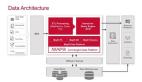
大数据平台上的数据仓库是许多组织正在探索的标准用例。采用这种方法的原因可能是大数据平台提供的许多灵活性之一。

- 适用于企业范围分析的大数据-许多组织正在转变为拥有数据中心或数据湖的概念,在该数据中心或数据湖中,数据是根据源系统而不是基于项目或基于主题领域的数据仓库来收集和存储的。该方法的优点是可以根据需要随时进行市场改造和设计。
- 成本-Hadoop已成为便宜的替代存储介质。
- 更快的分析-大数据平台或Hadoop通用的大数据别名可以处理传统的批处理系统以及近乎实时的决策支持(从数据交付到采取行动所需的时间为2秒至2分钟)或接近实际时间事件处理(从数据传送到执行此操作所花费的时间,从100毫秒到2秒)
- 传统仓库无法支持的异构数据源
- 高数据量-关系数据库无法处理的海量数据
- 数据探索的灵活性-希望发现/探索以前未充分利用或未使用的数据
该页面显示了一种方法,可以将传统仓库转换为BigData平台上的仓库。由于Hadoop生态系统非常广泛,并且生态系统内可用的技术范围很广,因此很难选择在用例中必须使用哪种工具。但是,另一方面,这提供了灵活性,可以根据用例和其他考虑因素(例如性能,操作和支持等)来尝试工具。
该演示将利用HDFS和Hive等Hadoop堆栈上可用的开源技术。
HDFS-是Hadoop的核心,这是一个分布式文件系统,它使Hadoop可以完成所有的任务。还有许多其他分布式文件系统,例如Amazon S3,但是当我们谈论Hadoop HDFS时,它就是文件系统的代名词。像Cloudera,IBM BigInsights,Hortonworks等大多数Hadoop营销供应商都将HDFS用作其文件系统。
Hive -Hive是一个Apache项目,它将数据库,表和SQL的概念引入了大数据世界。蜂巢正在进行中。Hive使用HDFS来存储数据。Hive不仅为文件系统增加了SQL的灵活性,还用于HDFS的元数据存储。元数据存储库不过是一个数据库,它存储有关HDFS中存储的文件,文件结构,分区,存储区,序列化,读取和写入文件所需的反序列化等信息。这将使Hive能够基于存储在其中的元数据查询文件蜂巢元商店。综上所述,Hive为文件提供了数据抽象和数据发现层。
“ Hive的性能如何”
Hive的性能基于许多因素。它包括关系数据库世界中通常遵循的最佳实践,它们具有优化的性能以及诸如文件存储,压缩技术等Hadoop注意事项。为简化起见,让我们检查在Hive上运行查询时会发生什么。
- 通过UI提交给Hive的查询
- Hive驱动程序-在执行和获取模型上工作
- Hive的编译器读取元存储,并获取读取和写入文件所需的表详细信息,结构,序列化和反序列化等信息。编译器随后创建执行计划。遵循已建立的DBMS Hive的足迹,使用基于成本的执行(也提供基于规则和相关性优化器)。它会根据每次操作的成本生成一个包含多个阶段的计划。
- Hive的执行引擎执行由编译器创建的计划。它计划和管理不同阶段之间的依赖关系。每个阶段不过是Hadoop的map and reduce操作“ MapReduce”。各个阶段的输出被写入临时文件,并由后续阶段使用。最后阶段的输出将写入表的文件位置。
综观以上执行模式,Hive表可以通过多种方式进行设计以优化性能。但是每种方法各有利弊。考虑到需求的优先级,必须做出决定。
数据存储选项
- 文件格式 -Hadoop支持多种文件格式选项。文件可以存储为平面文件,Hadoop支持的序列文件,其他复杂但选项丰富的格式,例如ORC,RC,Parquet等。Hive支持上述所有存储格式。但是,也应该考虑对该数据的其他访问技术。如果Hive是唯一的访问选项,则任何存储都可以使用。这将确保更快的查询执行。但是,如果使用其他工具(如ETL工具)来访问文件,则不能保证该工具支持所有格式。
- 压缩:压缩是优化查询的另一种方法。Hive提供了多种压缩编解码器,例如Gzip,snappy等。GZIP的缺点是无法拆分文件。此处使用的压缩编解码器具有不同的属性,某些压缩工作速度更快,需要较少的CPU,而其他压缩文件在压缩过程中需要更多的CPU。Hadoop上文件的可拆分性是提高性能的重要因素。
- 如何存储或组织数据-在Hadoop中组织数据是一门学科。数据的安排对查询有重大影响。如果查询要定位到数据的一部分,我们需要确保查询仅击中该部分,而不是整个可用数据集。可以根据事务级别对数据进行排序,例如事件发生时的数据类型或时间戳
数据中心文件夹结构
在数据中心中存储数据的通用文件夹模式基于源系统。数据中心也可以基于主题区域而不是源系统来构建。必须在企业级别上做出此决定,因为需要在计划和项目之间进行协同才能在企业规模上实现这一目标。让我们看一下如何基于源系统创建文件和文件夹。例如,我们有一个文件,其中包含电影信息,例如movie_id,movie_name,year_of_release(2016),烂番茄的评级和imDB文件都可以通过这种方式安排。同样,如果我们从这些供应商处获得电影评论,其中包含movie_id,review_id,individual_rating,评论等信息,则可以将其存储为现在,让我们检查一些可能的情况,如何使用此数据。
- 取得评分超过3的电影
- 获取评论最多的电影ID
- 获取2014年之后发行的电影数量
这些方案一次只能访问一个文件,而无需在文件之间联接。现在让我们看看其他情况。
- 获得电影的名称和与电影相关的其他信息,以取得最大的评价
这是一个必须在文件之间合并数据的示例。了解联接和查询将使您更好地了解如何存储数据。但是要使其通用,可以将上述文件夹结构改进为此文件夹模式将帮助访问与2016年有关的所有电影和评论。在这种情况下,可以访问2016年的数据而无需读取其他年份的数据。在上面的示例技术中,我们使用了基于年份的分区数据。这种数据安排不仅对Hive有所帮助,而且对将Hive的元存储用于元数据的其他工具(例如impala,spark等)也有帮助。可以将这种文件夹安排与关系数据库上的分区进行比较,因为Hive知道在哪里查找数据而不是进行完整的数据扫描。Hadoop上的数据中心可避免构建传统数据仓库所需要的额外arcHive系统。在传统的DWH中,ETL曾经使用过的源文件会被备份,并在保留一段时间后脱机。使数据重新联机是一项巨大的工作,大多数情况下,随着时间的推移,这些数据将不再使用。上面讨论的折叠机构避免了需要单独的arcHive机构。由于与关系数据库相比,Hadoop上的空间便宜,因此此选项效果很好。
我们可以在Hadoop上进行关系数据建模吗?
当选择Hadoop作为企业数据仓库的平台时,关系数据建模是一个非常常见的用例。问题的答案是,借助Hive元存储,在技术上可以在Hadoop平台上实现。如果我们退后一步,看看设计的文件夹模式,很明显,可以按照RDBMS上的关系数据建模来设计和安排文件夹。HDFS上的数据访问是“读取模式”。无论数据存储的方式和位置如何,都可以按照我们希望的方式对其进行读取。与传统的RDBMS不同,在传统的RDBMS中,必须对模式进行建模并将数据加载到表中。这需要对数据进行大量分析,并在优化的数据模型上花费精力和时间。使用Hadoop,由于模型更改不需要重新加载数据,因此可以大大减少这种工作。为了解释这一点,客户名称,客户ID,客户电子邮件,客户电话号码,购买的商品,商品数量,商品价格。在关系数据库中,可以将这些数据规范化并分为客户信息,产品信息和销售信息,并与客户ID,销售ID和商品ID链接回去。这种模型减少了冗余,这是RDBMS中的一个主要因素,因为存储成本很高。通过建立正确的索引类型,联接的查询将产生更好的结果。
客户信息
- 顾客ID
- 顾客姓名
- 电子邮件
- 电话
Items_Info
- 物品ID
- 商品描述
- 项目名
- 商品价格
销售事实
- 销售编号
- 顾客ID
- 商品编号
- 项目数量
- 销售日期
Hadoop的优势在于,我们仍然可以拥有相同的逻辑模型,并且可以通过多种方式在物理上实现而不用移动数据。
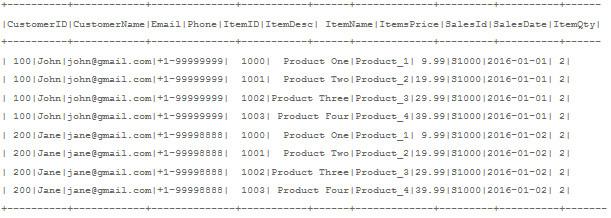
上面的视图显示了数据的非规范化格式,这是在表示层或语义层上需要运行基于事实的分析功能的便捷格式。例如,找到在一种产品上出售的物品总数或在第二种产品上的总收入等等。在规范化建模的数据模型中,这将需要连接至少3个表。在Hadoop中,由于混洗和多个磁盘IO,我们知道联接数据是一项昂贵的操作。在Hadoop平台中,考虑到性能要比存储更重要,因为存储更便宜。
方法1-归一化模型
标准化逻辑模型的物理实现让我们尝试用相同的物理实现来实现标准化形式。用这种方法创建了3个表
根据表上的customerID,Item ID对数据进行存储。桶装是一种基于分发密钥上的哈希来分发数据的技术。选择分发密钥至关重要,因为我们需要确保数据在数据节点之间均匀分布。您可以看到销售数据是根据销售日期划分的,这将有助于查询仅在特定日期或几天范围内访问数据的查询。例如,其中salesDate = '01 / 31/2016'。在加入时将数据存储在同一分发密钥上会有所帮助。在上述模型中,需要连接的大多数查询连接谓词将是ItemId或customerID。由于数据是基于这些字段分配的,因此可以确保在密钥上加入的数据将不需要在网络上进行混洗或移动。这将大大减少加入时间。在Hadoop上,与在reducer端进行连接相比,在map端进行reduce范例连接可以节省时间。Hive自动检测到存储桶,并应用此优化。在以上示例中,存储区大小的256是一个数字,必须根据数据量和可用节点来确定。正常的存储桶大小必须是几个hdfs块大小,并且可以容纳到内存中。不建议使用太多的小桶尺寸的桶。
优点
- 当数据是确定性的并且数据模型可以很好地满足需求时很有用
- 当使用的查询是静态且可预测时有用
- 从关系数据库轻松迁移
缺点
- 不能用于动态查询或其他分析目的
- 更改模型将需要更改ETL,并且需要重新加载数据
- 随着数据的增长和倾斜,性能将成为问题。如果存储桶的密钥不够好,则需要对数据进行恒定的重新分配。
当数据被规范化并以星型模式存储时,我们也必须考虑对事务维护ACID。从技术上讲,我们应该能够插入,更新或删除数据。如您所知,在HDFS中进行数据修改并不容易。但是可以使用其他技术来解决此问题
- 用last_updated_ts附加数据,而不是更新记录
- 将历史数据和最新数据保存在两组文件中。
- 使用Hive使用如何使用Hive进行CRUD更新数据- 在Hive上运行更新和删除
- 在历史数据的顶部创建一个视图,以仅提取最新数据,而不使用上述技术来实现
方法2-归一化数据
第二种方法讨论在添加查询中所需的所有可能属性后对数据进行展平。可以将其与带有列族的平面Hbase表进行比较。在这种方法中,我们只有一张表可以满足我们的所有需求。归一化数据的优点是代码可以读取更大的数据块,而不是从多个小块中读取相同的数据。
数据被分区以进行搜索/选择以进行部分访问。此类分区的逻辑列将是时间戳记或日期。选择分区时,唯一需要考虑的是文件大小。文件的分区信息存储在名称节点中。小文件上的分区过多将在名称节点上繁重。从每个分区读取小文件将不会很好地利用读取器操作以及内存。如果文件很少,HDFS块大小分区将很好地工作。如果文件太小,可以将其合并在一起以具有合理的分区。例如,每日文件只有几千字节。可以根据数据量将许多此类文件放在一个月分区或每周分区中。
优点
- 更快的查询执行
- 适用于开箱即用的分析
缺点
- 数据冗余-您可以看到客户和物料数据在销售信息中重复出现。在Hadoop上,存储不是主要的考虑因素,如果您决定避免冗余,那么就要在空间和性能之间进行权衡。
- 这不是一个必须不断更新数据的好用例。
何时选择对方法1(标准化数据/星型模式)进行De Normalization?
- 如果联接的表很小,并且联接时一对一匹配。
- 当列宽(列数)较小时。如果表很宽,则会占用更多空间,并且块读取大小会变大
- 数据更新不多时。如果您每次必须返回并更新一些随机字段,则反规范化技术将不起作用。例如,对于age,如果age字段是交易的一部分,我们知道每年必须对其进行修改。
在非规范化数据上实现相同的逻辑模型
该组织的大多数人都使用haddop来补充现有的完善的EDW。这些模型与该平台无关,但是正如我们所看到的,与RDBMS相比,Hadoop需要一种不同的物理实现。不管相同的逻辑模型如何,都可以通过多种方式实现。
拆分为尺寸/子表
上面的非规范化销售数据可以分为维度和事实,我们已经讨论过了。
- 在Sales_Fact_Flat表的顶部构建非实现视图,可以使用视图重新创建客户信息 创建视图Customer_Info作为选择不同customerId BIGINT,CustomerName STRING,Email STRING,从Sales_Fact_Flat向STRING打电话同样,可以重新创建其他视图。视图的不利之处在于,每次在查询中使用视图时,地图都会减少在后台运行以实现结果。
- 代替视图,使用CTAS将数据具体化为表(创建表作为选择)创建表Customer_Info作为选择不同 customerId BIGINT,CustomerName STRING,Email STRING,从Sales_Fact_Flat向STRING打电话这些方法的优点是,这些视图/表可以用作其他分析的独立实体。
总而言之,讨论了在Hadoop平台上实现数据仓库的各种可行选择。我们还将讨论基于访问模式,优化和存储技术的各种文件和文件夹创建选项。