前言
我知道大家都很熟悉hashmap,并且有事没事都会new一个,但是hashmap的一些特性大家都是看了忘,忘了再记,今天这个例子可以帮助大家很好的记住。
场景
用户提交一张试卷答案到服务端,post报文可精简为
- [{"question_id":"100001","answer":"A"},
- {"question_id":"100002","answer":"A"},
- {"question_id":"100003","answer":"A"},
- {"question_id":"100004","answer":"A"}]
提交地址采用restful风格
- http://localhost:8080/exam/{试卷id}/answer
那么如何比对客户端传过来的题目就是这张试卷里的呢,假设用户伪造了试卷怎么办?
正常解决思路
- 得到试卷所有题目id的list
- 2层for循环比对题号和答案
- 判定分数
大概代码如下
- //读取post题目
- for (MexamTestpaperQuestion mexamTestpaperQuestion : mexamTestpaperQuestions) {
- //通过考试试卷读取题目选项对象
- MexamQuestionOption questionOption = mexamQuestionDao.findById(mexamTestpaperQuestion.getQuestionId());
- map1.put("questionid", mexamTestpaperQuestion.getQuestionId());
- map1.put("answer", mexamQuestionDao.findById(mexamTestpaperQuestion.getQuestionId()).getAnswer());
- questionAnswerList.add(map1);
- //将每题分add到一个List
- }
- //遍历试卷内所有题目
- for (Map<String, Object> stringObjectMap : list) {
- //生成每题结果对象
- mexamAnswerInfo = new MexamAnswerInfo();
- mexamAnswerInfo.setAnswerId(answerId);
- mexamAnswerInfo.setId(id);
- mexamAnswerInfo.setQuestionId(questionid);
- mexamAnswerInfo.setResult(anwser);
- for (Map<String, Object> objectMap : questionAnswerList) {
- if (objectMap.get("questionid").equals(questionid)) {
- //比较答案
- if (anwser.equals(objectMap.get("answer"))) {
- totalScore += questionOption.getScore();
- mexamAnswerInfo.setIsfalse(true);
- } else {
- mexamAnswerInfo.setIsfalse(false);
- }
- }
- }
- mexamAnswerInfoDao.addEntity(mexamAnswerInfo);
- }
使用普通的2层for循环解决了这个问题,一层是数据库里的题目,一层是用户提交的题目,这时候bug就会暴露出来,假设用户伪造了1万道题目或更多,服务端运算量将增大很多。聊聊 HashMap 和 TreeMap 的内部结构
利用hashmap来解决
首先,看看它的定义
基于哈希表的 Map 接口的实现。此实现提供所有可选的映射操作,并允许使用 null 值和 null 键。(除了不同步和允许使用 null 之外,HashMap 类与 Hashtable 大致相同。)此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
主要看HashMap k-v均支持空值,我们何不将用户提交了答案add到一个HashMap里,其中题目id作为key,答案作为value,而且HashMap的key支持以字母开头。
我们只需要for循环试卷所有题目,然后通过这个map.put("题目id")就能得到答案,然后比较答案即可,因为HashMap的key是基于hashcode的形式存储的,所以在程序中该方案效率很高。
思路:
- 将提交答案以questionid为key,answer为value加入一个hashmap
- for循环实体列表,直接比对答案
- 判分
代码如下:
- //拿到用户提交的数据
- Map<String, String> resultMap = new HashMap<>();
- JSONArray questions = JSON.parseArray(params.get("questions").toString());
- for (int size = questions.size(); size > 0; size--) {
- JSONObject question = (JSONObject) questions.get(size - 1);
- resultMap.put(question.getString("questionid"), question.getString("answer"));
- }
- //拿到试卷下的所有试题
- List<MexamTestpaperQuestion> mexamTestpaperQuestions = mexamTestpaperQuestionDao.findBy(map);
- int totalScore = 0;
- for (MexamTestpaperQuestion mexamTestpaperQuestion : mexamTestpaperQuestions) {
- MexamQuestionOption questionOption = mexamQuestionDao.findById(mexamTestpaperQuestion.getQuestionId());
- MexamAnswerInfo mexamAnswerInfo = new MexamAnswerInfo();
- mexamAnswerInfo.setAnswerId(answerId);
- mexamAnswerInfo.setId(id);
- mexamAnswerInfo.setQuestionId(questionOption.getId());
- mexamAnswerInfo.setResult(resultMap.get(questionOption.getId()));
- //拿到试卷的id作为resultMap的key去查,能查到就有这个题目,然后比对answer,进行存储
- if (questionOption.getAnswer().equals(resultMap.get(questionOption.getId()))) {
- mexamAnswerInfo.setIsfalse(true);
- totalScore += questionOption.getScore();
- } else {
- mexamAnswerInfo.setIsfalse(false);
- }
- mexamAnswerInfoDao.addEntity(mexamAnswerInfo);
- }
分析HashMap
先看看文档

大概翻译为如下几点
- 实现Map ,可克隆,可序列化
- 基于哈希表的Map接口实现。
- 此实现提供所有可选的映射操作,并允许 空值和空键。(HashMap 类大致相当于Hashtable,除非它是不同步的,并且允许null)。这个类不能保证Map的顺序; 特别是不能保证订单在一段时间内保持不变。
- 这个实现为基本操作(get和put)提供了恒定时间的性能,假设散列函数在这些存储桶之间正确分散元素。集合视图的迭代需要与HashMap实例的“容量” (桶数)及其大小(键值映射数)成正比 。因此,如果迭代性能很重要,不要将初始容量设置得太高(或负载因子太低)是非常重要的。
- HashMap的一个实例有两个影响其性能的参数:初始容量和负载因子。容量是在哈希表中桶的数量,和初始容量是简单地在创建哈希表中的时间的能力。该 负载系数是的哈希表是如何充分允许获得之前它的容量自动增加的措施。当在散列表中的条目的数量超过了负载因数和电流容量的乘积,哈希表被重新散列(即,内部数据结构被重建),使得哈希表具有桶的大约两倍。
那么put逻辑是怎么样的呢?
HashMap的key在put时,并不需要挨个使用equals比较,那样时间复杂度O(n),也就说HashMap内有多少元素就需要循环多少次。
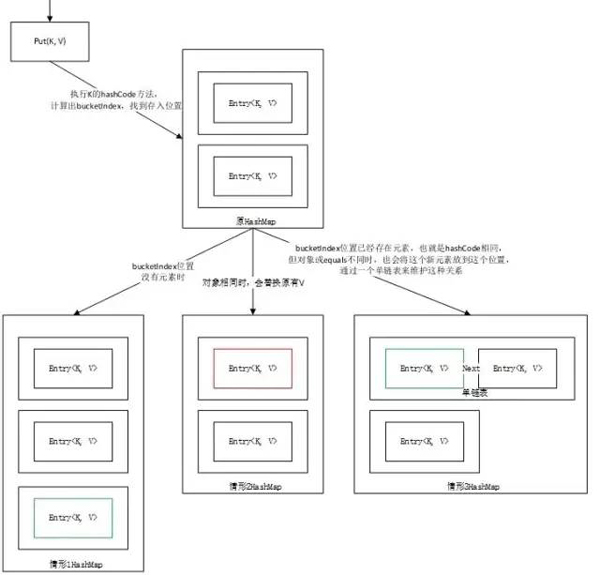
而HashMap是将key转为hashcode,关于hashcode的确可能存在多个string相同的hashcode,但是最终HashMap还会比较一次bucketIndex。bucketIndex是HashMap存储k-v的位置,时间复杂度只有O(1)。
图解
源码
- /**
- * Associates the specified value with the specified key in this map.
- * If the map previously contained a mapping for the key, the old
- * value is replaced.
- *
- * @param key key with which the specified value is to be associated
- * @param value value to be associated with the specified key
- * @return the previous value associated with <tt>key</tt>, or
- * <tt>null</tt> if there was no mapping for <tt>key</tt>.
- * (A <tt>null</tt> return can also indicate that the map
- * previously associated <tt>null</tt> with <tt>key</tt>.)
- */
- public V put(K key, V value) {
- // 以key的哈希码作为key
- return putVal(hash(key), key, value, false, true);
- }
- /**
- * Implements Map.put and related methods
- *
- * @param hash hash for key
- * @param key the key
- * @param value the value to put
- * @param onlyIfAbsent if true, don't change existing value
- * @param evict if false, the table is in creation mode.
- * @return previous value, or null if none
- */
- final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
- boolean evict) {
- Node<K,V>[] tab; Node<K,V> p; int n, i;
- // 处理key为null,HashMap允许key和value为null
- if ((tab = table) == null || (n = tab.length) == 0)
- n = (tab = resize()).length;
- if ((p = tab[i = (n - 1) & hash]) == null)
- tab[i] = newNode(hash, key, value, null);
- else {
- Node<K,V> e; K k;
- if (p.hash == hash &&
- ((k = p.key) == key || (key != null && key.equals(k))))
- e = p;
- else if (p instanceof TreeNode)
- //以树形结构存储
- e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
- else {
- //以链表形式存储
- for (int binCount = 0; ; ++binCount) {
- if ((e = p.next) == null) {
- p.next = newNode(hash, key, value, null);
- if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
- treeifyBin(tab, hash);
- break;
- }
- if (e.hash == hash &&
- ((k = e.key) == key || (key != null && key.equals(k))))
- break;
- p = e;
- }
- }
- //如果是key已存在则修改旧值,并返回旧值
- if (e != null) { // existing mapping for key
- V oldValue = e.value;
- if (!onlyIfAbsent || oldValue == null)
- e.value = value;
- afterNodeAccess(e);
- return oldValue;
- }
- }
- ++modCount;
- if (++size > threshold)
- resize();
- //如果key不存在,则执行插入操作,返回null。
- afterNodeInsertion(evict);
- return null;
- }
put方法分两种情况:bucket是以链表形式存储的还是以树形结构存储的。如果是key已存在则修改旧值,并返回旧值。如果key不存在,则执行插入操作,返回null。put操作,当发生碰撞时,如果是使用链表处理冲突,则执行的尾插法。
put操作的大概流程:
- 通过hash值得到所在bucket的下标,如果为null,表示没有发生碰撞,则直接put
- 如果发生了碰撞,则解决发生碰撞的实现方式:链表还是树。
- 如果能够找到该key的结点,则执行更新操作。
- 如果没有找到该key的结点,则执行插入操作,需要对modCount++。
- 在执行插入操作之后,如果size超过了threshold,这要扩容执行resize()。