【51CTO.com原创稿件】深度学习驱动之下很早创业的中国AI独角兽旷视,宣布开源自研深度学习框架MegEngine(Brain++核心组件之一),中文名天元——取自围棋棋盘中心点的名称。
今天就来带大家体验一下天元深度学习框架,安装天元深度学习引擎需要Linux,目前天元只支持Linux,对于熟悉Windows的人员还不够友好。需要在Windows的sublinux中安装。除非安装双系统,Linux裸机,否则可能支持不了GPU深度学习加速。这一点还不够足够方便。但是国产的初创引擎可以理解,后面一定会改进的。
pip3 install megengine -f https://megengine.org.cn/whl/mge.html
这样就可以直接安装。
手写识别数据集的官网在这里,主要是手写识别的系列数据集。http://yann.lecun.com/exdb/mnist/index.html,我们可以从这里下载数据集。
MNIST数据集中的图片是28*28的,每张图被转化为一个行向量,长度是28*28=784,每一个值代表一个像素点。数据集中共有60000张手写数据图片,其中55000张训练数据,5000张测试数据。
在MNIST中,mnist.train.images是一个形状为[55000, 784]的张量,其中的第一个维度是用来索引图片,第二个维度是图片中的像素。MNIST数据集包含有三部分,训练数据集,验证数据集,测试数据集(mnist.validation)。
标签是介于0-9之间的数字,用于描述图片中的数字,转化为one-hot向量即表示的数字对应的下标为1,其余的值为0。标签的训练数据是[55000,10]的数字矩阵。
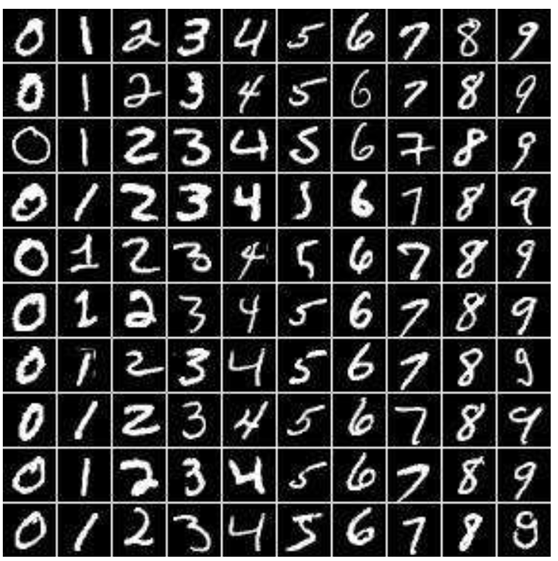
今天就来拿MNIST来做一个测试。
这是天元进行深度学习进行手写识别。今天就来测试一下深度学习的GPU场景下训练速度。
GPU用英伟达显卡1080ti。对比一下三大框架的训练速度,代码实现敏捷度。
下列是天元引擎代码。
- from megengine.data.dataset import MNIST #导入数据集
- train_dataset = MNIST(root="./dataset/MNIST", train=True, download=True)
- test_dataset = MNIST(root="./dataset/MNIST", train=False, download=False)
- import megengine.module as M
- import megengine.functional as F
- class Net(M.Module):
- def __init__(self):
- super().__init__()
- self.conv0 = M.Conv2d(1, 20, kernel_size=5, bias=False)
- self.bn0 = M.BatchNorm2d(20)
- self.relu0 = M.ReLU()
- self.pool0 = M.MaxPool2d(2)
- self.conv1 = M.Conv2d(20, 20, kernel_size=5, bias=False)
- self.bn1 = M.BatchNorm2d(20)
- self.relu1 = M.ReLU()
- self.pool1 = M.MaxPool2d(2)
- self.fc0 = M.Linear(500, 64, bias=True)
- self.relu2 = M.ReLU()
- self.fc1 = M.Linear(64, 10, bias=True)
- def forward(self, x):
- x = self.conv0(x)
- x = self.bn0(x)
- x = self.relu0(x)
- x = self.pool0(x)
- x = self.conv1(x)
- x = self.bn1(x)
- x = self.relu1(x)
- x = self.pool1(x)
- x = F.flatten(x, 1)
- x = self.fc0(x)
- x = self.relu2(x)
- x = self.fc1(x)
- return x
- from megengine.jit import trace
- @trace(symbolic=True)
- def train_func(data, label, *, opt, net):
- net.train()
- pred = net(data)
- loss = F.cross_entropy_with_softmax(pred, label)
- opt.backward(loss)
- return pred, loss
- @trace(symbolic=True)
- def eval_func(data, label, *, net):
- net.eval()
- pred = net(data)
- loss = F.cross_entropy_with_softmax(pred, label)
- return pred, loss
- import time
- import numpy as np
- import megengine as mge
- from megengine.optimizer import SGD
- from megengine.data import DataLoader
- from megengine.data.transform import ToMode, Pad, Normalize, Compose
- from megengine.data.sampler import RandomSampler
- # 读取训练数据并进行预处理
- dataloader = DataLoader(
- train_dataset,
- transform=Compose([
- Normalize(mean=0.1307*255, std=0.3081*255),
- Pad(2),
- ToMode('CHW'),
- ]),
- sampler=RandomSampler(dataset=train_dataset, batch_size=64),
- # 训练时一般使用RandomSampler来打乱数据顺序
- )
- # 实例化网络
- net = Net()
- # SGD优化方法,学习率lr=0.01,动量momentum=0.9
- optimizer = SGD(net.parameters(), lr=0.01, momentum=0.9, weight_decay=5e-4)
- total_epochs = 10 # 共运行10个epoch
- for epoch in range(total_epochs):
- total_loss = 0
- for step, (batch_data, batch_label) in enumerate(dataloader):
- batch_label = batch_label.astype(np.int32)
- optimizer.zero_grad() # 将参数的梯度置零
- pred, loss = train_func(batch_data, batch_label, opt=optimizer, net=net)
- optimizer.step() # 根据梯度更新参数值
- total_loss += loss.numpy().item()
- print("epoch: {}, loss {}".format(epoch, total_loss/len(dataloader)))
- mge.save(net.state_dict(), 'mnist_net.mge')
- net = Net()
- state_dict = mge.load('mnist_net.mge')
- net.load_state_dict(state_dict)
- from megengine.data.sampler import SequentialSampler
- # 测试数据
- test_sampler = SequentialSampler(test_dataset, batch_size=500)
- dataloader_test = DataLoader(
- test_dataset,
- sampler=test_sampler,
- transform=Compose([
- Normalize(mean=0.1307*255, std=0.3081*255),
- Pad(2),
- ToMode('CHW'),
- ]),
- )
- correct = 0
- total = 0
- for idx, (batch_data, batch_label) in enumerate(dataloader_test):
- batch_label = batch_label.astype(np.int32)
- pred, loss = eval_func(batch_data, batch_label, net=net)
- predicted = F.argmax(pred, axis=1)
- correct += (predicted == batch_label).sum().numpy().item()
- total += batch_label.shape[0]
- print("correct: {}, total: {}, accuracy: {}".format(correct, total, float(correct) / total))
这是TensorFlow版本。
- import tensorflow as tf
- import numpy as np
- from tensorflow.examples.tutorials.mnist import input_data
- import matplotlib.pyplot as plt
- mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
- tf.reset_default_graph()
- x = tf.placeholder(tf.float32, [None, 784])
- y = tf.placeholder(tf.float32, [None, 10])
- w = tf.Variable(tf.random_normal([784, 10]))
- b = tf.Variable(tf.zeros([10]))
- pred = tf.matmul(x, w) + b
- pred = tf.nn.softmax(pred)
- cost = tf.reduce_mean(-tf.reduce_sum(y * tf.log(pred), reduction_indices=1))
- learning_rate = 0.01
- optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost)
- training_epochs = 25
- batch_size = 100
- display_step = 1
- save_path = 'model/'
- saver = tf.train.Saver()
- with tf.Session() as sess:
- sess.run(tf.global_variables_initializer())
- for epoch in range(training_epochs):
- avg_cost = 0
- total_batch = int(mnist.train.num_examples/batch_size)
- for i in range(total_batch):
- batch_xs, batch_ys = mnist.train.next_batch(batch_size)
- _, c = sess.run([optimizer, cost], feed_dict={x:batch_xs, y:batch_ys})
- avg_cost += c / total_batch
- if (epoch + 1) % display_step == 0:
- print('epoch= ', epoch+1, ' cost= ', avg_cost)
- print('finished')
- correct_prediction = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
- accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
- print('accuracy: ', accuracy.eval({x:mnist.test.images, y:mnist.test.labels}))
- save = saver.save(sess, save_path=save_path+'mnist.cpkt')
- print(" starting 2nd session ...... ")
- with tf.Session() as sess:
- sess.run(tf.global_variables_initializer())
- saver.restore(sess, save_path=save_path+'mnist.cpkt')
- correct_prediction = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
- accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
- print('accuracy: ', accuracy.eval({x: mnist.test.images, y: mnist.test.labels}))
- output = tf.argmax(pred, 1)
- batch_xs, batch_ys = mnist.test.next_batch(2)
- outputval= sess.run([output], feed_dict={x:batch_xs, y:batch_ys})
- print(outputval)
- im = batch_xs[0]
- im = im.reshape(-1, 28)
- plt.imshow(im, cmap='gray')
- plt.show()
- im = batch_xs[1]
- im = im.reshape(-1, 28)
- plt.imshow(im, cmap='gray')
- plt.show()
这是PyTorch版本。
- import torch
- import torch.nn as nn
- import torch.nn.functional as F
- import torch.optim as optim
- from torchvision import datasets, transforms
- from torch.autograd import Variable
- batch_size = 64
- train_dataset = datasets.MNIST(root='./data/',
- train=True,
- transform=transforms.ToTensor(),
- download=True)
- test_dataset = datasets.MNIST(root='./data/',
- train=False,
- transform=transforms.ToTensor())
- # Data Loader (Input Pipeline)
- train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
- batch_size=batch_size,
- shuffle=True)
- test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
- batch_size=batch_size,
- shuffle=False)
- class Net(nn.Module):
- def __init__(self):
- super(Net, self).__init__()
- # 输入1通道,输出10通道,kernel 5*5
- self.conv1 = nn.Conv2d(in_channels=1, out_channels=10, kernel_size=5)
- self.conv2 = nn.Conv2d(10, 20, 5)
- self.conv3 = nn.Conv2d(20, 40, 3)
- self.mp = nn.MaxPool2d(2)
- # fully connect
- self.fc = nn.Linear(40, 10)#(in_features, out_features)
- def forward(self, x):
- # in_size = 64
- in_size = x.size(0) # one batch 此时的x是包含batchsize维度为4的tensor,
- 即(batchsize,channels,x,y),x.size(0)指batchsize的值
- 把batchsize的值作为网络的in_size
- # x: 64*1*28*28
- x = F.relu(self.mp(self.conv1(x)))
- # x: 64*10*12*12 feature map =[(28-4)/2]^2=12*12
- x = F.relu(self.mp(self.conv2(x)))
- # x: 64*20*4*4
- x = F.relu(self.mp(self.conv3(x)))
- x = x.view(in_size, -1) # flatten the tensor 相当于resharp
- # print(x.size())
- # x: 64*320
- x = self.fc(x)
- # x:64*10
- # print(x.size())
- return F.log_softmax(x) #64*10
- model = Net()
- optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
- def train(epoch):
- for batch_idx, (data, target) in enumerate(train_loader):
- #batch_idx是enumerate()函数自带的索引,从0开始
- # data.size():[64, 1, 28, 28]
- # target.size():[64]
- output = model(data)
- #output:64*10
- loss = F.nll_loss(output, target)
- if batch_idx % 200 == 0:
- print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
- epoch, batch_idx * len(data), len(train_loader.dataset),
- 100. * batch_idx / len(train_loader), loss.data[0]))
- optimizer.zero_grad() # 所有参数的梯度清零
- loss.backward() #即反向传播求梯度
- optimizer.step() #调用optimizer进行梯度下降更新参数
- def test():
- test_loss = 0
- correct = 0
- for data, target in test_loader:
- data, target = Variable(data, volatile=True), Variable(target)
- output = model(data)
- # sum up batch loss
- test_loss += F.nll_loss(output, target, size_average=False).data[0]
- # get the index of the max log-probability
- pred = output.data.max(1, keepdim=True)[1]
- print(pred)
- correct += pred.eq(target.data.view_as(pred)).cpu().sum()
- test_loss /= len(test_loader.dataset)
- print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
- test_loss, correct, len(test_loader.dataset),
- 100. * correct / len(test_loader.dataset)))
- for epoch in range(1, 10):
- train(epoch)
- test()
测试时间,在1080ti,Ubuntu 18.04的系统下,训练时间如下。
MegEngine 45.3429
TensorFlow 87.3634
PyTorch 68.8535
弄完代码测试完了以后,对于天元深度学习框架与TensorFlow与PyTorch进行了一下小节。
1.易用性
易用性上,MegEngine与PyTorch最为简洁,代码比TensorFlow要简洁优化的多,并且无缝兼容PyTorch。TensorFlow较为复杂,学习难度较大。如果要快速上手,用MegEngine也不错。
TensorFlow是比较不友好的,与Python等语言差距很大,有点像基于一种语言重新定义了一种编程语言,并且在调试的时候比较复杂。每次版本的更新,TensorFlow的各种接口经常会有很大幅度的改变,这也大大增加了对其的学习时间。
PyTorch支持动态计算图,追求尽量少的封装,代码简洁易读,应用十分灵活,接口沿用Torch,具有很强的易用性,同时可以很好的利用主语言Python的各种优势。
对于文档的详细程度,TensorFlow具备十分详尽的官方文档,查找起来十分方便,同时保持很快的更新速度,但是条理不是很清晰,教程众多。MegEngine与PyTorch相对而言,条理清晰。PyTorch案例丰富度略多,MegEngine还在建设,相信将来一定会很多。整体而言,易用性上MegEngine与PyTorch差不多。TensorFlow的易用性最差。 MegEngine可以无缝借用PyTorch的所有案例,这一点兼容性上做的非常赞。
2.速度
旷世对写出的天元深度学习框架做了许多优化,在我的显卡1080ti的状态MegEngine >PyTorch>TensorFlow。就单机训练速度而言,MegEngine速度相当快,并且用的内存最小。据说MegEngine采用静态内存分配,做到了极致的内存优化。这一点上来说是相当难得的。
3.算子数量
这一点TensorFlow无疑是最大的赢家,提供的Python API达到8000多个(参见https://tensorflow.google.cn/api_docs/python),基本上不存在用户找不到的算子,所有的算法都可以用TensorFlow算子拼出来。不过API过多也是个负担,又是low level又是high level,容易把用户整晕。PyTorch的算子其次,优化较TensorFlow较多。天元深度学习框架算子数量目前最少,但是优化较好,算子质量较高。其中任意图在训练MNIST上就有很大帮助。目前TensorFlow与PyTorch都不支持。
4.开源模型数据集案例
目前TensorFlow>PyTorch>MegEngine,这一块TensorFlow时间最久,案例最多,PyTorch其次,MegEngine最少。
5.开源社区
目前MegEngine的开源社区最小,不过也在筹备组建中,尽早加入也能成为类似PyTorch,TensorFlow社区的大牛。如果招聘天元深度学习框架的人越多,可能促进学习的人越多。目前国产还在起步路上,但是非常看好天元的深度学习框架的未来。
6.灵活性
TensorFlow主要支持静态计算图的形式,计算图的结构比较直观,但是在调试过程中十分复杂与麻烦,一些错误更加难以发现。但是在2017年底发布了动态图机制Eager Execution,加入对于动态计算图的支持,但是目前依旧采用原有的静态计算图形式为主。TensorFlow拥有TensorBoard应用,可以监控运行过程,可视化计算图。
PyTorch为动态计算图的典型代表,便于调试,并且高度模块化,搭建模型十分方便,同时具备极其优秀的GPU支持,数据参数在CPU与GPU之间迁移十分灵活。MegEngine无缝兼容PyTorch,并且具备动态图这样的优点,在分布式部署,模型推断上有较大优势。MegEngine的灵活性相比TensorFlow有较大优势。
以表格的形式对比如下:
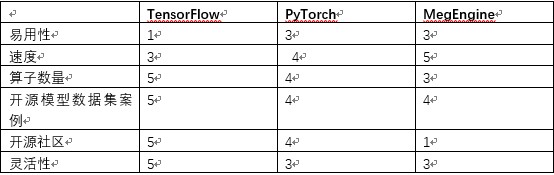
注:分数越高越好
总结下MegEngine 有下列优点。
- 上手简单
- 兼容PyTorch
- 支持静态图/动态图两种机制
- 中文教程详细
- 中文社区,有利于英文不好的童鞋。
也有一些不足有待改进。
- 支持 Windows/Mac及其他 Linux发行版。目前只支持 Ubuntu 16.04 及以上,这个确实有点少。而且应该还不支持 Docker等安装方式。
- 更多的案例库与模型库。
- 尽量早日进驻各大高校,有教材与教程,建立中国自己的AI人才梯队。
希望MegEngine为中国的人工智能产业做出自己的贡献,打造中国智造的人工智能深度学习引擎,为中华民族崛起贡献自己的光辉力量,我们也可以好好用用国产深度学习引擎,打造我们伟大的祖国成为AI强国。
作者介绍:
尹成,清华硕士,微软人工智能领域全球最有价值专家,精通C/C++,Python,Go,TensorFlow,拥有15年编程经验与5年的教学经验,资深软件架构师,Intel软件技术专家 ,具备深厚的项目管理经验以及研发经验,拥有两项人工智能发明专利。
51CTO的世界五百强算法课
https://edu.51cto.com/sd/0a881
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】