本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
数据集太小了,无法训练GAN?试试从单个图像入手吧。
去年谷歌就提出了SinGAN,是第一个拿GAN在单幅自然图像学习的非条件生成模型(ICCV 2019最佳论文)。
而最近,来自Adobe和汉堡大学的研究人员,对这个方法做了改进,探讨了几种让GAN在单幅图像提高训练和生成能力的机制。
研究人员将改进的模型称作ConSinGAN。

那么,先来看下ConSinGAN的效果吧。

上图左侧是用来训练的单个图像,右侧是利用ConSinGAN训练后生成的复杂全局结构。
可以看出效果还是比较逼真。
当然,ConSinGAN还可以用来处理许多其他任务,例如图像超分辨率( image super-resolution)、图像动画(image animation),以及图像去雾(image dehazing)。
下面两张就是它在图像协调(image harmonization)和图像编辑(image editing)上的效果。


ConSinGAN是怎么做到的呢?
训练架构优化:并行的SinGAN
首先,我们先来看下SinGAN的训练过程。
SinGAN在图像中训练几个单独的生成网络,下图便是第一个生成器,也是唯一从随机噪声生成图像的无条件生成器。
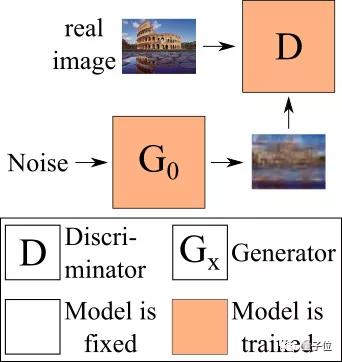
△在SinGAN中训练的第一个生成器
这里的判别器从来不将图像看做一个整体,通过这种方法,它就可以知道“真实的”图像补丁(patch)是什么样子。
这样,生成器就可以通过生成,在全局来看不同,但仅从补丁来看却相似的图像,来达到“欺诈”的目的。
在更高分辨率上工作的生成器,将前一个生成器生成的图像作为输入,在此基础上生成比当前还要高分辨率的图像。
所有的生成器都是单独训练的,这意味着在训练当前生成器时,所有以前的生成器的权重都保持不变。
这一过程如下图所示。
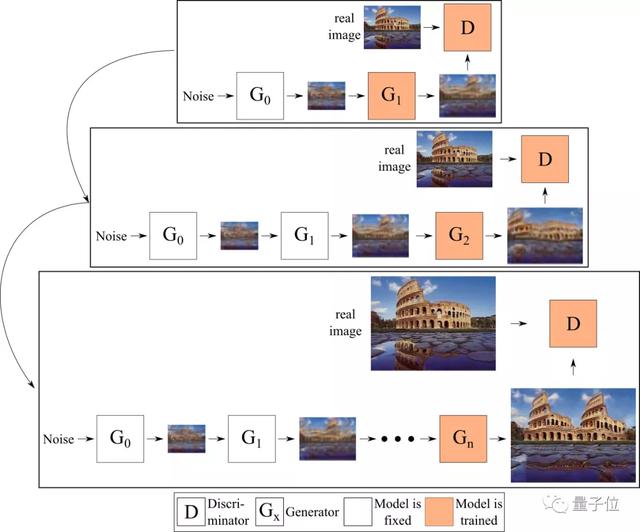
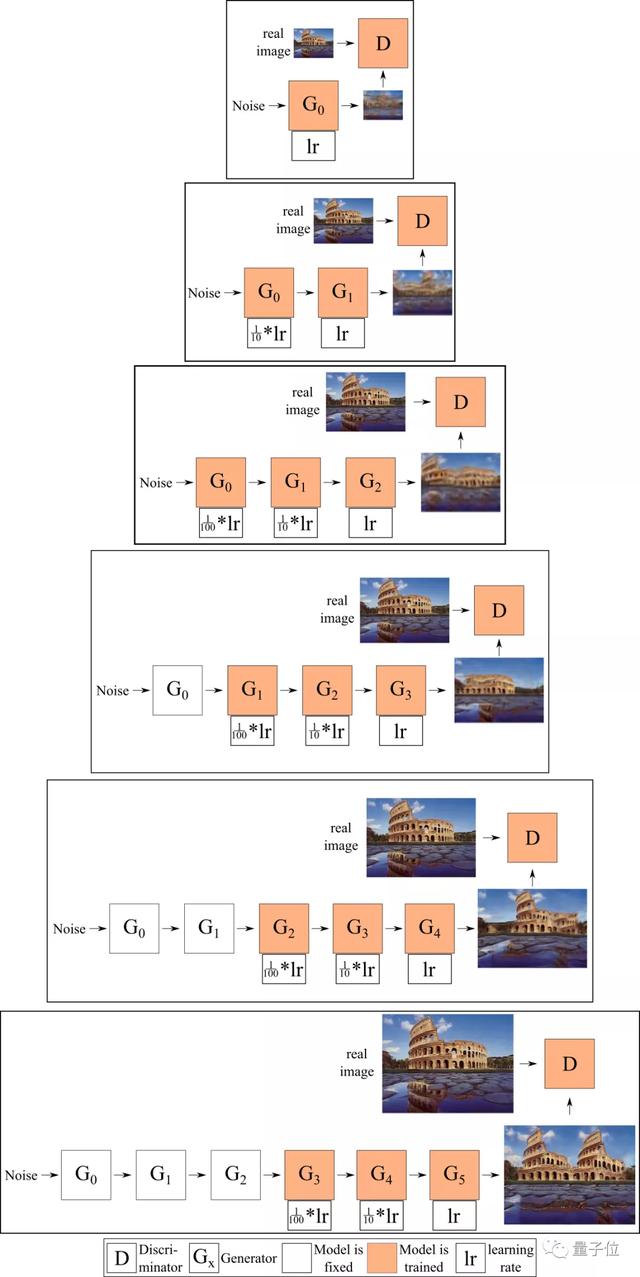
而在Adobe与汉堡大学的研究人员发现,在给定的时间内仅能训练一个生成器,并将图像(而不是特征图)从一个生成器传输到下一个生成器,这就限制了生成器之间的交互。
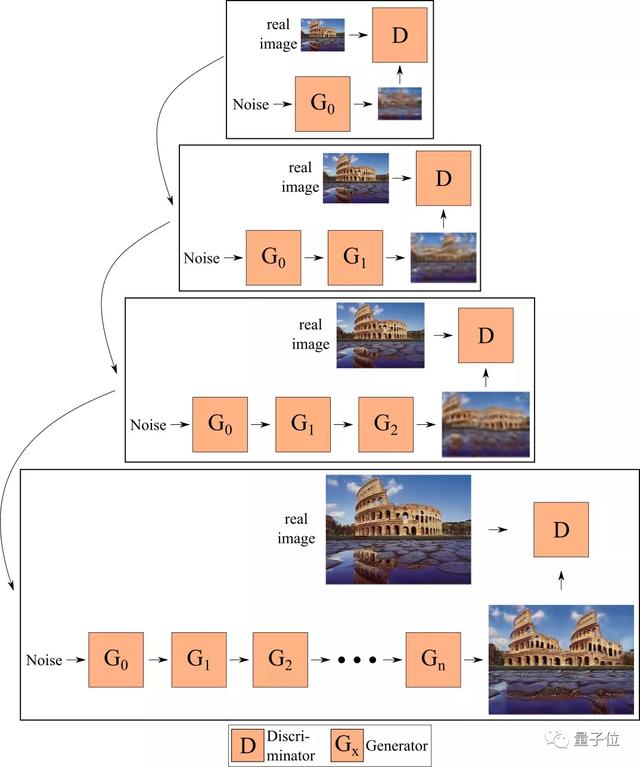
因此,他们对生成器进行了端到端的训练,也就是说,在给定时间内训练多个生成器,每个生成器将前一个生成器生成的特征(而不是图像)作为输入。
这也就是ConSinGAN名字的由来——并行的SinGAN,过程如下图所示。
然而,采取这样的措施又会面临一个问题,也就是过拟合。这意味着最终的模型不会生成任何“新”图像,而是只生成训练图像。
为了防止这种现象发生,研究人员采取了2个措施:
- 在任意给定时间内,只训练一部分生成器;
- 对不同的生成器采用不同的学习率(learning rate)。
下图就展示了使用这两种方法实现的模型。默认情况下,最多同时训练3个生成器,并对较低的生成器,分别将学习率调至1/10和1/100。
在这个过程中,有一个有趣的现象。
如果对较低的生成器采用较高的学习率,那么生成的图像质量会高些,但是差异性较弱。
相反,如果对较低的生成器采用较小的学习率,那么生成图像的差异性会丰富一些。如下图所示。

代码已开源
ConSinGAN的代码已经在GitHub上开源。
老规矩,先介绍一下运行所需要的环境:Python 3.5;Pytorch 1.1.0。
安装也非常简单:
pip install -r requirements.txt
- 1.
若要使用论文中的默认参数训练模型:
python main_train.py --gpu 0 --train_mode generation --input_name Images/Generation/angkorwat.jpg
- 1.
在英伟达GeForce GTX 1080Ti上训练一个模型大约需要20-25分钟。
不同的学习率和训练阶段数量,会影响实验的结果,研究人员推荐二者的默认值分别是0.1和6。
当然也可以修改学习率:
python main_train.py --gpu 0 --train_mode generation --input_name Images/Generation/colusseum.jpg --lr_scale 0.5
- 1.
修改训练阶段的数量:
python main_train.py --gpu 0 --train_mode generation --input_name Images/Generation/colusseum.jpg --train_stages 7
- 1.
当然,模型也可以用来处理“图像协调”和“图像编辑”等任务,详情可参阅GitHub。
传送门
论文地址:
https://arxiv.org/pdf/2003.11512.pdf
GitHub项目地址:
https://github.com/tohinz/ConSinGAN