












1.背景
缓存的使用一定是今后开发中100%会用到的技术,尤其是Redis相关的问题,如果面试官不问我我几个缓存相关的问题,那我觉得我可能是去了个假的互联网公司。
这里考虑到有些初学者刚刚出校园或者自学中,准许我多费口舌介绍下关于缓存的基础知识,我们买电脑的时候关心三个比较重要的参数:1.CPU or GPU 型号。2.内存大小。3.硬盘大小。这三个硬件直接决定你电脑性能的好坏。
两个最关键的因素就是 CPU 和 内存,如何衡量一个CPU的好坏?
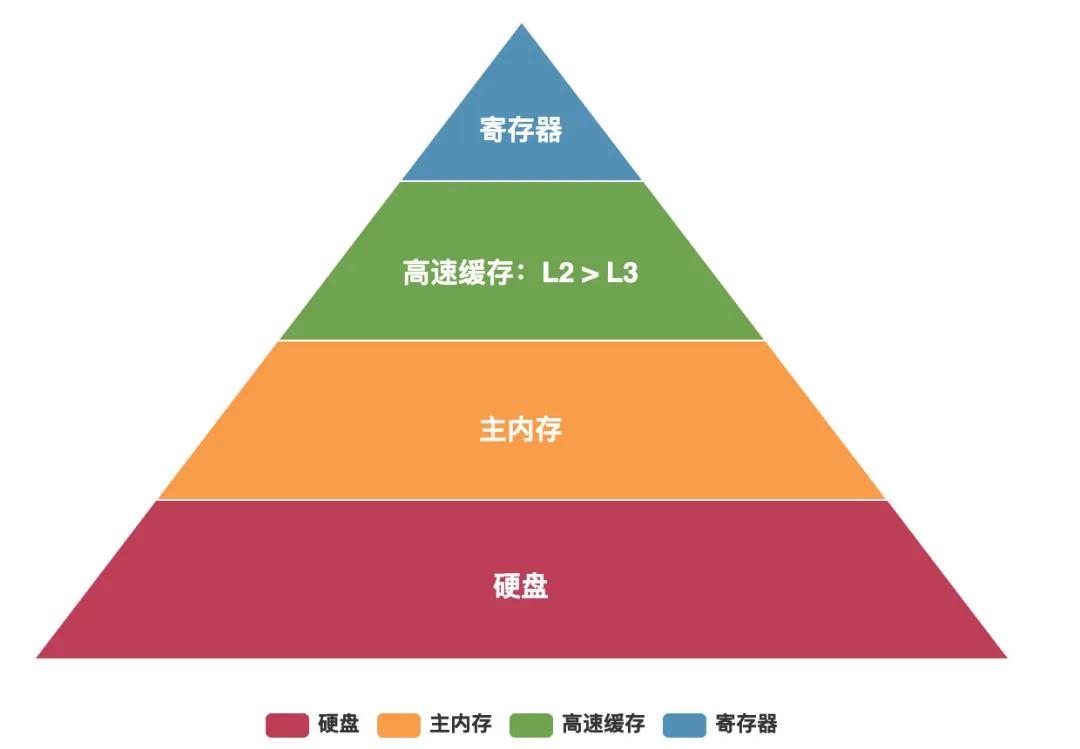
这是我日常开发用的电脑,我们发现有三个关于内存的参数:
- L2 缓存:每个核心 256 KB
- L3 缓存:6 M
- 内存:16 G
缓存和内存的大小是决定你电脑性能的重要参数,我们都知道内存价格远高于磁盘,高速缓存(L2/L3)价格高于内存。
速度:寄存器 > 高速缓存(SRCM) > 内存(DRAM) > 磁盘(SSD > HDD)
画图工具:VisualParadigm
缓存概念
“Cache一词来源于1967年的一篇电子工程期刊论文。其作者将法语词“cache”赋予“safekeeping storage”的涵义,用于计算机工程领域。当CPU处理数据时,它会先到Cache中去寻找,如果数据因之前的操作已经读取而被暂存其中,就不需要再从随机存取存储器(Random Access Memory)中读取数据——由于CPU的运行速度一般比主内存的读取速度快,主存储器周期(访问主存储器所需要的时间)为数个时钟周期。因此若要访问主内存的话,就必须等待数个CPU周期从而造成浪费。提供“缓存”的目的是为了让数据访问的速度适应CPU的处理速度,其基于的原理是内存中“程序执行与数据访问的局域性行为”,即一定程序执行时间和空间内,被访问的代码集中于一部分。为了充分发挥缓存的作用,不仅依靠“暂存刚刚访问过的数据”,还要使用硬件实现的指令预测与数据预取技术——尽可能把将要使用的数据预先从内存中取到缓存里。CPU的缓存曾经是用在超级计算机上的一种高级技术,不过现今计算机上使用的的AMD或Intel微处理器都在芯片内部集成了大小不等的数据缓存和指令缓存,通称为L1缓存(L1 Cache即Level 1 On-die Cache,第一级片上高速缓冲存储器);而比L1更大容量的L2缓存曾经被放在CPU外部(主板或者CPU接口卡上),但是现在已经成为CPU内部的标准组件;更昂贵的CPU会配备比L2缓存还要大的L3缓存(level 3 On-die Cache第三级高速缓冲存储器)。
面试官:你过去的项目中使用了缓存技术吗?哪些业务场景使用了?
分析:不管是C端还是B端业务场景,都会使用缓存,如果系统设计不会使用缓存,那实在是无法说服面试官发offer出来,使用缓存优势就是快,缺点是速度越快价格越昂贵,传统的基于硬盘存储的Mysql已经无法满足现有互联网公司的流量,为了提高系统的性能,应对大流量高并发,cache 在企业里也有也会广泛应用。
我:
项目中我主要在4个地方使用到缓存
- CDN:
- 代理
- 本地缓存
- 分布式缓存
CDN 广泛应用于网站与应用加速、游戏加速、音视频点播、文件等场景,通过高性能缓存机制,静态加速,静态资源如各类型图片、css、js小文件等,提高访问效率和资源可用性。
代理在前面的小节讲到 《Nginx下的负载均衡》 ,Nginx 可作为 http 缓存工具。
后面的章节主要围绕“本地缓存”和“分布式缓存”重点介绍应用层缓存的使用,因为作为开发工程师,应用层你接触相对比较多。
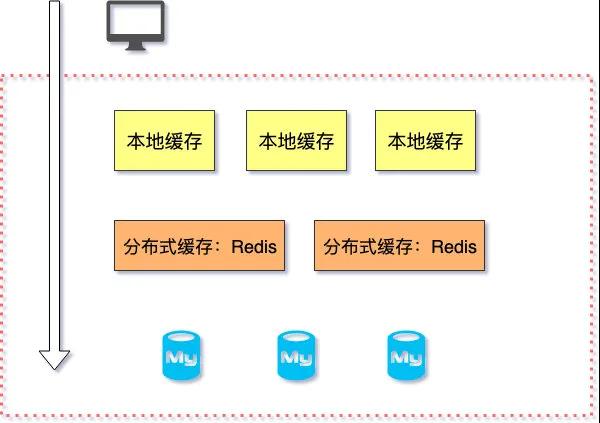
缓存分布图
缓存使用场景
使用缓存,通常考虑两种情况:
- 短时间内相同数据重复查询多次且数据更新不频繁,这个时候可以选择先从缓存查询,查询不到再从数据库加载并回设到缓存的方式。此种场景较适合用单机缓存。
- 高并发查询热点数据,后端数据库不堪重负,可以用缓存来扛。
具体应用场景:
- 排行榜相关的问题,如新浪微博热门话题榜,百度当前热搜榜,一定是在缓存了。
- 热门商品列表
- 计数问题的功能,比如记录网站访问次数或用户访问ip个数。
4.常用缓存框架
在应用服务器本地缓存着热点数据,应用程序可以在本机内存中直接访问数据,而无需访问数据库。在Java里,本地缓存就是缓存在JVM所在主机的内存中,常规设计中,本地缓存处于分布式缓存上一层,客户端请求优先查询本地缓存,如果本地缓存未命中,再去查找 Redis,如果 Redis 依旧没命中,最后查找数据库。也可以直接设计分布式缓存+数据库两层架构。
本地缓存流行框架
- Guavn Cache :Google开源的Java重用工具集库Guava里的一款缓存工具。
- Ehcache:非常流行的纯Java开源缓存框架,使用简单,高速,实现线程安全的缓存管理类库。
- 编程语言自带数据结构:如 Java 的 HashMap,CurrentHashMap 等。
- Spring 缓存:Spring 全家桶无所不能,如果你的项目组人少事儿多,Spring Cache 或许是不错的选择。
分布式缓存流行框架
- Reids:一个远程非关系型内存数据库
- Memcached:应用较广的开源分布式缓存产品之一
- 阿里Tair:阿里开源产品
Redis 是当前最流行的分布式缓存框架,企业广泛使用,也是面试中要求较高的,每个程序员都必须了解掌握,后面会针对 Redis 详细介绍。
为什么要使用缓存
在高并发请求时,为何我们频繁提到缓存技术?最直接的原因是,磁盘IO及网络开销是直接请求内存IO千百上千倍,做个简单计算,如果我们需要某个数据,该数据从数据库磁盘读出来需要0.0045S,经过网络请求传输需要0.0005S,那么每个请求完成最少需要0.005S,该数据服务器每秒最多只能响应200个请求,而如果该数据存于本机内存里,读出来只需要100us,那么每秒能够响应10000个请求。通过将数据存储到离CPU更近的位置,减少数据传输时间,提高处理效率,这就是缓存的意义。
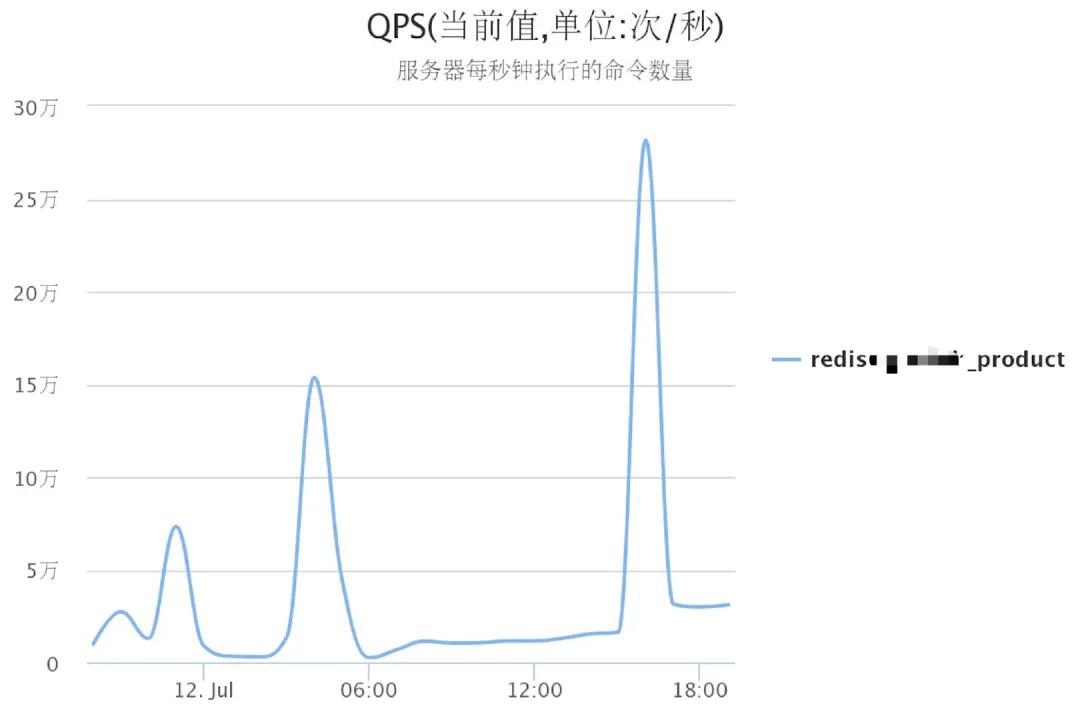
下图是小编工作中负责过的一个风控系统在日常24H中 Redis集群 QPS 曲线图,从业务低峰期几千或晚高峰最高30W,一个 Redis 集群都可轻松应对,30W QPS 在大型系统中流量并不算高,且不是核心系统,如果在多几倍几十倍多流量,一个结构优良的 Redis 集群都可轻松应对,这充分说明了我们为什么要使用缓存,缓存可以把系统系统响应能力提高N个数量级,远高于传统基于硬盘的关系型数据库。所以学会在系统中设计使用缓存也是企业招聘时要求工程师必会的技能。
5.关于缓存的一些算法
常用缓存数据淘汰策略
缓存是非常宝贵的资源,不能把所有数据都放入缓存,只能把最重要的或者要求查询速度最快的数据缓存起来,比如微博热门话题排行榜功能,通常使用缓存查询,而不是数据库。
- FIFO(First In First Out): 先进先出算法,即先放入缓存的先被移除。
- LRU(Least Recently Used): 最近最少使用算法,使用时间距离现在最久的那个被移除。
- LFU(Least Frequently Used): 最不常用算法,一定时间段内使用次数(频率)最少的那个被移除。
缓存数据更新策略
- 定时任务从数据库直接更新缓存:适用于对时间不敏感的数据。
- 查询时写缓存,即查询优先查询缓存,若缓存未命中,查询数据库,将返回结果写入缓存,数据更新时先 delete 缓存,再更新缓存。
- MQ 消息异步更新缓存,后文中会针对MQ的应用做单独讲解。
6.总结
思考:关于缓存淘汰策略和更新策略,各自有什么优点?有什么缺点?读者可以作为延伸学习。
为什么要了解每种策略的优缺点,工作中业务场景千差万别,只有知道不同策略的优缺点才能知道哪种策略最适合当前的业务场景。
高并发网站后台一定离不开缓存的使用,所以面试中要求工程师必须掌握。
关于缓存常见面试题举例:
- 为什么使用缓存,有什么优点?
- Redis 与 Memcached 区别。
- 缓存更新策略 & 淘汰策略。
- 关于 Redis 的知识点,如 Redis 常用数据结构,持久化策略,线程模型等。
参考资料
- 维基百科:https://zh.wikipedia.org/wiki/缓存
- 美团点评技术博客:https://tech.meituan.com/
本文转载自微信公众号「转行程序员」,可以通过以下二维码关注。转载本文请联系转行程序员公众号。















