本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
机器学习的优化步骤,目前都是一阶方法主导。
无论是SGD还是Adam,此类优化算法在都是计算损失函数的一阶导数——梯度,然后按照某种规定的方式让权重随梯度下滑方向迭代。
其实二阶梯度会有更好的特性,因为它是计算梯度的导数,能够更快地找到最合适的下降方向和速度。
然而出于计算量和存储成本的考虑,二阶优化算法很少用到。
最近,谷歌大脑提出了一种新的二阶预处理方法,带来很大改进,优于SGD、Adam和AdaGrad等一阶算法,缩短了神经网络的训练时间。
它在Transformer训练任务中比任何一阶方法都快得多,而且能达到相同甚至更高的精度。连Jeff Dean也不禁在Twitter上点赞。

“洗发水”算法
这篇文章是对之前一种二阶方法洗发水算法(Shampoo algorithm)做的实用化改进。
为何叫“洗发水算法”?其实是对此类算法的一种幽默称呼。洗发水的广告词一般是“搓揉、冲洗、重复”,表示简单重复式的无限循环,最后导致洗发水用尽(out of bottle)。
而这种算法用于机器学习优化,最早来自于本文通讯作者Yoram Singer在2018年被ICML收录的一篇文章Shampoo: Preconditioned Stochastic Tensor Optimization。
洗发水算法需要跟踪2个预条件算子(Preconditioner)的统计数值Lt和Rt。
然后计算这2个预条件算子的四次根再求逆。将这两个矩阵分别左乘和右乘梯度向量,迭代出t+1步的梯度再由以下公式得出:

上述过程像不像一种简单重复,所以被作者自称为“洗发水”。
2018年的那篇论文更侧重于理论解释,然而就是如此简单的“洗头”步骤实际应用起来也会面临诸多困难。
这一步中最大的计算量来自于Lt-1/4和Rt-1/4。计算这个两个数需要用到代价高昂的奇异值分解。
实际上,四次逆根不仅可以用SVD方法算出,也可以用舒尔-牛顿法(Schur-Newton algorithm)算出,而且随着矩阵维度的增大,后者节约的时间越来越可观。
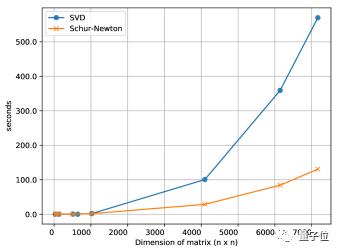
舒尔-牛顿法可以在普通CPU上计算,不必消耗GPU、TPU这类神经网络加速器的计算资源。
但即使是这样,计算矩阵根的逆仍然相当耗时。如果不解决这个问题,训练速度就不可能提高。
所以作者使用了异步计算的方法,并使用了TensorFlow中的Lingvo来对训练循环进行改进。
CPU负责收集和处理训练数据以及辅助活动,例如检查点和训练状态摘要。而在GPU、TPU等加速器运行训练循环时通常处于空闲或低利用率状态,并自动提供双精度计算。
这使它们成为计算预条件算子的理想选择,而不会增加训练消耗的资源。
使用异步计算
他们在每一步中都计算所有张量的预条件算子,但是预处理后的梯度却是每N步计算一次,并交由CPU处理。
这期间,GPU或TPU依然在计算,过去的预条件算子在训练过程中会一直使用,直到获得更新后的预训练算子为止。

计算过程像流水线一样,并且异步运行而不会阻塞训练循环。结果是,洗发水算法中最难计算的步骤几乎没有增加总的训练时间。
仅有这些还不够,作者对洗发水算法又做了几点改进,使它可以适应大型模型的训练。包括解耦步长大小和方向、预处理大型张量还有将大型张量划分成多个块。
最高提速67%
在WMT’14英语到法语翻译的Transformer训练任务中,该算法实现了1.67倍的加速,将时间减少了40%。
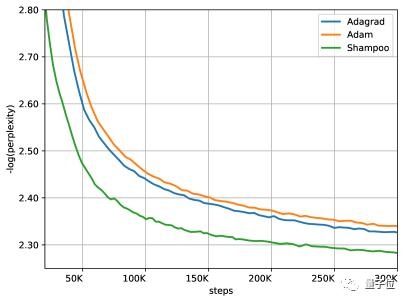
洗发水算法在和Adam或AdaGrad精度相同的情况下,只需后两者实现了约一半的相同的精度AdaGrad或亚当许多步骤,而且对学习率的宽容度比AdaGrad高。
之前异步计算中的N是一个可调参数,决定了训练的计算量,N越大,计算量越小。当然N也会对结果造成影响。我们需要在训练过程的性能和结果的质量之间做出权衡。
实验表明,这种方法可以承受多达1200个步骤的延迟,而不会造成任何明显的质量损失。
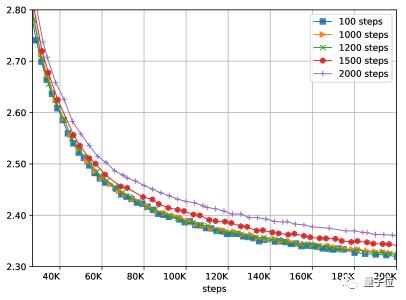
洗发水也可以用在图像分类任务中。
作者还在ImageNet-2012数据集上训练了ResNet-50模型,结果比带动量的SGD收敛更快,但是训练损失与SGD相近,但是在测试集上的效果不如后者。
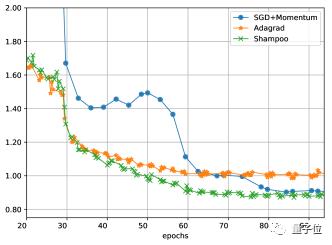
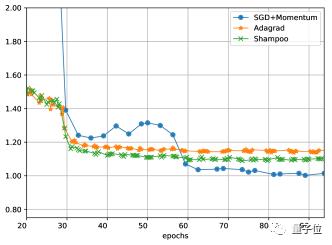
至于在泛化能力上的劣势,洗发水算法还有待进一步的改进。
论文地址:
https://arxiv.org/abs/2002.09018
https://arxiv.org/abs/1802.09568