模型未动,数据先行,有标注的大量数据是AI落地一直以来的重中之重。如何快速高效率的获取训练数据成了AI实战中面临的巨大困难。采用3D图形技术合成训练数据是近年来计算机视觉新兴的一个方向。通过对实物建立3D模型,然后使用照片级渲染技术渲染合成海量训练图像,这样拿到的图像具有完美的标签,而且数据生成的边际成本很低,因此获得了工业界的重点关注。本文就来讲讲来自支付宝多媒体技术部的同学们是如何将这一技术应用到视觉零售这一领域的。
本文作者:支付宝多媒体技术部。
前言
支付宝视觉售货柜项目是蚂蚁IOT的重要产品,用户通过人脸识别打开货柜门,挑选出想要购买的商品后关门,视觉识别算法通过对比开门前后的商品变化判断出用户购买了哪些商品,自动完成结算。“开门即取,关门即走”的体验给用户带来了极大方便。

图1:3D合成的百岁山矿泉水

图2:支付宝视觉售货柜
在本场景中,由于货品的高密度摆放,视觉货柜所拍摄的图像中商品之间遮挡非常严重,算法需要根据非常有限的图像片段判断是哪个商品。同时算法需要不断迭代以支撑源源不断的上新需求。这就需要我们不仅要采集足够多的数据以解决各种情况,而且要能在很短的时间内及时输出新品的训练数据,否则算法模型的泛化能力将大打折扣。3D合成数据技术为该项目提升了3倍以上的上新速度,降低了70%以上的成本,大大缩短了商品上新周期。同时避免了人工打标带来的质量不稳定,保障了训练数据的高质量,将因人工标注数据不可靠造成的风险降低了90%以上。图3是这个方案的流程图。Part1对商品建模,并赋予精确的纹理和材质,Part2对场景进行参数化建模仿真模拟各种各样可能出现的情况,Part3对场景的每个情况进行渲染获取最终训练数据。
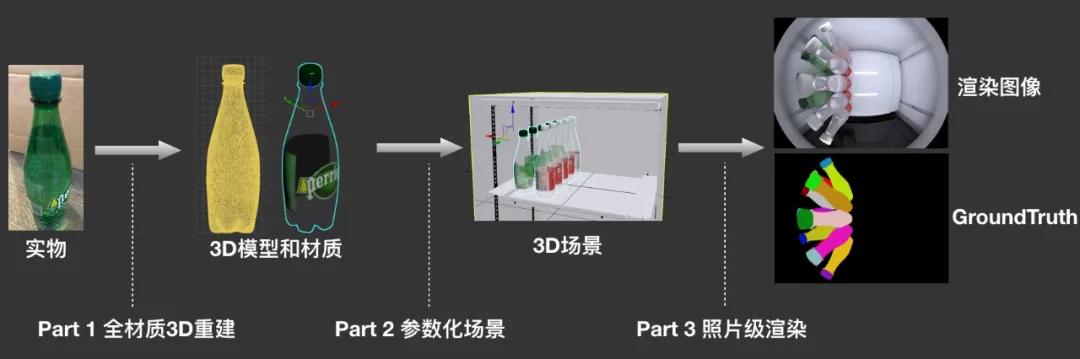
图3:3D数据合成流程
Part 1 全材质3D重建
3D重建是利用技术手段对某个物体进行自动几何重建,以及纹理与材质的建模。这个过程有别于3D建模师手K的过程,可快速准确的恢复某个物体的真实几何和外观信息。3D重建需要重建的信息包括几何和外观两个部分。当前3D重建难以解决的物体是一些反光、透明等材质,尤其是各种材质杂糅在一起的物体。这个难题横旦在项目的初期,是无论后面走哪条技术路线都需要攻克的难题。
项目组经过艰苦技术攻关自研了一套全材质3D建模方案,该方案结合了结构光扫描技术与基于图像特征匹配的多目几何重建技术,通过扫描和3D特征匹配的方法实现了全材质物体的3D重建,攻克了业界难题。使用全材质3D重建技术方案可在5-10分钟左右的时间精确重建一个商品的完整几何信息以及初步的外观信息。下面是若干个3D重建示例。

图4:重建的3D模型
在获得3D几何信息和初步外观信息之后,可根据实际商品的外观对3D模型不同部位赋予准确材质模型,这个过程称之为材质重建。一般来讲特定应用场景的商品材质种类是相对有限的,可根据不同业务场景建立一个特定材质库,根据3D模型的初步外观信息赋予相应的材质。实际上商品的外观与材质之间的专家经验是可以通过网络学习到的,一些研究工作如:开放环境材质估计、 形状与SV-BRDF估计 表明即便是在商品3D模型未知、采集环境开放的时候,我们仍然可以学习到材质模型与图像特征的对应关系。
Part2 参数化场景
我们通过全材质3D重建技术对场景进行建模,之后需要针对场景分布的各种可能性进行基于物理的模拟。在参数化场景部分,我们也需要对场景进行3D建模。场景的建模是对所渲染3D模型所处的环境进行3D建模,包括了场景3D重建和光源建模两个部分。场景3D重建的过程可以是自动化的使用如扫描仪,或者根据多目几何原理使用Structure-from-Motion进行三维重建。而光源重建则是对环境的光源进行建模,使得渲染出来的图像与实际拍摄的图像在外观上融合度较好。
光照估计
在渲染流程中,光照对渲染结果的影响至关重要,因此场景参数化需要对光照进行精确的描述。通常来讲,一个场景中的光源往往构成复杂,需要对直接光源的数量、色温、光源形状、乃至频谱范围等进行准确建模,如果场景中有类似液晶显示屏等光源,还需要针对光源的偏振态和频率进行建模,工作量很大且很难自动化。

图5:HDR合成与渲染结果
这里我们采用了HDRI技术对光源进行重建,该方案是一个简单有效的光源重建和渲染技术,被广泛采用于电影制作中实现与真实场景融合度很高的渲染图像。该技术是一种基于图像的渲染技术,即采集并合成一张高动态范围图像作为光源进行渲染。可以看到这样的光源渲染出来的结果在高光表现方面较好。
场景建模和物理碰撞检测引擎
在视觉货柜项目中,我们所面料的场景是一个采用视觉识别技术完成商品交易的无人货柜。货柜需要频繁上新品,且商品之间遮挡严重。商家为了更有效的利用货柜会密集摆放很多商品,很多商品漏出来的画面非常有限,而视觉识别需要检测并识别出所有目标。这就要求视觉算法同学除了想法设法提高模型泛化能力之外,也需要准备充分多样性的数据,尽可能全的覆盖到各种遮挡关系,同时需要覆盖到每个可能出现的商品。
在参数化场景的过程中,我们使用重力模型、随机力模型等对场景施加变化,并对场景中的各个物体进行碰撞检测和模拟,使得场景中的物体分布接近真实状态。下面这个视频示意如何对倒瓶等异常情况进行仿真模拟。

图6:物理碰撞模拟
Part3 照片级渲染
3D合成数据方案的核心问题是怎样使得渲染出来的图像看起来像照片,而不是人眼看上去很真实就够了。我们需要渲染域与实拍域尽量接近才能真正起到训练数据的作用。一般意义上的渲染场景存在所谓too perfect的问题,也就是说渲染出来的图像看上去可能已经非常真实,与人眼实际看到的样子很接近,但却与摄像头实际拍摄的图片不同。作为喂给机器学习模型的训练数据,我们要求最终输出的图片需要复现这些瑕疵,实现所谓的照片级渲染(Photo-realistic rendering)。
我们尝试了两种思路实现照片级渲染。一种思路是数据驱动的方法,先采集大量实拍图,之后通过GAN、域迁移、域自适应等方法将渲染域的图像迁移至实拍域。另一种思路是成像模拟的方法,在渲染流程前中后期分别模拟各种摄像头成像的影响,比如渲染过程中根据场景深度不同模拟散焦模糊,对渲染图像卷积同一模糊算子实现因低分辨率引起的镜头模糊等。
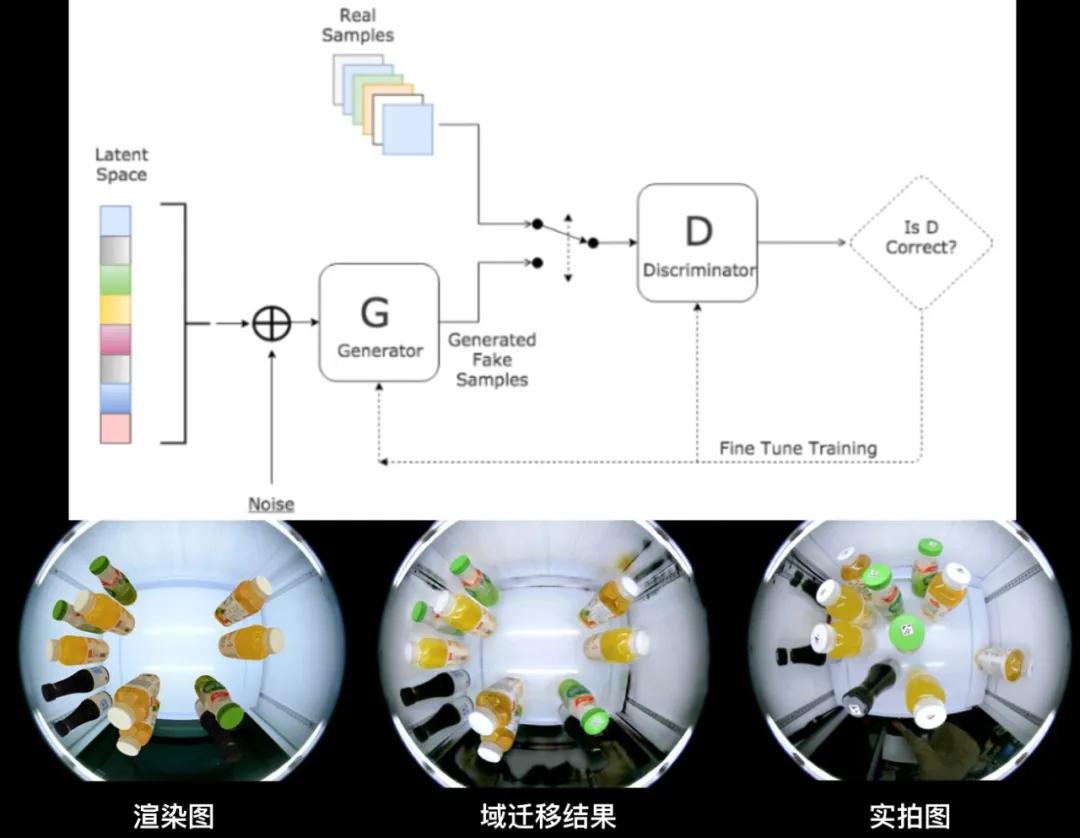
图7:渲染图、域迁移图与实拍图
图7为采用第一种思路实现的效果。将渲染图、迁移图和实拍图的对比,我们看到迁移图可以较好的实现与镜头相关的图像特征迁移效果,同时也会存在一些artifacts。此外,作为数据驱动的技术,域迁移的过程可控性较弱,获得好结果的前提是需要有与真实场景分布接近的实拍数据,导致数据采集成本较高。
不同于上面的数据驱动算法,成像模拟采用纯模拟的方式合成训练数据,可控性强,且效果无天花板,但实现的技术较为复杂。我们采用电影级渲染引擎,并自研了光学摄像头模拟器,实现了一系列因镜头、光电传感器、以及ISP图像处理单元的模拟,消除了许多引起渲染域与实拍域差距的因素。下图为成像模拟实现的效果。

图8:成像模拟结果
写在最后
在实践中,我们发现3D合成数据可以很好的解决许多计算机视觉任务,尤其是在一些无法很好获取ground truth的任务中具有非常好的落地前景。毕竟人工智能的目的是代替重复低效的人工,而如果用于训练的数据收集和标注仍然大量依赖人工的话,有时就不免落入到所谓“有多少人工就有多少智能“的尴尬境地。
同时我们也必须看到目前的3D合成数据方案有诸多挑战。首先,不能完全依赖合成数据,总会有一些模拟不到的场景。其次,合成数据方案比较适合标注成本高的任务,对于一些标注成本不高的任务反而会增加成本,比如人脸检测、物体识别分类等任务。再次,一些技术难点,如低成本实现动态场景模拟等尚需进一步攻克。