机器学习、数据挖掘等各种大数据处理都离不开各种开源分布式系统,hadoop用于分布式存储和map-reduce计算,spark用于分布式机器学习,hive是分布式数据库,hbase是分布式kv系统,看似互不相关的他们却都是基于相同的hdfs存储和yarn资源管理,本文通过全套部署方法来让大家深入系统内部以充分理解分布式系统架构和他们之间的关系,本文较长,精华在最后。
本文结构
首先,我们来分别部署一套hadoop、hbase、hive、spark,在讲解部署方法过程中会特殊说明一些重要配置,以及一些架构图以帮我们理解,目的是为后面讲解系统架构和关系打基础。
之后,我们会通过运行一些程序来分析一下这些系统的功能
最后,我们会总结这些系统之间的关系
分布式hadoop部署
- 首先,在http://hadoop.apache.org/releases.html找到稳定版tar包
- 下载到/data/apache并解压
- 在真正部署之前,我们先了解一下hadoop的架构
hadoop分为几大部分:yarn负责资源和任务管理、hdfs负责分布式存储、map-reduce负责分布式计算
先来了解一下yarn的架构:
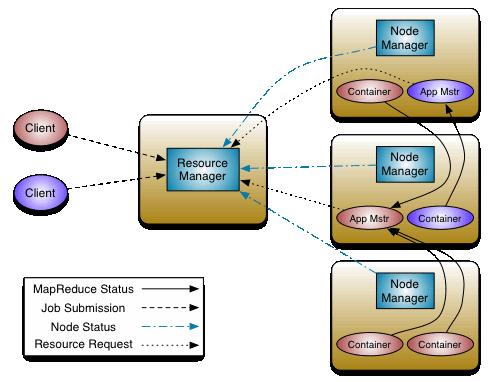
yarn的两个部分:资源管理、任务调度。
资源管理需要一个全局的ResourceManager(RM)和分布在每台机器上的NodeManager协同工作,RM负责资源的仲裁,NodeManager负责每个节点的资源监控、状态汇报和Container的管理
任务调度也需要ResourceManager负责任务的接受和调度,在任务调度中,在Container中启动的ApplicationMaster(AM)负责这个任务的管理,当任务需要资源时,会向RM申请,分配到的Container用来起任务,然后AM和这些Container做通信,AM和具体执行的任务都是在Container中执行的
yarn区别于第一代hadoop的部署(namenode、jobtracker、tasktracker)
然后再看一下hdfs的架构:hdfs部分由NameNode、SecondaryNameNode和DataNode组成。DataNode是真正的在每个存储节点上管理数据的模块,NameNode是对全局数据的名字信息做管理的模块,SecondaryNameNode是它的从节点,以防挂掉。
最后再说map-reduce:Map-reduce依赖于yarn和hdfs,另外还有一个JobHistoryServer用来看任务运行历史
hadoop虽然有多个模块分别部署,但是所需要的程序都在同一个tar包中,所以不同模块用到的配置文件都在一起,让我们来看几个最重要的配置文件:
- 各种默认配置:core-default.xml, hdfs-default.xml, yarn-default.xml, mapred-default.xml
- 各种web页面配置:core-site.xml, hdfs-site.xml, yarn-site.xml, mapred-site.xml
从这些配置文件也可以看出hadoop的几大部分是分开配置的。
除上面这些之外还有一些重要的配置:hadoop-env.sh、mapred-env.sh、yarn-env.sh,他们用来配置程序运行时的java虚拟机参数以及一些二进制、配置、日志等的目录配置
下面我们真正的来修改必须修改的配置文件。
修改etc/hadoop/core-site.xml,把配置改成:
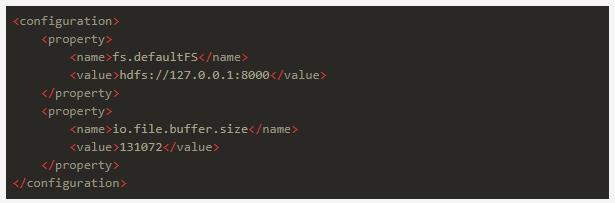
这里面配置的是hdfs的文件系统地址:本机的9001端口
修改etc/hadoop/hdfs-site.xml,把配置改成:
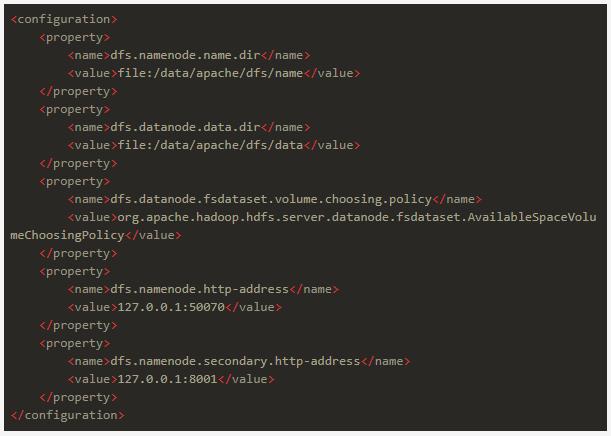
这里面配置的是hdfs文件存储在本地的哪里以及secondary namenode的地址
修改etc/hadoop/yarn-site.xml,把配置改成:
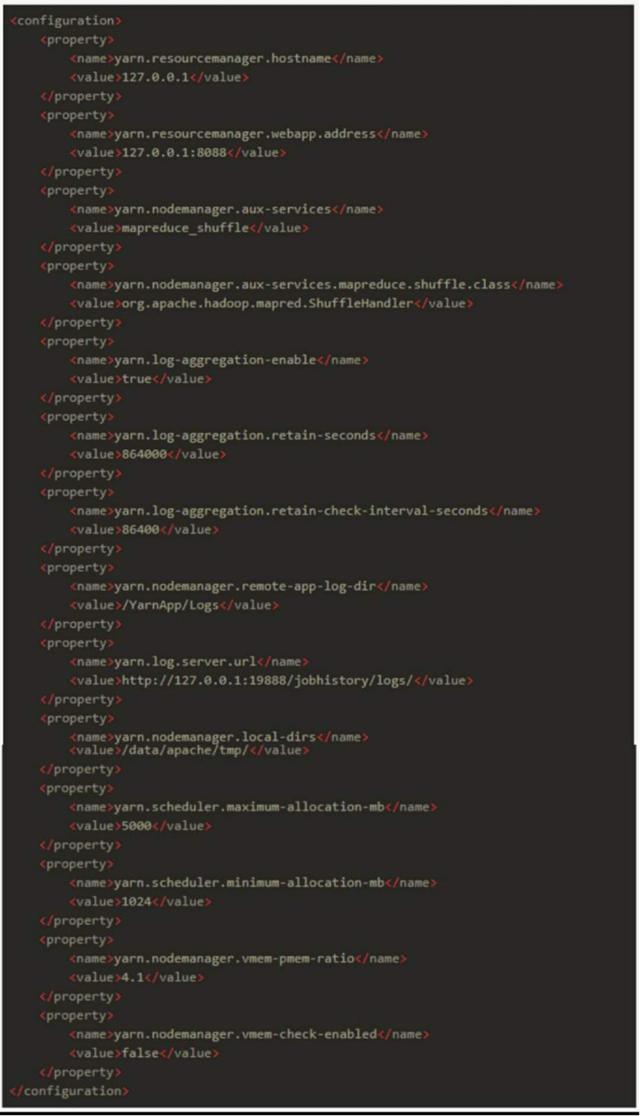
这里面配置的是yarn的日志地址以及一些参数配置
通过cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml创建etc/hadoop/mapred-site.xml,内容改为如下:
这里面配置的是mapred的任务历史相关配置
如果你的hadoop部署在多台机器,那么需要修改etc/hadoop/slaves,把其他slave机器ip加到里面,如果只部署在这一台,那么就留一个localhost即可
下面我们启动hadoop,启动之前我们配置好必要的环境变量:
先启动hdfs,在此之前要格式化分布式文件系统,执行:
如果格式化正常可以看到/data/apache/dfs下生成了name目录
然后启动namenode,执行:
如果正常启动,可以看到启动了相应的进程,并且logs目录下生成了相应的日志
然后启动datanode,执行:
如果考虑启动secondary namenode,可以用同样的方法启动
下面我们启动yarn,先启动resourcemanager,执行:
如果正常启动,可以看到启动了相应的进程,并且logs目录下生成了相应的日志
然后启动nodemanager,执行:
如果正常启动,可以看到启动了相应的进程,并且logs目录下生成了相应的日志
然后启动MapReduce JobHistory Server,执行:
如果正常启动,可以看到启动了相应的进程,并且logs目录下生成了相应的日志
下面我们看下web界面
打开http://127.0.0.1:8088/cluster看下yarn管理的集群资源情况(因为在yarn-site.xml中我们配置了yarn.resourcemanager.webapp.address是127.0.0.1:8088)

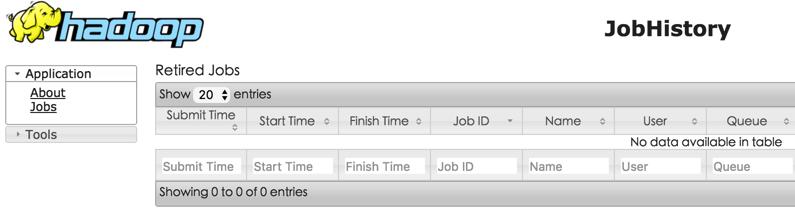
打开http://127.0.0.1:19888/jobhistory看下map-reduce任务的执行历史情况(因为在mapred-site.xml中我们配置了mapreduce.jobhistory.webapp.address是127.0.0.1:19888)
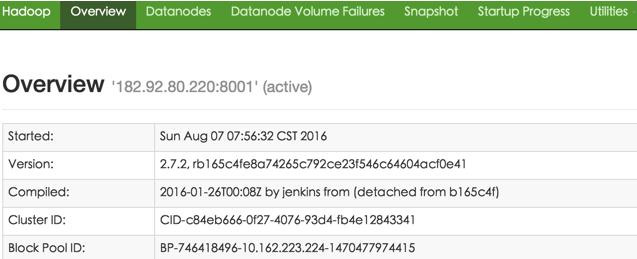
打开http://127.0.0.1:50070/dfshealth.html看下namenode的存储系统情况(因为在hdfs-site.xml中我们配置了dfs.namenode.http-address是127.0.0.1:50070)
到此为止我们对hadoop的部署完成。下面试验一下hadoop的功能
先验证一下hdfs分布式文件系统,执行以下命令看是否有输出:
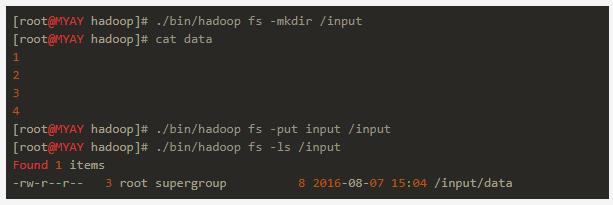
这时通过http://127.0.0.1:50070/dfshealth.html可以看到存储系统的一些变化
下面我们以input为输入启动一个mapreduce任务

之后看是否产生了/output的输出:
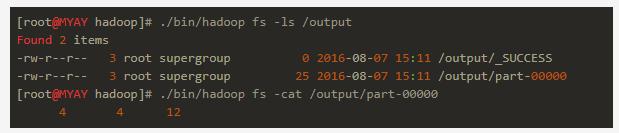
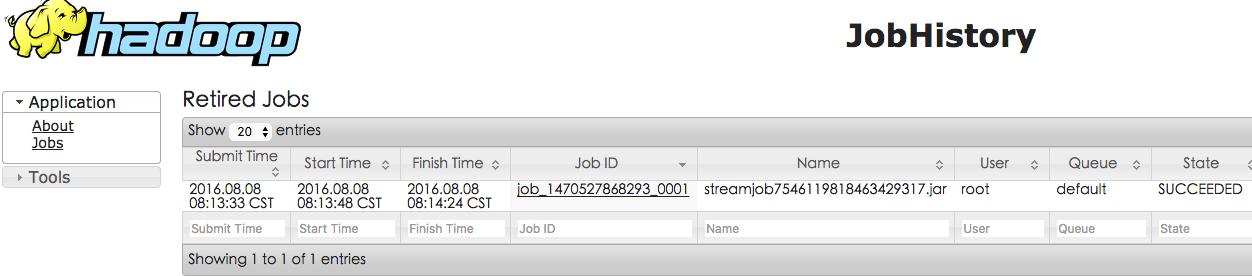
这时通过http://127.0.0.1:19888/jobhistory可以看到mapreduce任务历史:
也可以通过http://127.0.0.1:8088/cluster看到任务历史
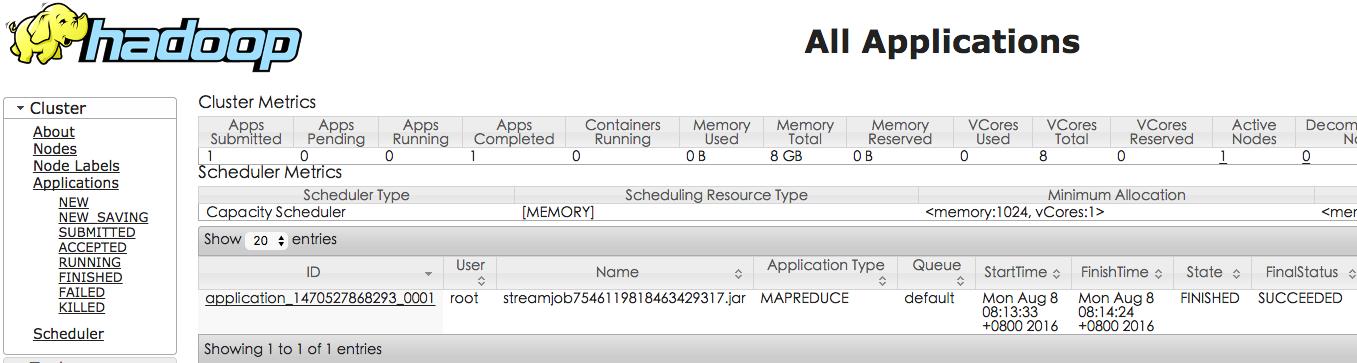
为什么两处都有历史呢?他们的区别是什么呢?
我们看到cluster显示的其实是每一个application的历史信息,他是yarn(ResourceManager)的管理页面,也就是不管是mapreduce还是其他类似mapreduce这样的任务,都会在这里显示,mapreduce任务的Application Type是MAPREDUCE,其他任务的类型就是其他了,但是jobhistory是专门显示mapreduce任务的
hbase的部署
首先从http://www.apache.org/dyn/closer.cgi/hbase/下载稳定版安装包,我下的是https://mirrors.tuna.tsinghua.edu.cn/apache/hbase/stable/hbase-1.2.2-bin.tar.gz
解压后修改conf/hbase-site.xml,改成:
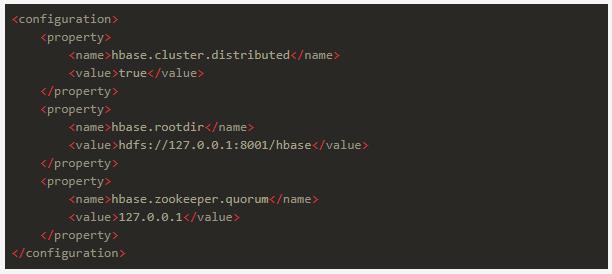
其中hbase.rootdir配置的是hdfs地址,ip:port要和hadoop/core-site.xml中的fs.defaultFS保持一致
其中hbase.zookeeper.quorum是zookeeper的地址,可以配多个,我们试验用就先配一个
启动hbase,执行:

这时有可能会让你输入本地机器的密码
启动成功后可以看到几个进程起来,包括zookeeper的HQuorumPeer和hbase的HMaster、HRegionServer
下面我们试验一下hbase的使用,执行:

创建一张表

获取一张表

添加一行

读取全部

我们同时也看到hdfs中多出了hbase存储的目录:
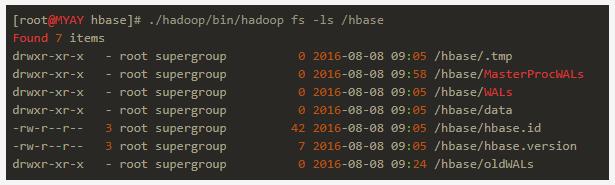
这说明hbase是以hdfs为存储介质的,因此它具有分布式存储拥有的所有优点
hbase的架构如下:
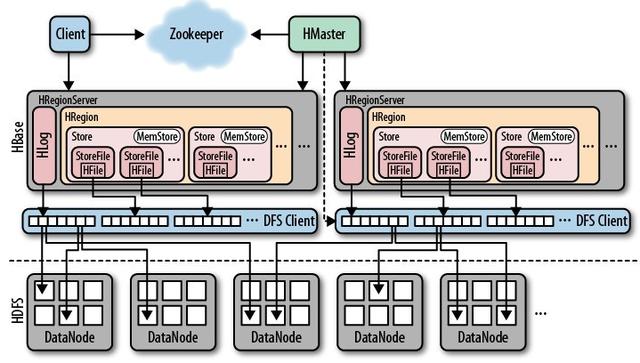
其中HMaster负责管理HRegionServer以实现负载均衡,负责管理和分配HRegion(数据分片),还负责管理命名空间和table元数据,以及权限控制
HRegionServer负责管理本地的HRegion、管理数据以及和hdfs交互。
Zookeeper负责集群的协调(如HMaster主从的failover)以及集群状态信息的存储
客户端传输数据直接和HRegionServer通信
hive的部署
从http://mirrors.hust.edu.cn/apache/hive下载安装包,我下的是http://mirrors.hust.edu.cn/apache/hive/stable-2/apache-hive-2.1.0-bin.tar.gz
解压后,我们先准备hdfs,执行:
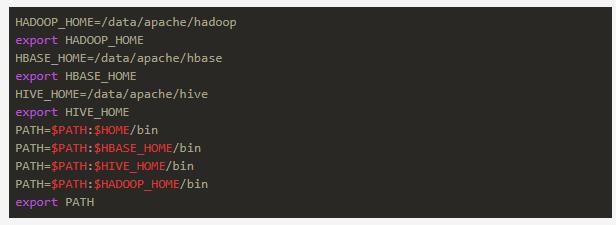
使用hive必须提前设置好HADOOP_HOME环境变量,这样它可以自动找到我们的hdfs作为存储,不妨我们把各种HOME和各种PATH都配置好,如:
拷贝创建hive-site.xml、hive-log4j2.properties、hive-exec-log4j2.properties,执行

修改hive-site.xml,把其中的${system:java.io.tmpdir}都修改成/data/apache/tmp,你也可以自己设置成自己的tmp目录,把${system:user.name}都换成用户名

初始化元数据数据库(默认保存在本地的derby数据库,也可以配置成mysql),注意,不要先执行hive命令,否则这一步会出错,具体见http://stackoverflow.com/questions/35655306/hive-installation-issues-hive-metastore-database-is-not-initialized,下面执行:
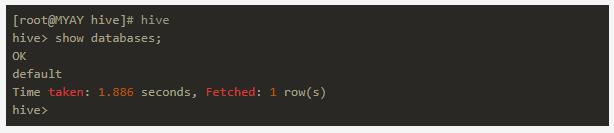
成功之后我们可以以客户端形式直接启动hive,如:
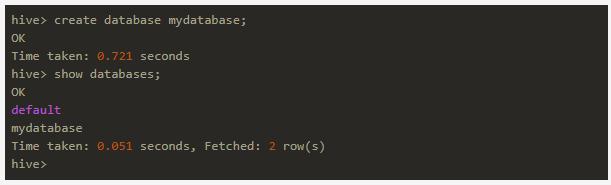
试着创建个数据库是否可以:
这样我们还是单机的hive,不能在其他机器登陆,所以我们要以server形式启动:
默认会监听10000端口,这时可以通过jdbc客户端连接这个服务访问hive
hive的具体使用在这里不赘述
spark部署
首先在http://spark.apache.org/downloads.html下载指定hadoop版本的安装包,我下载的是http://d3kbcqa49mib13.cloudfront.net/spark-2.0.0-bin-hadoop2.7.tgz
spark有多种部署方式,首先支持单机直接跑,如执行样例程序:
它可以直接运行得出结果
下面我们说下spark集群部署方法:
解压安装包后直接执行:
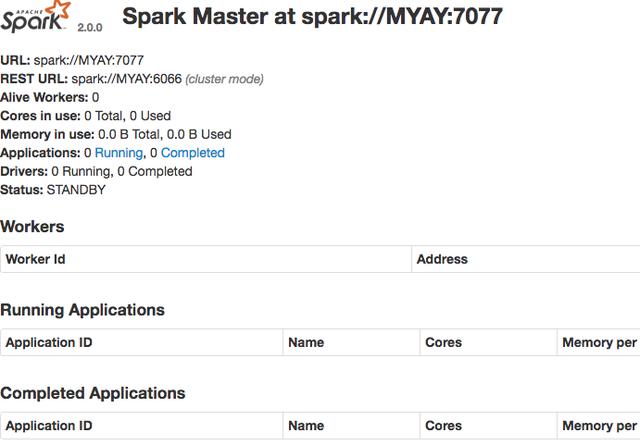
这时可以打开http://127.0.0.1:8080/看到web界面如下:
根据上面的url:spark://MYAY:7077,我们再启动slave:
刷新web界面如下:
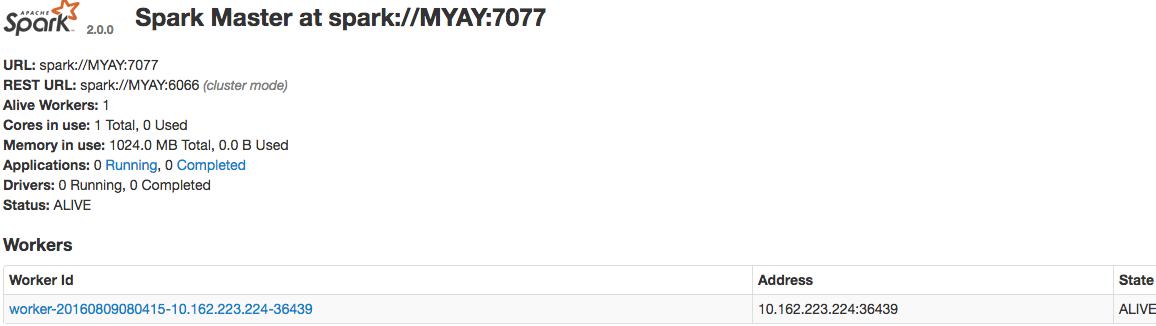
出现了一个worker,我们可以根据需要启动多个worker
下面我们把上面执行过的任务部署到spark集群上执行:
web界面如下:
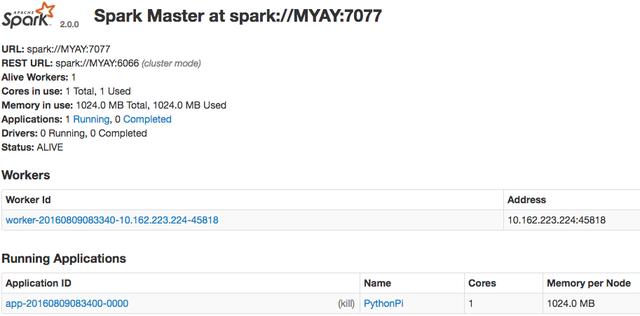
spark程序也可以部署到yarn集群上执行,也就是我们部署hadoop时启动的yarn
我们需要提前配置好HADOOP_CONF_DIR,如下:

下面我们把任务部署到yarn集群上去:

总结一下
- hdfs是所有hadoop生态的底层存储架构,它主要完成了分布式存储系统的逻辑,凡是需要存储的都基于其上构建
- yarn是负责集群资源管理的部分,这个资源主要指计算资源,因此它支撑了各种计算模块
- map-reduce组件主要完成了map-reduce任务的调度逻辑,它依赖于hdfs作为输入输出及中间过程的存储,因此在hdfs之上,它也依赖yarn为它分配资源,因此也在yarn之上
- hbase基于hdfs存储,通过独立的服务管理起来,因此仅在hdfs之上
- hive基于hdfs存储,通过独立的服务管理起来,因此仅在hdfs之上
- spark基于hdfs存储,即可以依赖yarn做资源分配计算资源也可以通过独立的服务管理,因此在hdfs之上也在yarn之上,从结构上看它和mapreduce一层比较像
总之,每一个系统负责了自己擅长的一部分,同时相互依托,形成了整个hadoop生态。