












先来看看这样一个故事:
“那是周五的晚上。我记得非常清楚,要去跟父母一同度假。那是他们是第一次去班加罗尔,我都计划好了带他们逛逛。工作已经完成,且一般周五晚都不会太忙。可就在下班时,对方突然发邮件问我要很早以前的报告,这份报告一年前就不再递交了。
虽然不高兴,不过运行标准的代码倒也不太费事。妈呀!我错了,耗了一晚上才整理完……”
这与我们的话题有什么关系?机智的你应该猜到了吧~
当今各个企业都将数据科学作为决策循环每个阶段的关键操纵杆,促成重要的商业战略。可是数据科学难在哪?数据分析师、商业分析师或数据科学家又是如何工作的呢?
所有数据科学的问题都可一分为二,一套“活动”和几步“绝佳操作过程”。
“活动”包括数据收集、数据清理、数据整理、假设验证、模型开发、验证等。如果你常与分析行业打交道,那对这些术语一定不陌生。
但“绝佳操作过程”却鲜有人知,实践的也不多。事实上,它强调最多的是项目管理、建立库、文件管理、沟通和代码维护。作为数据科学家,必须保证坚持“3个C”:
- consistency(一致)
- ommunication(沟通)
- consumption(消费)
工作要始终如一,与利益相关方沟通商业细节,最重要的是你在被消费。
“如今的企业都在找寻能够创造适用多个团队的方案的数据科学家。就好比一个产品,人人都用得心应手的那个。如此不但可以节省资金,不再浪费钱解决不同商业活动中相似的问题,还能节约时间和精力。”
数据科学中的编码与软件开发截然不同。不仅要知道怎么做,还得懂相当多的数据和商业内容。
今天笔者打算谈谈“一致”,以及如何在编码中做到这一点。在Mu Sigma商业方案工作的三年,以及至今遇到的所有挑战,让我总结出了许多绝佳经验。
下面这五点会简单讲解什么是“数学+商业+数据+科技=数据科学”,助你功力大增!
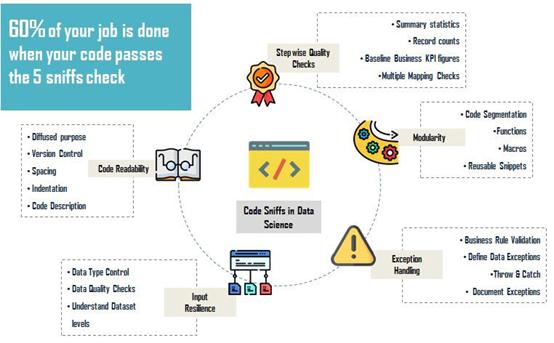
1. 代码可读性是否高
格式化良好且众人点评过的代码是天堂。它有助于轻松修补漏洞,确保顺利完成质量检查。每一个数据科学团队都追随“Peer Quality Checks(QC,同行质量检查)”的理念,以求数据能准确输出。在将最终结果递交之前先让同行过目,这是一种绝佳实践。可读代码包含:
- 项目名、代码目的、版本、作者名、创建日期、完善日期、最近一次修改、从哪些改变开始
- 在执行运算之前,每个代码片段都要有一行描述(通过这些代码准确获取商业规则信息或者使用的过滤系统)
- 每两个代码片段之间有适当的空格,留有足够距离
- 合理使用惯例命名表格。不要起“创建表格”的名字,可以换成“创建表格客户-页数-概述”。这样会让表格更直观,无需浏览余下的所有代码片段。
2. 代码是否具备可重复使用的模块
多数时候,我们都是根据当下的商业问题,运用相似模式不同过滤器处理数据集,或者用同一表格简要描述商业问题中的各种情况。
举个例子,现在你手中有一个客户数据集,信息包含客户ID、交易ID、交付日期、产品类型和销售数据。你被告知要找出给每个产品贡献80%销售额的顶级客户。
通常会创建一组专门的代码,复制粘贴后再利用另一个过滤器。而优秀的编码人员会站在用户角度创建模块,将产品类型和销售价格区域输入进去,得出理想的结果。
可重复使用的模块在所有平台都可创建,避免冗余的代码行,轻松实现质量控制。
3. 输入的代码是否可恢复
任何输入都可恢复就意味着不管输入什么类型,都可输出结果。代码实践中最棘手的问题就是让输入复原,实现代码的重复利用。
分析师可能会收到来自各个利益相关方的数据请求,理想的情况就是编写迎合各种商业请求的代码。
例如,电子设备和化妆品公司的销售主管想要了解各自客户信息对应的产品消费记录。分析师之前都是在笔记本或平板上操作的,知道所有电子产品名都是小写的。
但要核实化妆品信息,可能就要先过滤一遍所有的产品,然后看客户数据中与化妆品有关的交易如何。
但实际上,在产品列中用UPPER()就可避免不必要的检查。在现实世界中,很难做到每个输入的代码都可恢复,要考虑所有可控的例外情况。
4. 输出结果是否经得起数据和商业的常规检查
传输精准数据是项目制胜的关键。很多商业决策都基于报告的数据,一点点的差错都会造成巨大影响。
假如你被告知要根据客户交易额找到前百名忠实客户,企业会根据你推荐的结果给这些人提供30%的优惠。
理念就是找出铁杆顾客,引导其购买更多的产品。通过降低价格带来更高的交易额。然而很多人并没有意识到多数公司利用的数据集并不是绝对真实的,在用之前需要进行处理。
比如某客户付款时可能没有操作成功,但系统也记录下来了。最后在计算交易额时这种错误信息理应去除,否则得出的每位客户的交易额预算不会准确。难就难在识别异常信息。
以下是编码过程中必做的检查:
- 掌握指向业绩的关键风向标,有助于实现每一步的数据汇总。上述例子中,所有客户交易都是这个风向标。根据企业的年度报告,会发现近有12,000位客户在网站上购买产品。但是在查询数据时,只有8000名消费者的信息。数据准确吗?再次检查代码或跟利益相关方一同解决数据问题。
- 在进行任何操作之前必须检查数据集的级别。根据是否为单一数列还是组合数列对其进行划分,这些数列可以识别数据库或表格中的异常信息。帮助识别重复录入的部分,防止重复计算。
- 不管是加入一个或几个表格,都要确保在同一级别。一定要在所有加入信息显示前后追踪记录的数量。这将有助于识别多项数据图或重复计算的信息。
- 快速地给数据集做一个描述性统计。这将有助于找出数据分布和所有可能遗漏的值。
5. 引导处理例外情况
例外情况的处理,似乎和输入代码可恢复听起来有些相似,但操作完全不同。
问大家几个问题:你觉得一家企业的客户数据中包含多少条记录?是上面展示的20,252条吗?别开玩笑了!所有客户数据中各个产品的交易记录能达几百万条。在SQR、R、Python或Alteryx中查询都要花上几个小时。
试想一下,如果你需要查询不同产品的表格,如何处理意外情况呢?
- 保证检查查询时间。通常查询大型数据集所耗费的时间都超出预计,这是因为存在同时使用的情况,即多个用户会同时查询同一数据集。要保证代码运行超过一定程度时能够自动停止执行。
- 所有编程语言都允许设置执行例外处理,查询失败接下来的代码片段也会停止执行。这样,在出状况或有错误时就可立即采取必要的纠正措施,而不是等着整个代码执行完毕。
图源:unsplash
“我的手机突然震动了,一晃到已上午八点。过去的五个小时我都在找错误匹配的数字。虽然一年前就干这个,但我几乎记不起来任何使用过的商业规则。每一步的处理流程都不完善,质量控制数据不够,这让寻找问题变得更棘手。现在我可算认识到良好编码实践的重要性了。”
这个“痛心疾首”的故事,足以引起你对良好编码实践的重视了嘛~















