话不多说,直接本主题!

如何于海量的互联网网站中获取有用资源信息,对网站的进一步优化有重要作用。为了提高网站资源获取的准确性及效率,本文提出一种基于Python的本地网站自动化爬虫程序设计,采用搜索查询工信部网站备案号呈现全量甘肃本地网站的方案,实现内容爬取高效及全面。最后针对甘肃移动资源进行网站优化,提高本地网站质量。
Python网站爬虫原理
基于Python网站爬取工具[2]包含网站爬取、网站分析、数据存储共3个模块,如图1所示。
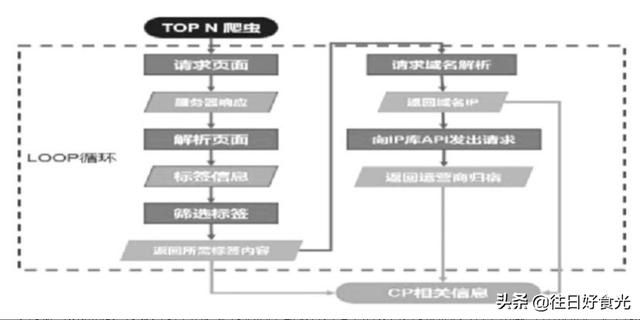
网站爬虫程序流程
1.1 网站爬虫方案
网站爬虫系统通过搜索网站中的超链接信息不断获得网络上的其它网站信息,并自动筛选有用信息[。因此首先需要确定如何获取网站信息,本文提出4种网站爬虫方案。
1.1.1 DNS查询方案
通过DNS系统访问日志获取。优点:网内最准确数据来源;缺点:本地网站排名DNS解析次数TOP十万以后。
1.1.2 CP流量排名查询方案
通过亚马逊免费网站访问量查询。优点:按网站浏览量显示,排名变化趋势数据可查询;缺点:数据不全,以大型CP为主,本地网站无法统计。
1.1.3 搜索引擎排名查询方案
通过百度、搜狗等搜索引擎查询。优点:全网网站收录较全;缺点:存在CP付费排名优先的风险,本地民生网站排名靠后。
1.1.4 工信部网站备案号查询方案
通过工信部网站备案号查询。优点:所有网站信息均通过工信部备案,全网数据最全;缺点:部分网站可能本省DNS无解析数据。
通过分析四种方案的优缺点,本文选用基于工信部网站备案号查询方案。
1.2 网站爬虫流程
1.2.1 构造网站
- url_base=″http://icp.chinaz.com/陇ICP备″+year_get+num+″号″
URL不同网站备案号不同,需通过程序构造备案号完成遍历。
1.2.2 获取HTML信息

查看网页源代码,详细处理涉及正则匹配等。
1.2.3提取网站域名

关联提取网站全量有用信息。
1.2.4 DNS解析网站IP
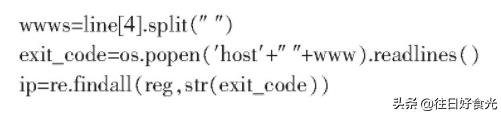
调用甘肃移动公网DNS地址,实现批量DNS解析。
1.2.5获取IP地址归属
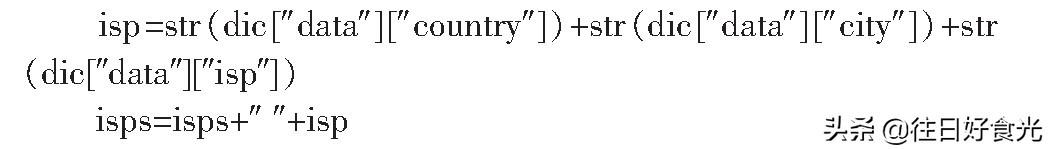
通过阿里API返回IP地址信息的json串,获取IP地址归属。
1.2.6呈现网站信息

通过EXCEL导出全量网站信息。