













大数据文摘出品
作者:Daniel Whitenack
编译:lin、曹培信
这个世界上有多少种语言?
7117种。没错,不是方言,而是正在被使用的语言。
人类传递信息的载体是语言,不同语言之间的交流靠的是翻译,比如世卫组织在疫情防控中,在官网上发布了一个公告,号召大家勤洗手以预防感染。

作为一个国际组织,这里使用的默认语言是英语,但是在网站的右上角也有一个切换语言的地方,提供包括中文在内的6种语言可以选择。

尽管这6种语言覆盖了世界超过35亿的人口,但是显然是远远不够的。
求助于翻译软件?以目前世界上适用范围最广的谷歌翻译来说,现在只能支持100多种语言,也是现存语言的零头。
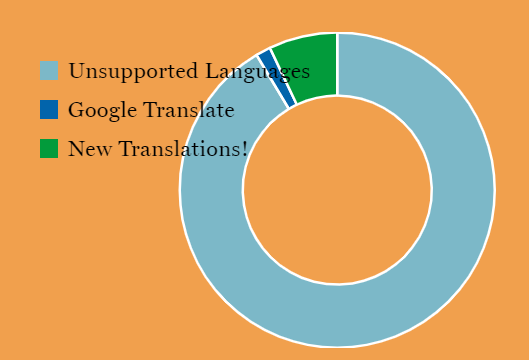
像WHO发布的这种关于全球疫情的消息,肯定是希望能够覆盖到更多的人,但是目前很多地区面临语言障碍而导致信息的传播受阻,哪怕只是想告诉人们要勤洗手。
为了让更多的人能够了解洗手的重要性,一位名叫Daniel Whitenack的AI大佬用使用了多语言无监督方法来训练500多种语言的跨语言词向量,然后从现有目标语言文档中提取“洗”、“手”的部分,然后将这些部分组合起来,生成了510种语言中“洗手”的短语翻译。
Daniel用的是Facebook开发的MUSE(Multilingual Unsupervised and Supervised Embeddings)库,训练了544种语言和英语之间的跨语言词向量,而这些向量允许从现有文档中提取与目标短语“洗手”相似的短语。
Daniel与语言社区SIL International的同事合作完成了这项工作,他们的成果可以在Ethnologue指南页面上看到——一份有着454种译文的新冠病毒指南。
链接:https://www.ethnologue.com/guides/health
下面就跟着数据菌一起来看看他是怎么做的吧!
拆解“洗脚”和“你的手”,变成“洗手”
首先,SIL International已经完成了2000多种语言的语义工作,目前管理着1600多种语言项目文档。所以我想他们可能已经将“洗手”或类似的短语多次翻译成数百种语言,这个猜想得到了证实!
因此我能够从我们的900多种语言档案库中快速收集文档,主要是完整的教学材料和圣经等。这些文档中的每一个都有英文对照,其中必然包含短语“洗手”或类似的短语,例如“洗脸”。此外,这些文档的质量都很高,并与当地语言社区合作进行了翻译和核查。
语言数据集有了!
但是,这里有两个问题需要克服。首先,此数据只有大多数语言的数千个样本,这与用于训练机器翻译模型的数百万个样本相比还是太少;其次,即使文档中包含目标语言中的“洗手”一词,我们也不知道该词在周围文本中的确切位置。
对于低资源语言数据集,我们当然可以利用机器翻译中的一些最新技术,但是需要花费一些时间来调整自动化的方法,以快速适应每种语言配对中的翻译模型。此外,我们定位的许多语言都没有现有的基准,可以与之比较评估指标,例如BLEU得分。
于是我选择尝试通过在现有文档中找到短语本身或短语的组成部分(例如“洗手”或“你的手”)来构建“洗手”一词。
为了找到这些,我使用Facebook Research的Multilingual Unsupervised and Supervised Embedding(MUSE)库训练了每个跨语言词向量。MUSE将单语言词向量作为输入(我使用fasttext生成了这些向量),并使用对抗性方法学习了从英语到目标向量空间的映射,该过程的输出是跨语言词向量。

一旦生成跨语言词向量后,我们便可以在目标语言文档中找到短语。事实证明,整个文档中非常清楚地使用了“洗脸”一词以及“手”,“洗你的”等分离的实例。
对于每种语言,我都会在期望该短语出现的区域中搜索N-gram(基于英语并行匹配中的用法)。使用跨语言词向量对N-gram进行矢量化处理,并使用各种距离度量将其与英语短语的矢量化版本进行比较,向量空间中最接近英语短语的N-gram被确定为目标语言匹配。
最后,将与他们的英语对应词相匹配的组成短语组合在一起,以生成目标语言中的“洗手”短语。这种组合再次利用了跨语言向量,以确保以适当的方式组合。
例如,如果我们在目标语言中匹配了短语“洗脚”,则必须将与“脚”相对应的N-gram替换成与“手”相对应的N-gram,下面是伯利兹·克里奥尔(Belize Kriol)英语的示例:
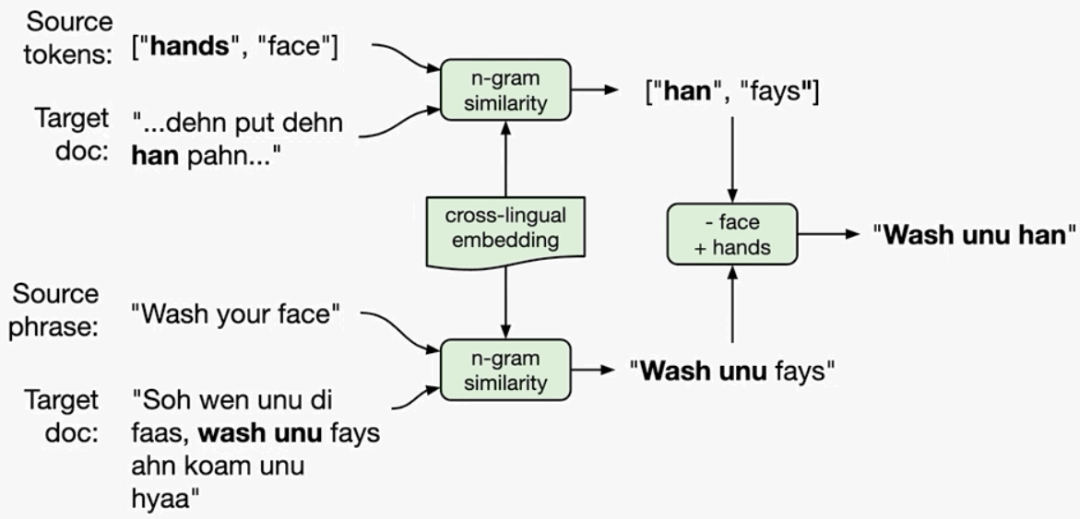
当然,在此匹配过程中我们做了些假设,所以这个过程很可能不会产生语法上正确的预测。例如,我假设在大多数语言中,“手””一词和“脚”一词都是一个词长(词之间用空格和标点符号隔开)。这个假设肯定跟实际是有出入的,以后我们可以克服其中的一些局限性并扩展该系统,但是就目前而言,该方法可以在没有任何翻译系统支持的情况下提供相对可靠的多语言翻译结果。
探索一条低数据条件下的短语翻译方法
到目前为止,我已经能够训练544种语言的跨语言词向量,我使用上面的方法尝试为找出这些语言 如何表示“洗手”。
因为缺乏许多语言对的一致数据,所以我使用了单独的保留文档,其中也包含“洗手”的成分,以帮助验证所构造短语中的标记。
以下是来自Ethnologue语言统计数据的翻译样本:

构造的短语类似于参考译文,或者是“洗手”的替代表达方式。例如,在保加利亚语中,我预测为“умийръцете”,而在Google翻译中,预测为“Измийсиръцете”。但是,如果我使用Google翻译对我的预测进行回译,我仍然会得到“洗手”。
在某些不确定性因素下,我无法与参考译文(例如,所罗门群岛的Pijin [pis]或带有人工注释范畴进行比较,但我仍然可以验证“洗手”(wasim)和“手”(han) )分别用于其他必然谈及洗或手的参考文件中。使用此方法可以验证大约15%的翻译,我希望在收集参考词典时能进行更多的验证。
请注意,即使对于像意大利语这样的高资源语言,我最多都使用每种语言的大约7000个句子来获得以上翻译,也不依赖于语言对之间对齐的句子。尽管存在数据非常匮乏,无监督情景,但对于两个系统都支持的语言,我仍然能够获得质量与Google Translate相似的短语。
从某种程度上来说,这证明了我使用的这种“混合”方法(词向量的无监督对齐+基于规则的匹配)在将短语翻译成数据化很少的语言中,是行之有效的。
相关报道:https://datadan.io/blog/wash-your-hands
【本文是51CTO专栏机构大数据文摘的原创译文,微信公众号“大数据文摘( id: BigDataDigest)”】



















