参与者说出50句话时会收集他们的神经活动。机器学习算法可以预测所收集数据的含义。该系统的精度各不相同,但结果令人鼓舞。
这只是一个开始,但是却非常令人兴奋:将大脑活动转化为文本的系统。对于那些无法说话的人,例如患有锁定综合征的人,这将改变生活。目前,这有点像看大雾,但是旧金山加利福尼亚大学Chang实验室的研究人员已经训练了一种机器学习算法,可以从神经元数据中提取含义。该研究的合著者约瑟夫·马金(Joseph Makin)告诉《卫报》:“我们还没有到那儿,但是我们认为这可能是言语假肢的基础。”该研究发表在《自然神经科学》杂志上。
为了训练他们的AI,Makin和合著者Edward F. Chang试听了四名参与者的神经活动。作为癫痫病患者,每个参与者都植入了脑电极以监测癫痫发作。
向参与者提供了至少要朗读三遍的50句话。正如他们所做的那样,研究人员收集了神经数据。(还进行了录音。)
该研究列出了参与者列举的少数句子,其中包括:
- “那些音乐家和谐地融为一体。”“她穿着温暖的羊毛羊毛工作服。”“那些小偷偷走了三十颗珠宝。”“厨房里乱七八糟。”
该算法的任务是分析收集的神经数据,并预测何时生成数据。(与参与者音频记录中捕获的非语言声音相关的数据首先被剔除。)
研究人员的算法很快就学会了预测与神经数据块相关的单词。AI预测说出“一只小鸟在看着骚动”时生成的数据将意味着“那只小鸟在看着骚动”非常接近,而“用梯子救猫和那只男人”被预测例如,“将使用哪个梯子来营救猫和人。”
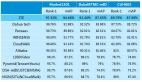
准确性因参与者而异。Makin和Chang发现,基于一个参与者的算法在训练另一个参与者方面具有先机,这表明随着时间的推移和重复使用AI的训练会变得更加容易。
卫报与专家克里斯蒂安·赫尔夫(Christian Herff)进行了交谈,后者发现该系统令人印象深刻,因为它为每个参与者使用不到40分钟的训练数据,而不是其他尝试从神经数据中提取文本所需的大量时间。他说:“通过这样做,它们可以达到迄今为止尚未达到的精确度。”
先前从神经活动中获取语音的尝试主要集中在构建语音的音素上,而Makin和Chang则专注于整体单词。该研究说,尽管肯定有比音素更多的单词,因此这构成了更大的挑战,“连续语音中任何特定音素的产生都受到其前音素的强烈影响,从而降低了其可分辨性。” 为了最大程度地降低基于单词的方法的难度,口头句子总共使用了250个单词。
显然,还有改进的空间。AI还预言“那些音乐家很棒的和谐”是“菠菜是著名的歌手”。“她穿着温暖的羊毛羊毛工作服”被误认为“绿洲是海市rage楼”。“那些小偷偷走了三十颗珠宝”被误解为“哪个剧院放映了鹅妈妈”,而算法预测的数据“厨房里乱了”表示“有帮助他偷了饼干”。
当然,这项研究涉及的词汇是有限的,句子范例也是如此。Makin指出,“如果您尝试使用的[50个句子]之外,解码会变得更加糟糕。” 另一个明显的警告来自这样一个事实,即AI是根据每个参与者大声说出的句子来训练的,这对于被锁定的患者是不可能的。
Makin和Chang的研究仍然令人鼓舞。对于其中一位参与者的预测,只需进行3%的微小修正即可。这实际上比人类转录中发现的5%错误率要好。