Labs 导读
2020年初一场又新型冠状病毒引发的疫情席卷全中国。各大运营商积极响应国家工信部号召,将利用自身大数据优势,以手机信令为主,通过位置轨迹、用户漫游识别、交往圈、返乡用户识别等模型构建一个疫情流向分析辅助决策系统,辅助相关部门疫情决策的大数据分析应用,并实现特定人群通知警示类公益短信发送。帮助国家打赢这场战“疫”。
1、背景
2020年初,一场突如其来的由新型冠状病毒引发的肺炎疫情席卷中国大陆,为有效遏制病毒的传播1月23日武汉封城,但即使这样依旧有大批潜在疫情人口在城市里流动。那些来自疫情重灾区湖北武汉、浙江温州、广东深圳等城市,暂时无任何肺炎症状也没有发热的人,他们作为首批潜在疫情人口,踏上了春运,一场数以千万计人参与的大迁徙。
如何找到那些潜在的疫情人口,如何把瘟疫的传播从源头上控制住,每个省受到传播感染的情况未来到底有多严重?是这场2019新冠病毒给我们带来的课题。
运营商数据,在一个人人使用智能手机的时代,有覆盖广、规模大、数据连续且时效性高的特点。针对此次疫情传播率高,且恰逢寒假和春节,有大量学生回家、务工人员返乡的春运,通过运营商手机信令数据与用户数据及基站数据的计算,建立不同人员模型,感知整个春运期间不同人员,尤其是疫情重点地区人员的流向分布情况。为当地政府相关部门应对疫情发展、蔓延防控决策提供数据上的决策支撑。
2、研究过程
2.1 数据来源
做整体数据分析时,我们采集数据源为:
- d口位置数据:交换机位置切换数据/漫游位置数据,特点是数据范围大,不精确,只能到地市级别和国家级别;优点是可以捕获用户出省以及出国的位置情况。
- mc口:本地网2G位置数据,小区级别数据;
- s1-mme口:本地网4G位置数据、小区级别数据;
- 数据结构流量/语音话单:省内小区级、省外地市级。
采集的数据进行归纳整理后的形成基础数据表:
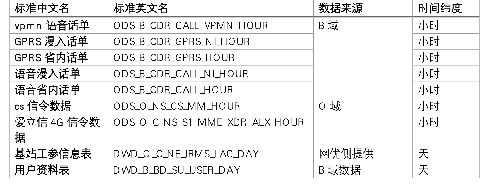
- 位置轨迹表:由 B域的vpmn语音话单,GPRS漫入话单,GPRS省内话单,语音漫入话单,语音省内话单和O域的cs信令数据,爱立信4G信令数据一共7种信令通过MR程序的模型算法得出,时间纬度为小时;
- 基站工参信息表:通过网优部门采集的覆盖全省10个地市,92个区县的30余万个基站工参信息。
- 用户资料表:全省3000余万用户的B域基础数据。
2.2 数据特点
以本次分析的重点贵州省为例,截止到2018年末贵州省的通讯用户有3940.4万户,覆盖全省10个地市直辖区下的92个区县,共计30余万个基站小区平均每天产生的数据量高达19.5TB。只要手机开着,无论是否打电话、刷流量,手机都会全天24小时不间断与基站发生交互,产生各种状态的信令消息。
这些数据从基站小区的交换机采集,传输到机房,在进行数据的合并,清洗,加工,最后模型计算、分析与上层应用数据呈现,整套流程的时间延迟最大不超过24小时。对于应对这种大型灾难性疫情的防控研判起到至关紧要的作用。
但是运营商数据从采集信令的时候,到事件合成和XDR合成过程中,均会出现问题导致信令漏采,号码回填失败等。
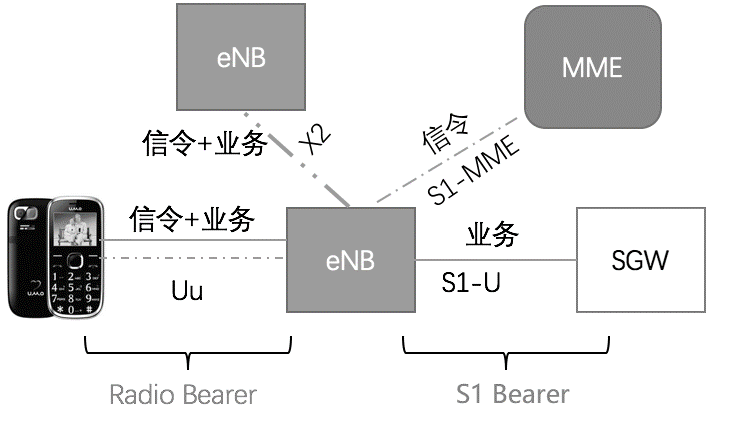
在信令采集时基站(eNB)和核心网之间采用S1接口,S1有两种接口:
- S1-MME 连接eNB和MME,接口专门传送信令;
- S1-U 连接eNB和SGW接口传输业务数据;
多个eNB之间采用X2口连接,X2接口上能同时传输业务&信令,eNB和UE之间采用Uu接口,Uu接口上也是能同时传输业务&信令。
在上述接口对接的过程中数据的传输会存在不稳定、丢包的情况。这样会从源端导致一部分用户数据的丢失。
当源端数据采集过来后将进行事件融合和XDR融合的信令数据处理,处理的过程中还有号码丢失的情况,遇到这种情况不同的数据处理厂商会提供基于他们自身算法的号码回填机制,但回填的号码存在无效号码或空号。这种情况也将导致数据不可用。
2.3 数据模型
对于运营商数据上存在的不全、缺损的问题,有一部分我们没有办法通过算法补全,但是对于大数据决策来说,只要总体数据展现出来的发展趋势符合现实发生的状况,那数据就是可用的,有价值的;而对于另一些数据而言,我们将采用4个核心模型作为研判的基础模型,通过大量数据计算和合理的公式处理以得出最终可用辅助政府部门决策的结论。
1)轨迹模型
由于特定的某一类人的位置信息有很强的关联性和相关性,对用户位置轨迹建模就是基于集体行为模式的方法,来优化用户的位置轨迹,同时,根据集体行为模式也可以用来预测用户未来一段时间的轨迹,根据用户历史的位置轨迹及预测的位置轨迹。
模型主要根据现有的基站数据,提取用户的基站数据初步模拟用户的位置轨迹,同时对所有用户的位置轨迹进行相似度分析,使用轨迹层次聚类算法将所有用户轨迹进行聚类,最后根据聚类结果校对优化用户原先的位置轨迹,提升用户位置轨迹的准确率,同时,可以将最终的位置轨迹映射到地图上,结合地图周边信息进行针对性的疫情分析。
- 根据基站数据模拟用户位置轨迹
- 用户位置轨迹相似度分析
- 轨迹层次聚类算法
- 优化用户位置轨迹
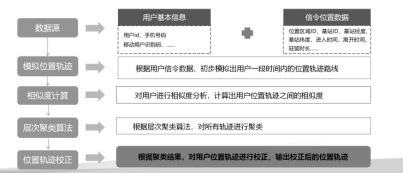
图2:轨迹算法模型
具体的思路和规则:
- 提取用户一天之内的基站信息;
- 将用户的基站经纬度映射到地图上,按时间先后进行连接画线;
- 对用户与其他用户之间的轨迹曲线进行相似度计算;
- 用轨迹聚类算法,寻找出与此用户位置轨迹在同一群体里的用户;
- 根据同一群体内的用户位置轨迹,剔除此用户中异常的基站。
在此基础上,优化用户的位置轨迹,同时,可以根据用户所经过的基站的经纬度计算出基站之间的距离,结合每个基站的驻留时长,计算出用户两两基站之间的速度,判断用户的交通工具,根据交通工具匹配地图上的轨迹路线,进一步优化用户的位置轨迹。
2)漫游模型
通过对运营商用户漫游过程的监测和分析,找到漫游进入用户和漫游离开用户。
针对漫游离开用户,基于用户话单表、用户表等基础表单信息,凡漫游到其他省份的用户在产生流量、通话、短信等通信消费行为后,会产生话单信息。根据话单表中记录的用户所产生消费行为对应的省份、地市信息,确定用户漫游到访的省份地市。
针对漫游进入用户,基于常驻表、工参表、基站信息表等基础表单,根据用户进入省内基站的时间,基站位置信息,确定用户漫入省内的开始时间、结束时间、基站ECI、基站名称等。
3)交往圈模型
- 取目标用户有效交往圈清单;
- 取待识别号码有效交往清单;
- 取目标用户和待识别用户有效交往圈交集;
分别计算和目标用户有效交往圈存在交集的待识别号码的符合率:
- 符合率=交往圈交集大小/目标用户有效交往圈大小
- 分目标号码将符合率有高到低进行排序;
- 取目标号码的网络位置小区和待识别号码的网络位置小区;
- 计算每个目标号码和待识别号码网络位置小区重合数;
- 判断目标号码和待识别号码是否相同;
- 如果符合率大于,将、小区重合数、符合率从高到低综合排序,取排名第一位;
- 如果符合率小于等于,必须相同,然后将小区重合数、符合率从高到低综合排序,取排名第一位;
- 最终识别结果必须满足符合率大于或者小于且相同;
- 指纹匹配相似度=符合率+(0.5×有效交往圈近似性+0.5×全集交往圈近似性)
交往圈近似性是通过目标用户与待识别用户交往圈大小来描述其近似性的。包括全集交往圈近似性和有效交往圈近似性。
全集交往圈描述的是待识别用户与目标用户全集交往圈的近似性程度,公式如下:
- 全集交往圈近似性=1-目标用户与待识别用户的全集交往圈大小之差的绝对值/目标用户与待识别用户的全集交往圈大小之和
有效交往圈近似性:描述的是待识别用户与目标用户的有效交往圈的近似程度,其公式如下:
- 有效交往圈近似性=-目标用户与待识别用户的有效交往圈大小之差的绝对值目标用户与待识别用户的有效交往圈大小之和。
最终得到用户的匹配号码,以此获得用户特征信息。
4)返乡模型
基站驻留轨迹、通话行为、用户基础属性作为模型的基本数据;
通过对目标用户的业务规则和数据剖析,初步筛选出36个用户特征纬度,进一步采用统计学算法的因子、聚类、主成分分析,最终选取相关度较高(r>0.6)、独立性较好(p<0.05)、累计贡献率超过80%以上的前11个综合特征指标;
为消除各个用户特征数量级不同对模型预测效果产生的影响,采用Z-score方法对相应指标进行标准化处理;
结合业务经验评估及对比各维度的重要性,采用专家打分法,计算权重系数,并对模型输入的纬度数据进行加权处理;
数据挖掘的过程中,先采用Logistic回归算法训练模型,确定识别规则,预测返乡用户分值,再采用二八定律制定分数阈值;
逻辑(斯蒂)回归(Logistic Regression),是一种广义的线性回归分析模型,是数据挖掘中比较常用的模型算法,用于估计某种事物的可能性。逻辑回归最终输出一个0-1之间的概率值,通常以0.5为分界点,越接近1表示可能性倾向性越大,反之越近0表示可能性越低。
假设我们有n个独立的样本{(x1, y1) ,(x2, y2),…, (xn, yn)},y={0, 1},那每一个观察到的样本(xi, yi)出现的概率是:
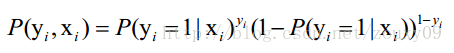
1. 写出似然函数,对整个样本来说明,n个独立样本出现的似然函数为(最大似然法就是求模型中使得似然函数最大的系数取值θ*,对应为代价函数):
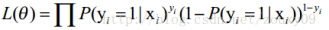
2. 对似然函数取对数,并整理:
3.
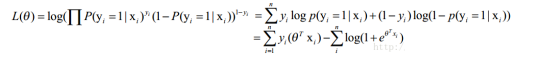
这次建模将通过python的scikit-learn中的LogisticRegression实现逻辑回归算;。
得出返乡目标用户。
5)位置定位算法
采用PNPoly 算法对将用户所在位置进行优化。根据 W. Randolph Franklin 提出的 PNPoly 算法,如果一个点在多边形的内部,那么从这个点引一条射线,那么与多边形的边的交点是奇数个,那么就在多边形的内部,如果是偶数个,那么该点在多边形的外面。考虑到运营商网络的特点,还需要计算基站与住宅小区轮廓线各点的距离,通过设置阈值,来判断拉远站以及周边站。从而计算出住宅小区的网络覆盖,进一步计算潜在疫情人口分布。
2.4计算环境
- HADOOP基本的数据清洗,运用到700个节点;
- SPARK模型数据计算,运用到100个节点;
- MPP用于存放结果数据的数据仓库,运用到71个节点。
2.5数据应用
A.可视化数据大屏
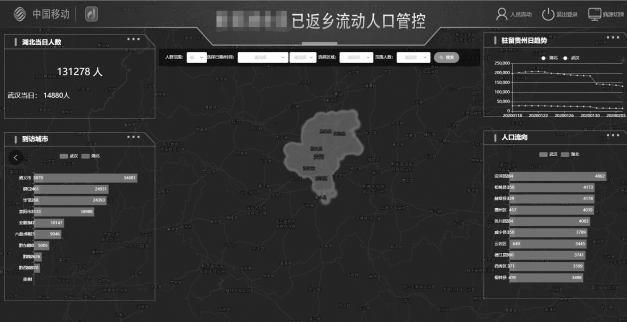
将通过模型计算的数据按照系统规定好的数据格式放入数据库中,系统页面通过折线图可以感知到从疫情重点区域到访的每日人数变化趋势,柱状图可以了解到重点省份的重点地市下的一个人员数量及占比,热力图更好的可以看出不同时段下、不同人数区间、不同地区人员聚集的情况。
从可视化大屏可以直观的感受到潜在疫情人口的分布、流向,对相关政府部门进行疫情防控决策起重要的辅助作用。
B.公益性通知短信

利用运营商平台优势,实现公益类短信发送。通过文字类短信、图片类短信和视频类短信多种形式,可定向给潜在感染人群发送警示类短信,及卫生防疫知识。
掌握确诊人群的信息的前提下,还可以通过数据模型分析,识别出与确诊人群接触过的一般接触者,对一般接触者发送有特点内容的警示告知类短信。短信发送均不出运营商内网,保证每一个用户的隐私和安全。
3、结论
3.1 算法验证
以2020年2月2日贵阳市军阅酒店为例,作为第一批向公众开放的湖北籍旅客指定接待酒店。该酒店位于贵阳市观山湖区西二环84号北大资源梦想城军创大厦内,1月26日起作为湖北籍旅客指定接待酒店开放,截止到1月30日已接待旅客108人。
从贵州疫情流向分析数据中查询到2020年1月30日军阅酒店内室分基站下湖北籍用户人数有71人。按照运营商用户数占比,以及儿童无手机等其他干扰情况数据分析后得出,军阅酒店内湖北籍旅客在100人左右,和实际情况出入不大。可以将军阅酒店纳入重点疫情监控区域。
当截止到2020年2月13日,军阅酒店内已有三例新型冠状病毒肺炎的确诊病例。
3.2未来展望
通过此次新型冠状病毒肺炎疫情的考验,我们发现运营商的大数据发展虽然有了不错的模型建设能力及展示能力,但是在基础数据采集和回填上仍存在漏洞。仅依靠以基站为准的位置定位范围较广,只能进行宏观层面的决策辅助,并不能实现细节方面的精确定位。随着模型算法的不断成熟,基于OTT和MR的精确位置定位,和5G应用的广泛推广,基于运营商的应用一定可以在各行各业中起到关键性的作用。
而通讯运营商作为国有企业,有责任和义务享受着大数据时代带来便捷同时保护每个用户的隐私不被泄露的同时,在国家重大突发事件中积极响应工业和信息化部的号召,按照要求在疫情初期完成省级平台高危人群的定位、位置轨迹的风险、区域内非正常人群聚集的监控,为国家的抗“疫”之战添砖加瓦。
OTT和MR的精确位置定位,和5G应用的广泛推广,基于运营商的应用一定可以在各行各业中起到关键性的作用。
而通讯运营商作为国有企业,有责任和义务享受着大数据时代带来便捷同时保护每个用户的隐私不被泄露的同时,在国家重大突发事件中积极响应工业和信息化部的号召,按照要求在疫情初期完成省级平台高危人群的定位、位置轨迹的风险、区域内非正常人群聚集的监控,为国家的抗“疫”之战添砖加瓦。
【本文为51CTO专栏作者“移动Labs”原创稿件,转载请联系原作者】