我们知道,微服务架构由多个相对简单的服务组成,依赖服务之间的隔离性降低系统复杂度。理论上拆解完备的微服务,不应当存在过多业务代码复用的机会,因为服务之间的有效的隔离会使得各自代码只关注自身的上下文,微服务的边界清晰不但包含职责清晰,从代码层面也应当清晰隔离。
但微服务群组产出的两类代码,我们仍然建议被公用:
第一类是交互协议代码,微服务之间交互协议标准的代码,由于每个独立微服务单一职责都有自身边界,微服务之间交互就被暴露为新的特征。交互协议标准代码公用,也可以看做以微服务容易理解的方式公布出来,有利于维护微服务之间交互的便利性和精确性。
第二类是纯工具类代码,这部分代码独立于微服务群的业务特征,往往是提供更低层次的函数库或组件,如版本比较、时间对比工具、上传资源组件等。这一类代码应当视为第三方独立仓库,类似我们引用的 Github 上的开源库。
第二类代码相对简单,作为独立于微服务业务群组的仓库存在即可。对于第一类,微服务之间同步的信息传递,往往是通过 HTTP、PRC 等通信协议,并依据交互双方定义的业务协议将传递的 JSON 或 Protobuf 等解析为业务可理解的信息。这部分交互相关的代码可以被视为公用代码。本文来探讨这部分代码在整个微服务体系中如何更好的被组织和使用,以提升研发效率并减少相关故障。
此部分代码组织的问题,本质上并非为系统或模块的依赖问题,而是在微服务架构体系中,如何更方便的同步和使用公用代码的问题。我司在走上了微服务修行的不归之路后,此部分交互代码组织也经历了不同的阶段,本文会借此案例进行探讨。Go 是我司的指定语言,本文的一些示例和特性是用 Golang 来展示,Git 是最流行的分布式版本控制系统,讨论也基于 Git。
1. 交互示例
讨论之初,我们首先列出微服务之间交互的代码和目录结构示例,及简单的三个定义:
- 源服务:产出 Model、Client 的服务。
- Model:定义数据模型的代码,作为微服务业务之间的交互协议编码解析使用。
- Client:微服务发起请求的代码,并使用 Model 来解析相互传递的数据,通常是源服务提供 API 时候,可以附带提供。
微服务交互的简化代码及目录如下,其中 model 存放数据模型代码,client 存放网络请求代码:
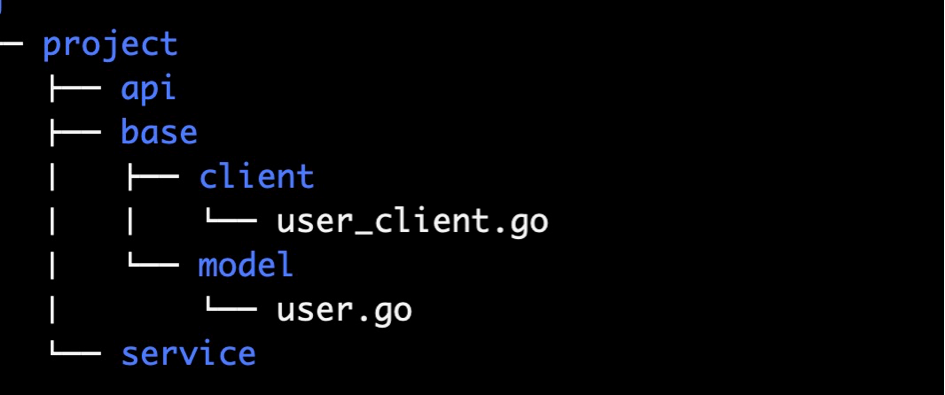
数据模型实体代码:project/base/model/user.go
- type User struct {
- UserID int64 `json:"user_id" form:"user_id"`
- UserName string `json:"user_name" form:"user_name"`
- Status int `json:"status" form:"status"`
- Avatar string `json:"avatar" form:"avatar"`
- AvatarSmall string `json:"avatar_small" form:"avatar_small"`
- }
交互请求代码:
- project/base/client/user_client.go
- url := "http://<demo.com>/project/<user-info-api>"
- userClient := http.Client{
- Timeout: time.Second * 2, // Maximum of 2 secs
- }
- req, _ := http.NewRequest(http.MethodGet, url, nil)
- res, _ := userClient.Do(req)
- body, _ := ioutil.ReadAll(res.Body)
- user := model.User{}
- jsonErr := json.Unmarshal(body, &user)
- if jsonErr != nil {
- log.Fatal(jsonErr)
- }
- fmt.Println(user.UserName)
2. 练气期——手工拷贝:
微服务的核心意义不止是服务拆分,也在于团队的组织和沟通形式也在调整。团队初始切换为微服务时候,各个成员从源服务拷贝 data 内 model 和 client 至各自相关服务。虽然代码拷贝后各自修改完全不影响,但随着服务数目的增多,找源服务拷贝代码越来越麻烦,大家的沟通过程通常是:
A:“兄弟们,我代码提了。”
B:“又改了啊!改了哪些。”
A:“xxx xxx xxx xxx xxx xxx xxx xxx xxx ”,
B:“靠,这么多,你把文件传给我!”
G:“我也要!”
这种全凭人力来维护代码的过程,容易缺失修改文件的。且更新操作不顺畅,长期容易导致相关微服务和源服务维护的 base 差异较大。从源服务拷贝回来的代码,和自身项目库的约束并无二致,可以被任意修改,容易因本地的手工修改而引发协议的不一致,随着团队人员增加和规模扩大,这种方式开始被组员吐槽和诟病。
3. 筑基期——集中仓库
程序员是不会满足现状的,程序员天生就是要解决手动操作的问题,拷贝代码这种原始而粗暴的手段自然很容易被淘汰掉。有成员提出创建个单独的仓库来集中管理各微服务 base 代码,代码从源服务被手工拷贝至 base 仓库,所有成员从这个单独的 base 仓库拉取更新,简直是顺理成章。团队成员一致认为这简直是修仙进阶的必然趋势,所有人一拍即合。
调整为统一的代码仓库后,虽然仍旧需要手动拷贝到 base 仓库代码。但使用方操作简单,只需有事没事,拉取下 base 仓库就可以拉到最新的依赖代码。而且整个团队微服务之间交互的所有的 client 和 model 都可以在 base 里直接找到。大家对 base 仓库的认知统一,一时间歌舞升平,相安无事。
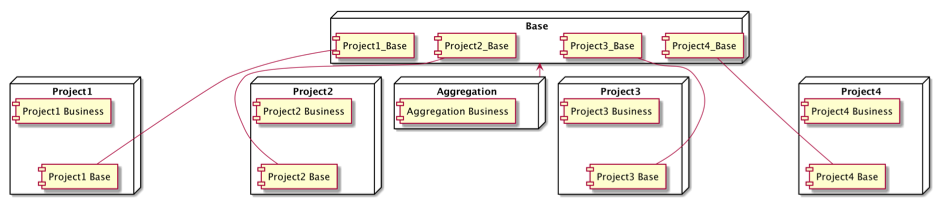
整个代码仓库组织如下,其中 base 仓库包含多个 project-base 目录,该目录与 project 仓库里 base 目录完全一致:
此时团队成员沟通的过程通常是:
A、B 、C、D、E、F、G:“push!push!push!push!”
A:“兄弟们,我代码提了,更新下 base!”
B、C、D、E、F、G:“pull!pull!pull!pull!”
在 95% 的情况下,大家的合作沟通都是是愉快的,然而也有倒血霉的时候,特别是当小 G 被迫紧急修复一个半年内都处于稳定维护期的项目时:
A、B、C、D、E、F、G:持续默默提交…
G:“pull!”
G:“苍天,我只要更新 B 的一个更新,为啥 pull 下来几百个更新,我编译不过啊!嘤嘤嘤。”
小 G 很负责任,嘤嘤之后还得解决问题,好容易深夜两点解决完毕,终于上线了,殊不知更惨的还在后面,深夜四点被监控告警叫起来,因为刚才的上线引发了一起线上事故。
老板:“这个线上事故影响面大,小 G 明天复盘一下!”
G:“我只是想更新了 B 的 base,A、B、C、D、E、F 几个月那么多更新,我哪知道掉坑里了啊。”小 G 嚎啕大哭。
问题根源:
集中仓库 Base 为各个微服务的 base 代码合集,一次更新会导致全部更新,无法单独更新某一部分 Base。如示例中 aggregation 项目更新 project1-base 时,project2-base、project3-base、project4-base 也会被 Git 无脑直接更新,这些代码的改动,通常不在预期和测试的范围之内。base 内只有数据结构和请求代码相对比较简单,虽然长期天下太平,但冷不丁也会祸起萧墙。要牢记,任何更改都不安全,如何减少公用代码仓库的变更的影响范围,是我们要去探究的。
4. 结丹期——独立子仓库
小 G 痛定思痛,第二天肿着双眼来到了公司,拉上研发的小伙伴们进行复盘,复盘的结果是,这种统一集中仓库管理的方式,肯定有改进空间,大家七嘴八舌:
B:“可以打 Tag”
G:“不行,解决不了我要部分更新,拉下一堆更新的问题。”
C:“可以直接引用源项目,Go vendor 只会复制需要文件到当前工程”
D:“不行,直接引用微服务代码心理负担比较重,也容易诱导直接使用源微服务里其他代码引起混乱,而且,对于跨部门且代码权限有差异时,此方案不适用,如保密级别高的工程。”
E:“……”
小 G 的眼泪没有白流,一番讨论后,大家明确了目标:应该将集中仓库拆分或者分割引用,但又需要有便捷的子仓库拆分和同步方案,避免手工拷贝,才容易被接受推广,毕竟大家都是懒人。
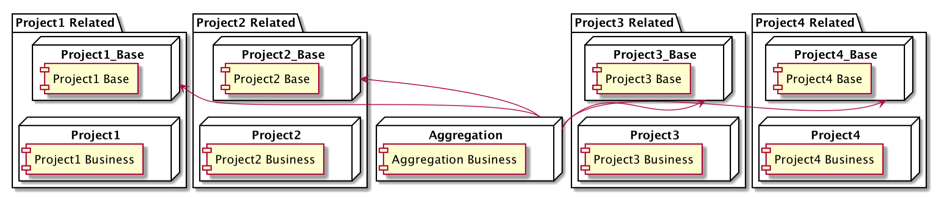
目标明确了,小 G 一顿猛如虎的调研后,惊喜的发现:Git 虽然没有可以使得 G 仓库直接引用 B 仓库某个目录的功能,但已经有 B 项目的子目录,直接和 B-Base 子仓库保持同步的内置功能:git subtree 。B 仓库子目录和 B-Base 子仓库保持同步,小 G 直接使用 B-Base 子仓库即可。这一定是有不少同行也给 Git 提过类似的需求,虽然工具仍还不够完美,但我们做些限制,只有源仓库提交,只用它最基本的功能仍然够用!小 G 感慨,早发现就好了。独立子仓库同步机制详述下文列出。
此时的代码仓库组织形式如下:
A:“兄弟们,我代码提了,有需要的更新下我的 Base”
B、C、D、E、F:无视之。
G:“好嘞!pull A-base!”
此方案虽然也有一些额外成本,比如小仓库数增多,需要大家了解 git subtree 命令。但是权衡比较,正向收益居多,而且 git subtree 命令也可以被直接使用脚本或 Git 钩子直接屏蔽,使得更新范围更加可控的同时,更加便捷自动化。
这种方案使⽤用现有的工具体系,未增加学习成本,同时微服务的所有者可以决定何时选择同步该修改到服务中,有效减少了未经测试代码直接进⼊线上而引发故障概率。
对于前文所述的纯工具类代码,我们也建议避免包揽万象的工具仓库,例如 common 仓库。更好的方法是把包揽万象库按功能拆分成具有独立上下文的多个库,例如创建基于上下文的 storage、util、log 等仓库。这能够把不经常改变的代码和频繁改动的代码分离开,使用方自行控制每次变更范围。
独立子仓库同步机制详述:
格式约定:
约定对每个微服务,创建相对应的子仓库,仓库名以<-base>为后缀,比如,Project1 对应子仓库为 Project1-base <git@gitlab.company.com:back-end/project1-base.git>
约定在源微服务代码组织中创建 base 包,model 和 client 存放其中(命名也可以根据自己公司规范),如图:
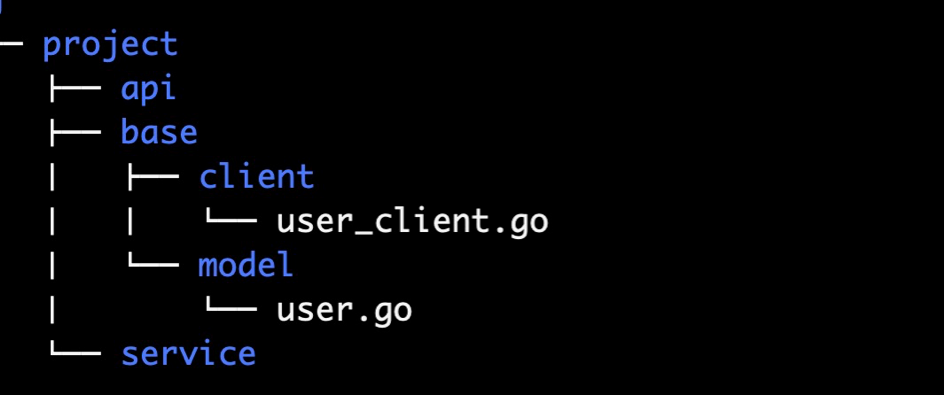
约定其他微服务需要和源微服务交互时候,直接使用子仓库。由于子仓库是完全看做独立的仓库来依赖,日常更新普通的 git pull 命令即可。
源服务 base 仓库拆分:
源服务 base 仓库拆分的核心命令如下:
- cd <project-folder>
- # 无base目录时,直接添加子仓库
- git subtree add -P base <git@gitlab.company.com:back-end/project-base.git> master
- # 如果base已经存在,先拆分提交至子仓库,再删除本地后关联远程子仓库。
cd <project-folder># 无base目录时,直接添加子仓库git subtree add -P base <git@gitlab.company.com:back-end/project-base.git> master# 如果base已经存在,先拆分提交至子仓库,再删除本地后关联远程子仓库。
日常同步:
日常提交限定在源服务内,避免过多使用高阶 gitsubtree 命令。提交过多后定期 git subtree split --rejoin 来解决提交都需要重头遍历 commits 耗时过长的问题, 建议通过脚本和 Git 钩子来自动化:
- # 提交
- git subtree push -P <name-of-folder> <git@gitlab.company.com:back-end/project1-base.git> master
- # 更新
- git subtree pull -P <name-of-folder> <git@gitlab.company.com:back-end/project1-base.git> master
5. 总结讨论
公用代码组织形式演进的过程,是繁杂宏大的研发工程中一个细小的工具化和规范化的流程。通常,集中仓库的方式操作简单直观,也容易被认同,绝大部分时间也都可以运转正常。伴随着问题的驱动,我们切换至更精细的独立子仓库方式。独立子仓库方案使用现有的工具体系,在不增加复杂度的情况下,提供自动推送变更以及可选择同步公用代码能力。实践中有效提高效率,也减少了未经测试代码直接进入线上而引发故障概率,是本文推荐的方案。
当然,我们看到每种方案在各公司也有不同实践,如有的公司手工拷贝代码使用的也很好。在实践中可以根据自己团队的口味来选择方案,更欢迎有更好经验的小伙伴来交流。
6. 作者介绍
奇正,曾在奥多比 、百度任高级工程师,现任某互联网公司后端业务线 Leader,先后从事过 C++、Android,Golang 开发工作。