个事件的数据进行分析,Tracing会捕捉所有事件进行分析,对CPU的开销消耗较大,例如常用的TCPdump会把网络通讯包根据设置的条件全部抓包,包括blktrace对block进行Tracing,包括strace对系统调用进行的Tracing,属于常用的Tracing工具。
3. Profiling:

Tracing会抓取所有数据,而Profiling只进行采样。Profiling 是通过收集目标行为的样本或快照,来了解目标的特征。Profiling可以从多个方面对程序进行动态分析,如CPU、Memory、Thread、I/O等,其中对CPU进行Profiling的应用最为广泛。
CPU Profiling原理是基于一定频率对运行的程序进行采样,来分析消耗CPU时间的代码路径。可以基于固定的时间间隔进行采样,例如每10毫秒采样一次。也可以设置固定速率采样,例如每秒采集100个样本。
CPU Profiling经常被用于分析代码的热点,比如“哪个方法占用CPU的执行时间最长”、“每个方法占用CPU的比例是多少”等等,然后我们就可以针对热点瓶颈进行分析和性能优化。
Linux上常用的CPU Profiling工具有:perf的 record 子命令和BPF profile。
4. Monitoring:

系统性能监控会记录一段时间内的性能统计信息,以便能够基于时间周期进行比较。这对于容量规划,了解高峰期的使用情况都很有帮助。历史值还为我们理解当前的性能指标提供了上下文。
监控单个操作系统最常用工具是sar(system activity reporter,系统活动报告)命令。sar通过一个定期执行的agent来记录系统计数器的状态,并可以使用sar命令查看它们。
本文主要讨论如何使用perf和BPF进行CPU Profiling。
perf:

perf最初是使用Linux性能计数器子系统的工具,因此perf开始的名称是Performance Counters for Linux(PCL)。perf在Linux2.6.31合并进内核,位于tools/perf目录下。
随后perf进行了各种增强,增加了tracing、profiling等能力,可用于性能瓶颈的查找和热点代码的定位。
perf是一个面向事件(event-oriented)的性能剖析工具,因此它也被称为Linux perf events (LPE),或perf_events。
perf的整体架构如下:
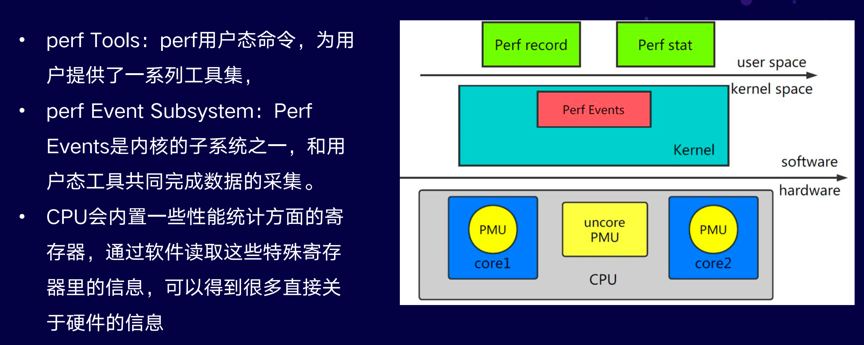
perf 由两部分组成:
- perf Tools:perf用户态命令,为用户提供了一系列工具集,用于收集、分析性能数据。
- perf Event Subsystem:Perf Events是内核的子系统之一,和用户态工具共同完成数据的采集。
内核依赖的硬件,比如说CPU,一般会内置一些性能统计方面的寄存器(Hardware Performance Counter),通过软件读取这些特殊寄存器里的信息,我们也可以得到很多直接关于硬件的信息。perf最初就是用来监测CPU的性能监控单元(performance monitoring unit, PMU)的。
perf支持多种性能事件:
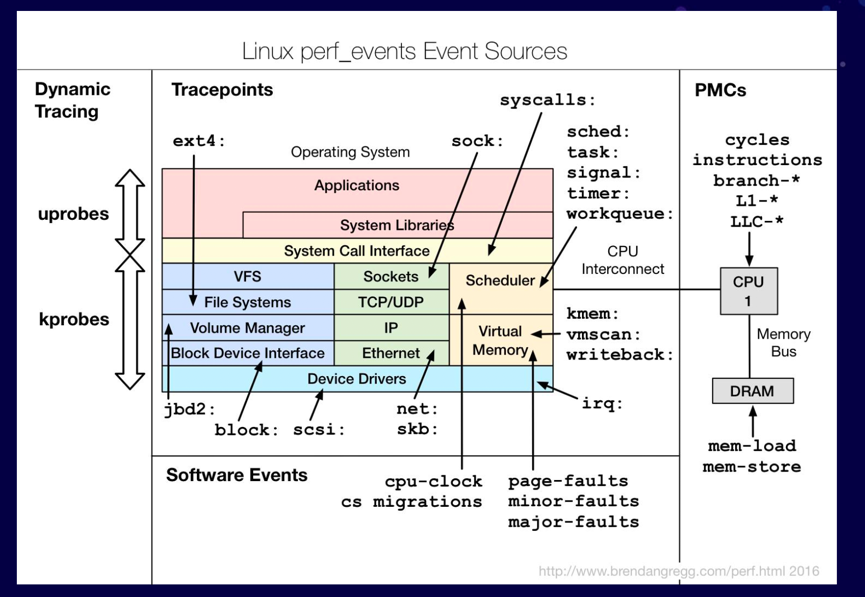
这些性能事件分类为:
- Hardware Events: CPU性能监控计数器performance monitoring counters(PMC),也被称为performance monitoring unit(PMU)
- Software Events: 基于内核计数器的底层事件。例如,CPU迁移,minor faults,major faults等。
- Kernel Tracepoint Events: 内核的静态Tracepoint,已经硬编码在内核需要收集信息的位置。
- User Statically-Defined Tracing (USDT): 用户级程序的静态Tracepoint。
- Dynamic Tracing: 用户自定义事件,可以动态的插入到内核或正在运行中的程序。Dynamic Tracing技术分为两类:
- kprobes:对于kernel的动态追踪技术,可以动态地在指定的内核函数的入口和出口等位置上放置探针,并定义自己的探针处理程序。
- uprobes:对于用户态软件的动态追踪技术,可以安全地在用户态函数的入口等位置设置动态探针,并执行自己的探针处理程序。
perf的功能强大,支持硬件计数器统计,定时采样,静态和动态tracing等。本文只介绍几个常用的使用场景。
1. Couting Mode:
使用perf的stat命令可以收集性能计数器统计信息,精确统计一段时间内 CPU 相关硬件计数器数值的变化:
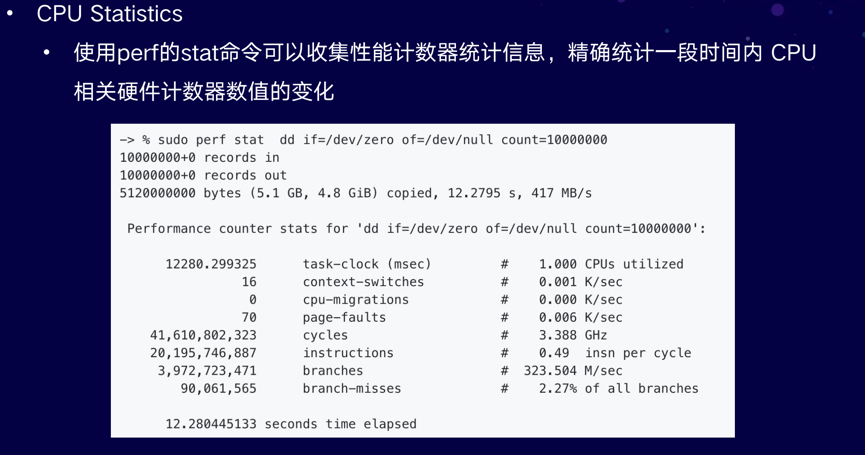
上图所示,通过perf stat执行一个命令,执行完毕后,可以看到命令执行时长12秒,同时显示上下文切换次数、CPU周期次数,以及多少指令和分支,可从中获取更多帮助信息。
2. Sampling Mode

可以使用perf record以任意频率收集快照。这通常用于CPU使用情况的分析。
- sudo perf record -F 99 -a -g sleep 10
对所有CPU(-a)进行call stacks(-g)采样,采样频率为99 Hertz(-F 99),即每秒99次,持续10秒(sleep 10)。
- sudo perf record -F 99 -a -g -p PID sleep 10
对指定进程(-p PID)进行采样。
- sudo perf record -F 99 -a -g -e context-switches -p PID sleep 10
perf可以和各种instrumentation points一起使用,以跟踪内核调度程序(scheduler)的活动。其中包括software events和tracepoint event(静态探针)。
上面的例子对指定进程的上下文切换(-e context-switches)进行采样。
perf record的运行结果保存在当前目录的perf.data文件中,采样结束后,我们使用perf report查看结果。
交互查看模式:
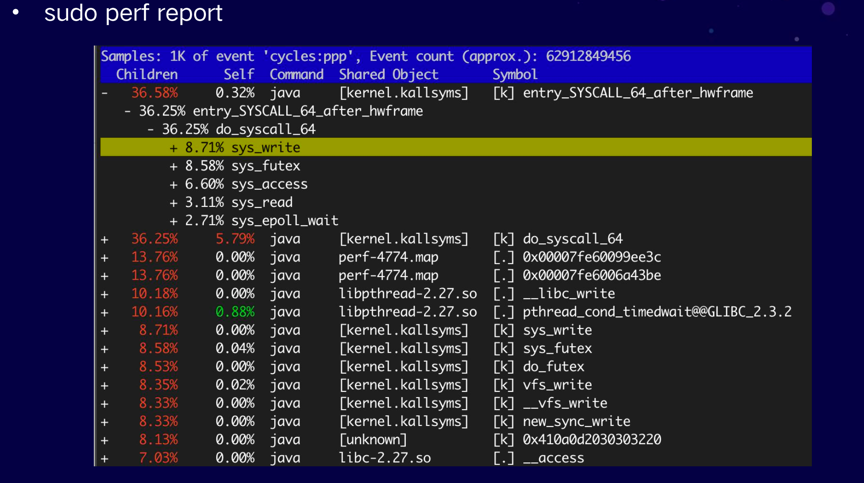
直接执行perf report,将采样数据进行加载,此时运行的是交互式模式,针对不同的代码路径,统计出百分比,前缀带+号的可通过回车进行路径的展开。
通过交互模式进行分析,可先从占用CPU时间最多的代码路径开始分析,看哪里占用的CPU时间多,是否能够进行优化。
统计模式:
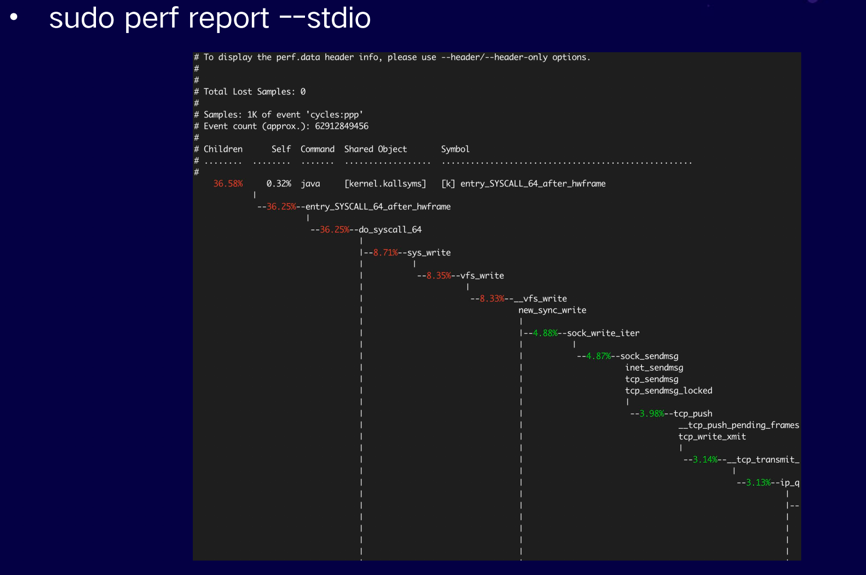
使用--stdio选项打印所有输出。运行结束后,会将所有的代码路径展开,每一个代码路径上的CPU的消耗时间都会显示出来。
BPF:
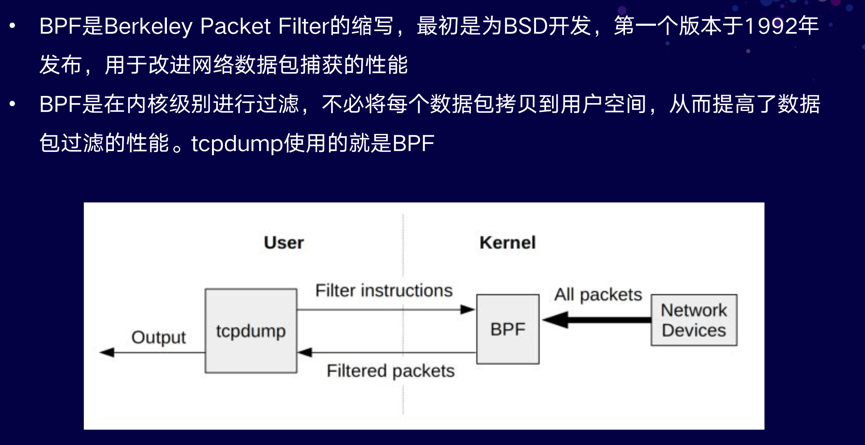
BPF作为系统级的性能分析工具,最初是为BSD开发,是用来改进网络数据包捕获性能的工具。
BPF是运行在内核级进行过滤,无需将数据包拷贝到用户空间,因为它在内核可以直接过滤,所以提高了数据包过滤的性能。常用的tcpdump内部使用的就是BPF。

2013年BPF被重写,被称为Extended BPF (eBPF),于2014年包含进Linux内核中。改进后的BPF成为了通用执行引擎,可用于多种用途,包括创建高级性能分析工具。
BPF允许在内核中运行mini programs,来响应系统和应用程序事件(例如磁盘I/O事件)。这种运作机制和JavaScript类似:JavaScript是运行在浏览器引擎中的mini programs,响应鼠标点击等事件。BPF使内核可编程化,使用户(包括非内核开发人员)能够自定义和控制他们的系统,以解决实际问题。
BPF可以被认为是一个虚拟机,由指令集,存储对象和helper函数三部分组成。BPF指令集由位于Linux内核的BPF runtime执行,BPF runtime包括了解释器和JIT编译器。BPF是一种灵活高效的技术,可以用于networking,tracing和安全等领域。我们重点关注它作为系统监测工具方面的应用。
BPF的优势:
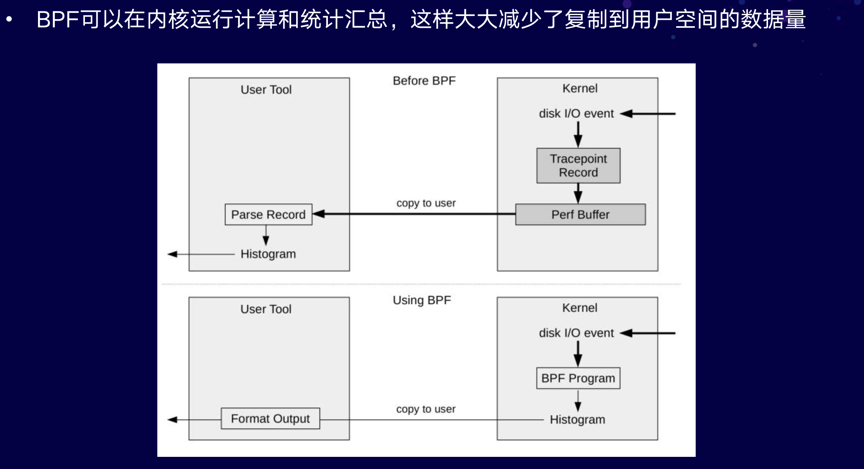
由于BPF的迷你程序是运行在内核,所以可在内核进行计算的统计汇总,以此大幅减少复制到用户空间的数据量。
BPF已经内置在Linux内核中,因此你无需再安装任何新的内核组件,就可以在生产环境中使用BPF。
BCC和bpftrace:
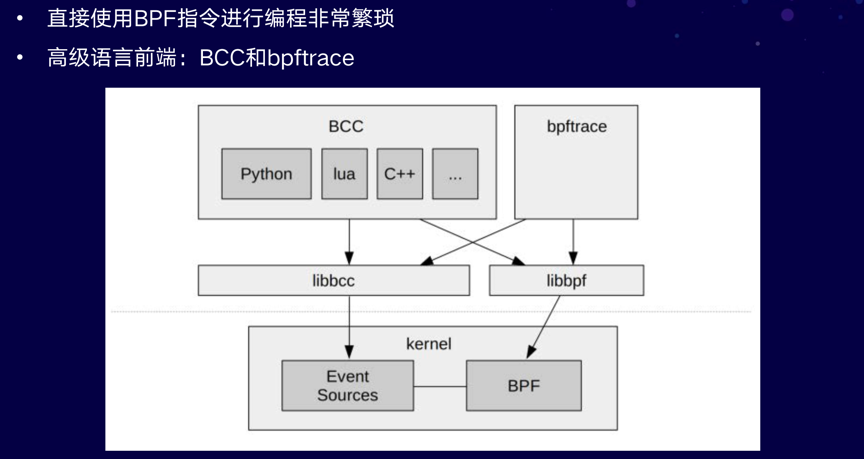
直接使用BPF指令进行编程非常繁琐,因此很有必要提供高级语言前端方便用户使用,于是就出现了BCC和bpftrace。

BCC(BPF Compiler Collection) 提供了一个C编程环境,使用LLVM工具链来把 C 代码编译为BPF虚拟机所接受的字节码。此外它还支持Python,Lua和C++作为用户接口。
bpftrace 是一个比较新的前端,它为开发BPF工具提供了一种专用的高级语言。bpftrace适合单行代码和自定义短脚本,而BCC更适合复杂的脚本和守护程序。
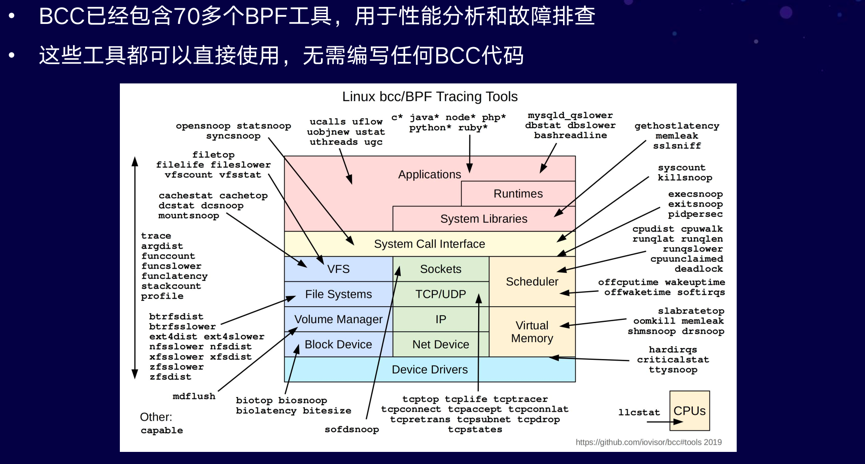
BCC已经包含70多个BPF工具,用于性能分析和故障排查。这些工具都可以直接使用,无需编写任何BCC代码。
BCC已经自带了CPU profiling工具:

一般的CPU profiling都是分析on-CPU,即CPU时间都花费在了哪些代码路径。off-CPU是指进程不在CPU上运行时所花费的时间,进程因为某种原因处于休眠状态,比如说等待锁,或者被进程调度器(scheduler)剥夺了 CPU 的使用。这些情况都会导致这个进程无法运行在 CPU 上,但是仍然花费了时间。
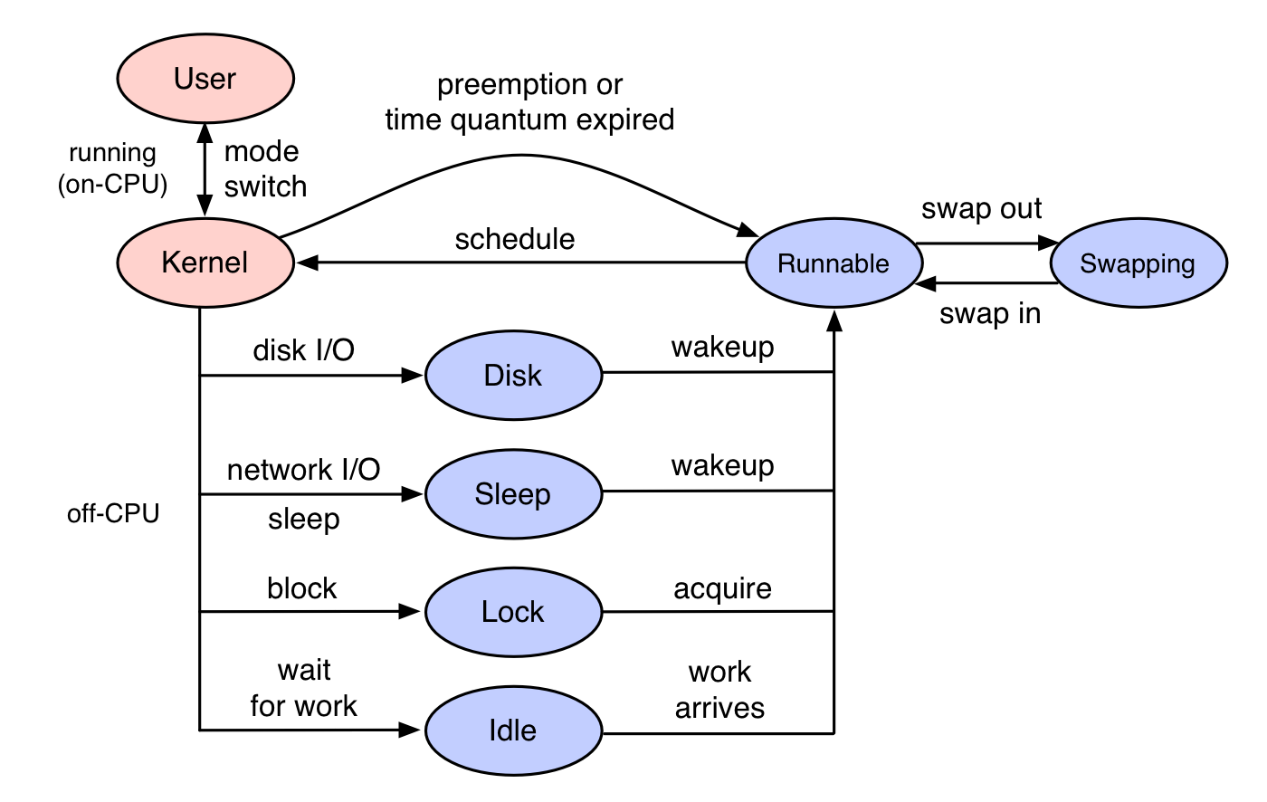
off-CPU是针对on-CPU的补充,on-CPU分析的是什么正在CPU上运行,off-CPU分析的是进程由于某种原因处于休眠状态,如磁盘阻塞、等待网络事件、被锁阻塞或时间片用完而被切换。此时虽然没有在CPU上运行,但仍然花费时间,如果通过off-CPU跟on-CPU相结合,即可了解线程所有的时间花费,更为全面地了解程序的运行情况。
抓取的采样如何更好地展示与分析——火焰图:

火焰图是Brendan Gregg发明的将stack traces可视化展示的方法。火焰图把时间和空间两个维度上的信息融合在一张图上,将频繁执行的代码路径以可视化的形式,非常直观的展现了出来。
火焰图可以用于可视化来自任何profiler工具的记录的stack traces信息,除了用来CPU profiling,还适用于off-CPU,page faults等多种场景的分析。本文只讨论 on-CPU 和 off-CPU 火焰图的生成。
要理解火焰图,先从理解Stack Trace开始。
1. 何为Stack trace:

Stack Trace是程序执行过程中,在特定时间点的函数调用列表。例如,func_a()调用func_b(),func_b()调用func_c(),此时的Stack Trace可写为:
func_c
func_b
func_a
2. profilingStack trace的含义是什么:

我们做CPU profiling时,会使用perf或bcc定时采样Stack Trace,这样会收集到非常多的Stack Trace。前面介绍了perf report会将Stack Trace样本汇总为调用树,并显示每个路径的百分比。火焰图是怎么展示的呢?
考虑下面的示例,我们用perf定时采样收集了多个Stack Trace,然后将相同的Stack Trace归纳合并,统计出次数。
如图右侧所示,共采集了10个样本,第一个代码路径func_a调用func_b调用func_c,有7个样本。第二个路径a调用b有2个样本,第三个路径有1个样本。
此时,将相同的Stack trace进行归纳合并,统计成图右侧格式,即可使用火焰图工具生成火焰图。

火焰图具有以下特性:
- 每个长方块代表了函数调用栈中的一个函数
- Y 轴显示堆栈的深度(堆栈中的帧数)。调用栈越深,火焰就越高。顶层方块表示 CPU 上正在运行的函数,下面的函数即为它的祖先。
- X 轴的宽度代表被采集的样本数量,越宽表示采集到的越多,即执行的时间长。需要注意的是,X轴从左到右不代表时间,而是所有的调用栈合并后,按字母顺序排列的。
拿到火焰图,寻找最宽的塔并首先了解它们。顶层的哪个函数占据的宽度最大,说明它可能存在性能问题。
如何使用系统工具分析Java的CPU Profiling:

虽然有很多Java专用的profiler工具,但这些工具一般只能看到Java方法的执行,缺少了GC,JVM的CPU时间消耗,并且有些工具的Method tracing性能损耗比较大。
perf和BCC profile的优点是它很高效,在内核上下文中对堆栈进行计数,并能完整显示用户态和内核态的CPU使用,能看到native libraries(例如libc),JVM(libjvm),Java方法和内核中花费的时间。
profiling图:
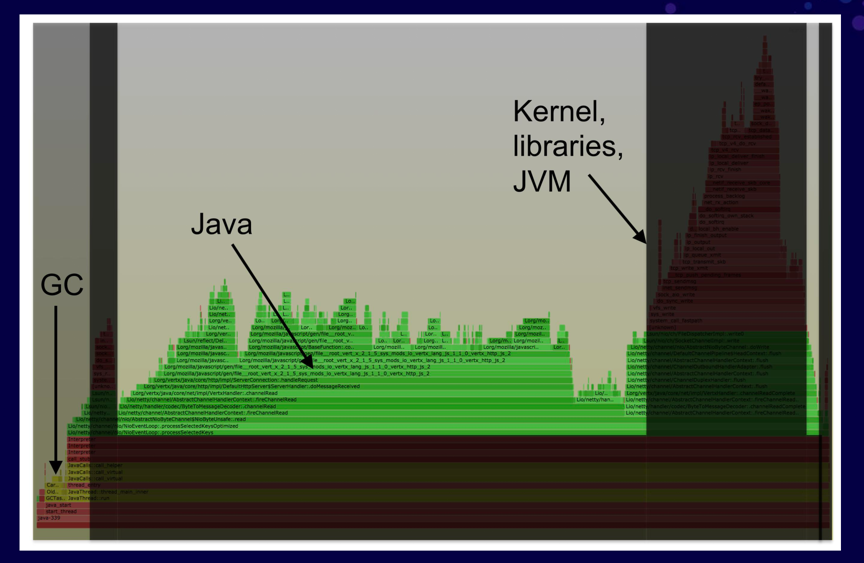
如果使用传统的java profiling工具,可能只看到中间部分,即Java的调用栈的情况,而对于GC、JVM以及内核的运行情况无法抓取。
如果使用系统工具即可抓取进程全貌,而进行更全面的分析。
但是,perf和BCC profile不能很好地与Java配合使用:

它们识别不了Java方法和stack traces
具体原因:
- JVM的JIT(just-in-time)没有给系统级profiler公开符号表。
- VM还使用帧指针寄存器(frame pointer register)作为通用寄存器,打破了传统的堆栈遍历。
目前有两种解决方案:

1. 使用perf-map-agent:
使用JVMTI agent perf-map-agent,生成Java符号表,供perf和bcc读取(/tmp/perf-PID.map)。同时要加上-XX:+PreserveFramePointer JVM 参数,让perf可以遍历基于帧指针(frame pointer)的堆栈。
2. 使用async-profiler:
使用async-profiler,该项目将perf的堆栈追踪和JDK提供的AsyncGetCallTrace结合了起来,同样能够获得mixed-mode火焰图。同时,此方法不需要启用帧指针,所以不用加上-XX:+PreserveFramePointer参数。
以上两种方式均可画出完整的Java火焰图。
下面我们就分别演示这两种方式。

perf-map-agent+perf :
用perf-map-agent为perf生成符号表,同时perf-map-agent也提供了perf-java-flames脚本,可以一步生成火焰图。
perf-java-flames接收perf record命令参数,它会调用perf进行采样,然后使用FlameGraph生成火焰图,一步完成,非常方便。

perf-map-agent+ bcc profile :
同样使用perf-map-agent生成符号表,然后调用bcc profile进行采样,生成火焰图。因为bcc提供了off-cpu的分析,也可以生成off-cpu的火焰图。

async-profiler:
async-profiler将perf的堆栈追踪和JDK提供的AsyncGetCallTrace结合了起来,做到同时采样Java栈与Native栈,因此也就可以同时分析Java代码和Native代码中存在的性能热点。
async-profile提供命令行工具,只需指定持续的时间以及进程ID,即可一步生成火焰图。
async-profiler绘制的火焰图:
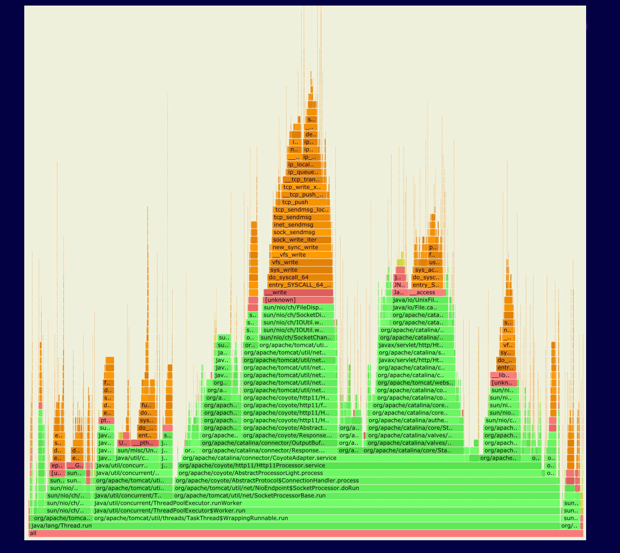
如图所示,绿色代表Java的调用栈,同时可以看到内核调用栈以及本地库的调用栈,同时显示在一张图上,可以更全面的分析Java程序的CPU使用情况。
Java CPU Profiling——总结

为Java进程生成CPU火焰图基本流程的三步:
- 使用工具采集样本;
- 不论perf或BCC,完成样本采集后使用火焰图项目中提供的脚本,将样本进行归纳合并,统计出Stack trace的出现频率,将Stack trace进行汇总;
- 汇总完成后使用脚本根据上一步的结果绘制出火焰图。
以下两种方式可绘制出Java Stacks和native stacks的完整火焰图

- 如果只对javaprofiler进行on-CPU分析,async-profiler更为方便,可一步生成火焰图;
- 如果需要全面了解Java进程运行情况,不仅要分析on-CPU,且同时分析系统锁的开销、I/O的开销以及scheduler的工作,此时还需使用perf和BCC工具做分析。
三、基于鲲鹏的深度优化
CPU与内存:
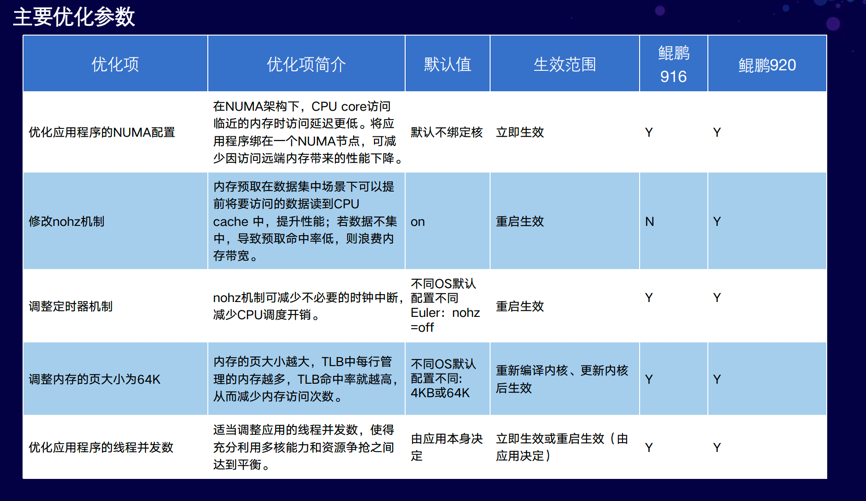

- NUMA的优化,即尽量减少跨NUMA的内存访问;
- 修改CPU的预取开;
- 定时器机制调整, 减少不必要的时钟中断;
- 调整内存页的大小为64K,translation目前是4k的,调整到64K以后,可以提高TLB的命中率;
- 调整线程并发数
以上是对CPU还有内存的调优。
磁盘:
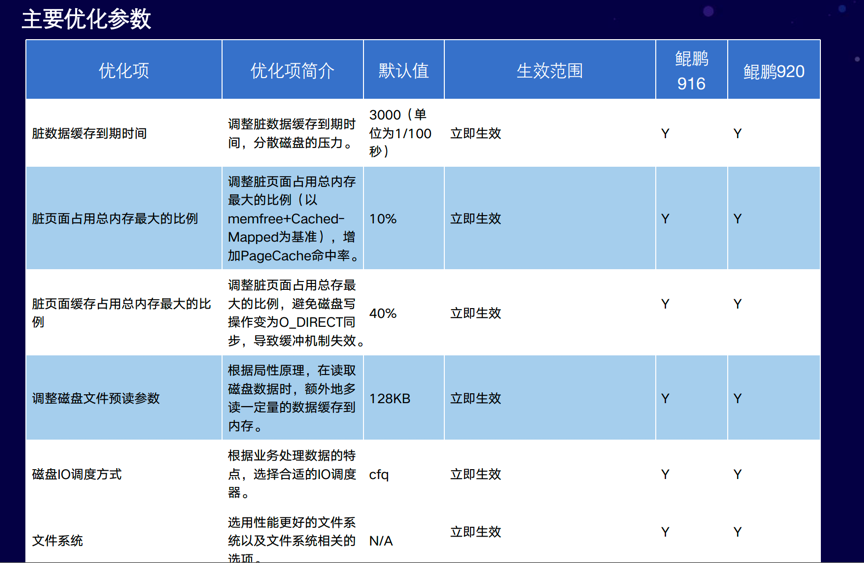

- 调整脏数据刷新策略,减小磁盘的IO压力;
- 调整磁盘文件预读参数;
- 优化磁盘IO调度方式,I/O调度需要根据具体的应用情况选择合适的磁盘I/O调度算法;
- 文件系统参数优化;
- 使用异步文件操作libaio提升系统性能
以上是对磁盘部分的调优。
网络:
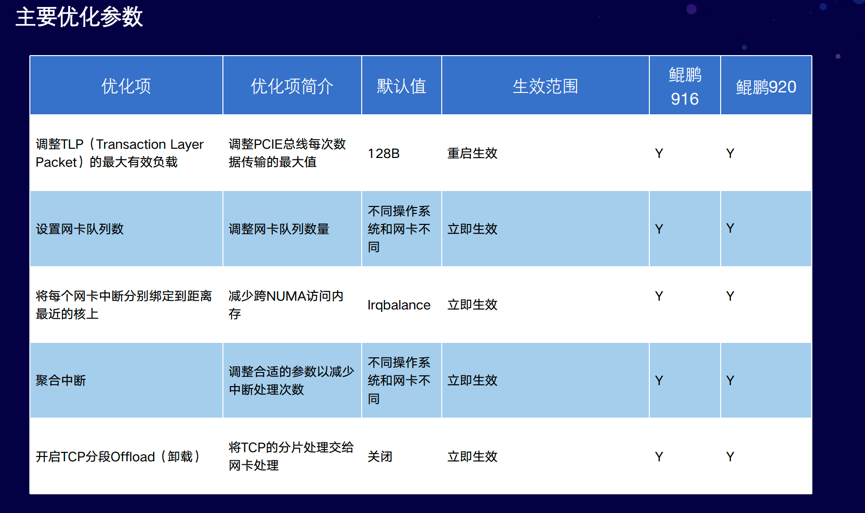

- PCIE Max Payload Size大小配置;
- 网络NUMA绑核,减少跨CPU库的访问;
- 中断聚合参数调整;
- 开启TSO,把TCP分段的卸载处理交给网卡,减少CPU的运算;
- 使用epoll代替select
以上是对网络部分的优化方法。
我们做性能测试时候具体用到的几种优化:

- 配置虚拟机独占NUMA,即尽量减少跨CPU库的访问;
- 配置了增强型的大页内存;
- 关闭透明大页;
- 配置高精度的虚拟机;
- 最后一个是JDK对GC叶子节点的优化,这个是鲲鹏JDK特有的优化。
操作系统的TCP协议站配置:

主要是调整了发送和接收的缓冲器的大小,调整backlog队列,避免队列不够的情况发生。
文件进程及网卡调整:

调整文件进程,开启网卡多队列。
四、技术优化方向与展望

后面我们将对数据库连接池、EJB容器、线程池、日志模块做进一步的优化。
数据库连接池优化:

主要是增强连接池的监控,简化连接池的配置。
EJB容器优化:

改进底层的IO模型,提高EJB远程调用的性能。
应用服务器http线程池优化:

HTTP线程池,与连接池类似,增加更详尽的监控特性,让配置更简化。
日志模块优化:

日志模块同时进行一些优化,以此提高性能。
提问&解答:
Q:统计动作可以在内核完成吗?
A:如果BPF的话,统计是可以的,因为我们可以理解为BPF run time就是运行在内核态的一个虚拟机,小程序编译成BPF字节码加载到了内核,然后可以运行统计以及计算。
Q:traceing的优势是什么?
A: traceing优势比较全面,因为它会抓取所有数据。采样只会采集部分数据,例如一秒钟进行99次采样,此时可能会出现采样数据不全的问题,但采样对程序的影响非常小,损失只在2、3%左右的样子。如果对java进行traceing的话,影响非常大,可能不能真实地反映出这个程序的运行状况,这就两者之间的对比。
Q:我们用perf和BPF解决过哪些实际的问题?
A:我们在产品在发布之前都会做一些性能的测试,此时用perf或者BPF去抓取火焰图,相当于对运行的进程拍了一个X光,内部状况一目了然。可以对热点代码进行分析。例如有些地方中还在使用传统的同步的数据结构,那我们可以换成并发数据结构,比如ConcurrentHashMap。还有一些对锁的使用问题,由于使用方法不对,会抛出很多异常,这时在火焰图里也能明显地看到很宽的山峰,再去仔细分析代码的时候就可以发现且容易定位到系统问题。
更多Web应用的优化内容:https://www.huaweicloud.com/kunpeng/