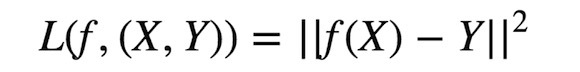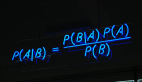不管你是机器学习的初学者,还是中级程序员,你都可能此问题感到困惑。如何建立备忘单?从本文中你能学到什么?
在机器学习中,没有任何一种方案可以解决所有问题。由于算法种类繁多,很难找出正确的算法来解决问题。
不过无需担心,在本文中,我们将介绍如何使用备忘单简化机器学习方法,你可以使用该备忘单选择适合解决问题的正确算法。
以下为备忘单-你需要了解机器学习的技巧。
备忘单使用指南
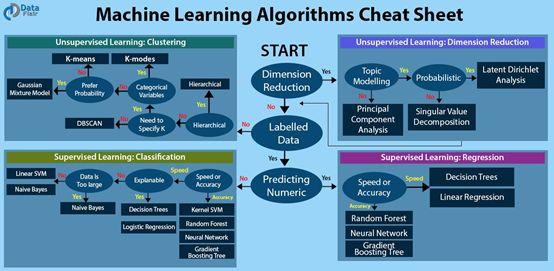
选择算法时需要考虑的因素
有几个因素会影响你的选择。有一些问题较为特殊,需要专门的方法解决。例如,推荐系统可用于解决此类问题。虽然某些类型的问题是开放的,但它们需要反复试验、排除错误。监督学习、分类和回归是解决开放类问题的方案。
- 你想对数据执行什么操作—分类、回归还是聚类?
- 大小:在选择算法时,数据集的大小(无论大小)很重要。
- 质量:你的数据集中有多少变化,数据集是否平衡。
- 数据性质:我们是否标记了数据?模型的输入和输出如何表示?
- 时间可用性:你需要花费多少时间来构建和训练模型。某些模型可以更快地构建,但准确性会逊色一些。
- 速度或准确性:对于可用于生产的模型,你可能对准确性有较高的要求,但有时计算速度更快的快速工作模型就可以满足你的需求。
若想使用备忘单,你只需查看图表上的选择标签,然后移向回答问题的箭头。例如:
- 如果你想减少维度数量并且不需要主题建模,请使用PCA。
- 如果要预测某个变量的数值,且需要较高的准确性,则应尝试使用“随机森林”、“神经网络”或“梯度提升”树。
- 如果你没有标记数据并想执行聚类,则可以使用k-近邻聚类算法。
选择正确的算法
值得一提的是,即使是经验丰富的数据科学家也无法在不尝试其他算法的情况下分辨出哪种算法效果最好。条条大路通罗马,该备忘单可能不是解决问题的唯一方法。该备忘单仅希望为你提供基于已知因素可以使用哪些算法的指导。
机器学习算法的类型
来源:zhihu
1. 监督学习
监督学习算法即对操作的直接监督。我们使用数据来教导或训练机器,这意味着数据被标记了正确的答案。使用一种算法来分析训练数据并获得输入与输出映射的功能。然后,可以根据训练数据进行概括,使用该函数来预测未知输入的输出。监督学习基本上用于以下两种类型的问题。
- 分类:在分类问题中,你需要找到输入数据的类别。例如,将图像分类为“狗”或“猫”。
- 回归:在回归问题中,输出为实数值。请尝试根据输入来预测变量的值。
2. 半监督学习
监督学习需要使用已标记的数据,如果其他人没有从事类似项目,则要查找或生成这些数据可能会很困难。在半监督方法中,我们将某些标记数据与未标记数据一起使用。
如你所见,数据没有完全标记,这就是将其称为半监督学习的原因。通过将标记数据与未标记数据结合使用,可以提高模型的准确性。
3. 无监督学习
无监督学习应用于未标记的数据。机器必须在没有任何监督的情况下找出数据中的模式、异同之处,执行聚类并减少维数。
- 集群:根据一些标准和相似性,数据被分组为一个或多个集群。例如,根据客户的购买行为对其进行分组。
- 降维:某些数据的特征或维度可能并不用于模型训练。使用某些算法,我们可以避免考虑维度和不相关的特征。此过程称为降维。
4. 强化学习
强化学习能够根据环境的反馈来优化代理。当机器做出正确的决定并对其错误的决定进行惩罚时,代理商会对其给予奖励。这项学习不需要我们事先收集数据再清理数据。该系统可自我维持,尝试在现实世界中自我完善。基于强化学习的计算机程序AlphaGO击败了世界上最厉害的围棋选手。
尾注
来源:Pexels
机器学习问题可以通过多种方式解决,你可以根据多种因素选择算法,例如准确性、客观性、数据大小和数据性质。你也可以参考备忘单,并快速开始构建模型。一旦解决了问题并获得了结果,就可以进一步探索不同的算法,以找出最适合该特定问题的最佳算法。