说明:本文为网易游戏监控团队负责人王维栋老师在 GOPS 2019 · 上海站的分享整理而成。
作者简介
王维栋,网易游戏监控团队负责人
我跟大家介绍一下我们是如何在游戏领域做到千亿级的监控体系,还有我们在智能监控方面的一些探索。
我是网易游戏监控团队的负责人,7年时间一直在做运维平台相关的开发工作,擅⻓的领域是智能监控以及应用性能调优。
我会分为四个章节说。

首先就是游戏领域的监控会有什么区别,全球布局游戏监控又有什么样的挑战?面对海量的时间序列时我们是如何处理;第三部分说说在可视化和报警方面做的比较有亮点的地方,最后讲一讲我们在智能监控方面的实践。
1. 来自全球布局的游戏的监控挑战
首先说说传统游戏架构是什么样的,以前游戏架构大多都是单体架构,单服单机器。另外基础设施比较单一,之前基本都是物理机。
另外,以前基本就是瞄准国内市场做事情。最后,监控的层次也非常简单,无非就是硬件、网络、操作系统、进程和业务指标。

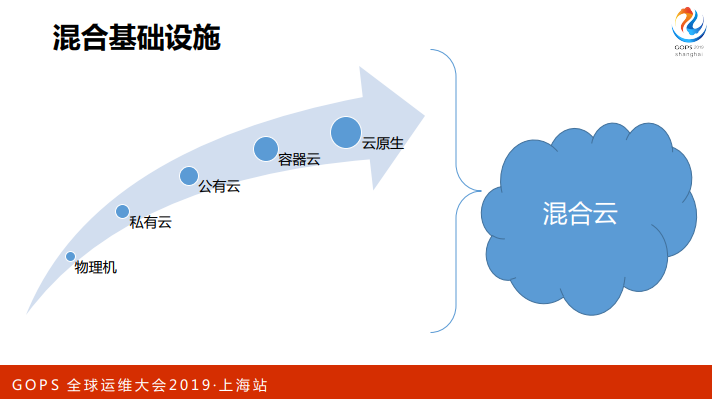
但现阶段,我们面临的监控场景变化的太快了,游戏的架构多样化,混合基础设施在我们公司逐渐出现。此外,公司开始立足海外,在海外有非常好的增⻓。最后,传统监控也逐渐向可观测性去扩展。

首先是游戏架构的变迁,从最开始的单机架构,扩展到分布式架构。也就是说,玩家看到一个游戏服,在后面会有十几台机器,有的甚至多达百台机器,取决于玩法不同。
后来,很多游戏的开发接触到微服务的概念,开始逐渐的把游戏里面比如大厅、聊天服务从游戏的核心逻辑里面独立出来,变成微服务,对游戏服务提供支持。这种情况下,微服务场景开始逐渐在游戏场景里面出现。
第二方面,我们一直在做游戏上云,一开始在物理机器部署游戏服,后来做私有云,在虚拟机上部署。在出海的过程中也开始逐渐采购海外的公有云和第三方 IDC 的机器。
再后来我们开始做容器化,在容器化进行到一定程度,现在有一些游戏也开始尝试云原生。但是我们这个过程不是一蹴而就的,毕竟体量比较大,而且一个公司可能会有几百个游戏,在这种场景下就会出现一个混合云的状态,有些游戏还是物理部署的,有些游戏已经云原生了,这种情况下挑战是非常大的。
另一方面,我们公司目前的游戏业务已经覆盖到全球数十个国家,监控也会有二三十个region 去覆盖到全球的游戏服务;此外,我们会在海外采购多个云服务商,这种情况下监控的挑战也会增加。
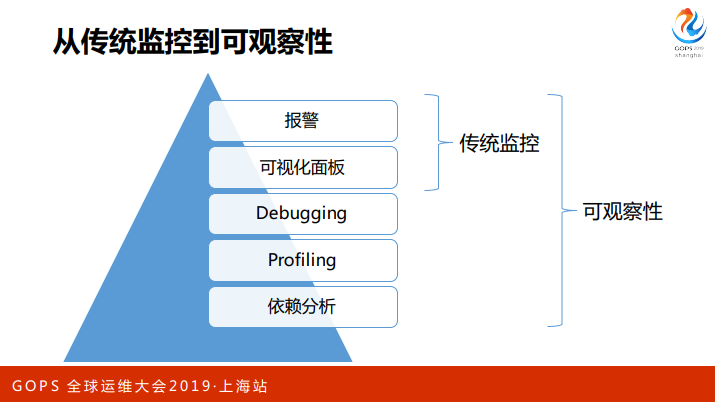
从传统监控向可观测性过渡的过程中,我们不仅有报警、可视化,还有 debugging、profiling。尽力让系统更加透明、可视化,从而形成更好的理解来优化我们的产品,做到更好的度量,形成一个良性闭环。
基于上面这些思路,我们目前的游戏监控架构是这样的,从下到上是监控数据从产生到处理再到消费的过程,然后右边会有一些控制层的东⻄,这张图只画出了最关键的一些点。
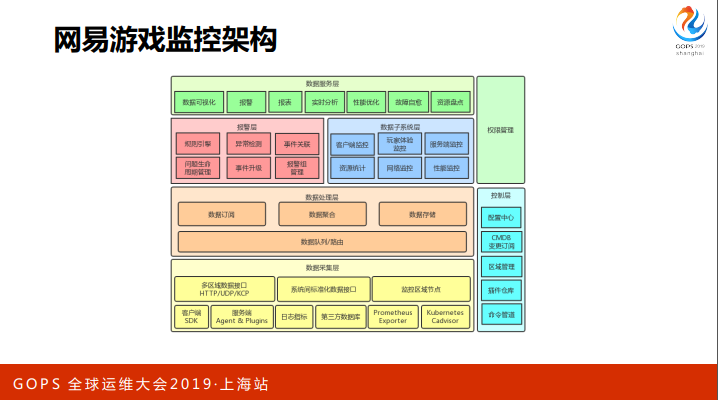
我们在采集层面会做很多数据入口,比如说有 SDK,agent,日志指标,还有第三方数据库。通过多区域部署的就近接入层,把这些数据接过来导到中央,中央会用一个 kafka 的数据队列做解耦和路由,支持多系统的数据订阅,此外还有聚合,数据存储。
在数据应用的迭代过程中,我们会有一些历史包袱,一开始是看业务场景来做监控的,所以就会出现一堆数据子系统,比如说有客户端监控,用户体验的监控,有服务端监控,有资源相关监控,有网络监控,还有性能优化的监控。
我们目前正在逐一整合,并且对外提供统一入口。报警层面是基于一个标准化的规则引擎做报警,现阶段我们也在逐渐把异常检测,事件关联这些功能加进去,此外还有像问题生命周期管理、事件升级来确保通知可达等机制。
最上层我们提供了一些数据可视化、报警通知、实时分析、性能优化等一系列的能力。控制层面,我们通过跟 CMDB 深度结合,订阅 CMDB 变更来减少监控的配置成本。
通过区域管理来做到全球化的监控。我们的 agent 能够支持到丰富的插件自定义功能,所以有一个插件仓库。
最后我们做了一个命令管道,其实就是类似于像 Ansible 的东⻄,跟我们的 agent 集成,最直接的价值就是配置的分发、故障自愈等功能都可以依托这样的基础架构来构建。
2. 海量时间序列数据处理
接下来说说我们面对海量时间序列的时候做的一些事情。首先就是面对海量而且异构的监控场景,我们做了监控对象的抽象,所有的监控概念都能够自定义地套进去抽象的数据模型。

通过与 CMDB 的结合,我们做到比较小的管理成本。采集方面,我们给出多种采集方式去适配不同的业务场景,然后做了统一的入口,在统一的数据总线做了数据的对⻬、预处理等工作。
最后我们做了一个大规模的海量时间序列存储。

首先来说监控对象抽象,为什么要做这件事情呢?常规场景中,我们会监控一个物理机、虚拟机、容器,再到一个进程。对于CPU、网卡等硬件,只要能标注它,就能把数据关联上去。
随着业务不断的扩展,在游戏场景里面要监控某个游戏场景, 要监控某一次 battle,某一个 NPC 的属性,游戏进程之间 RPC 的情况。这种场景下如果我们写死配置,适配一个个场景,对于监控人员来说维护成本很高。
所以我们做了一层抽象,跟业界比较流行的方案例如 OpenTSDB、Prometheus有共同之处。
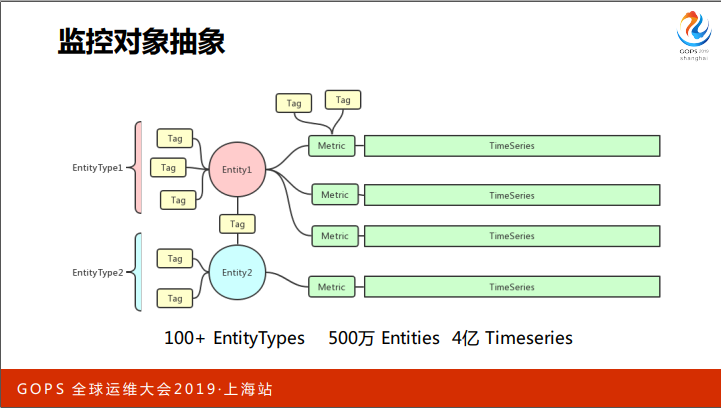
我们把监控对象抽象为 Entity,用 EntityType 描述它是属于什么类型的,用 tags 描述它的属性,同时 tags 也会有一个类似交叉表的用途,把 entity 关联在一起。目前我们大概有 100 多个 EntityTypes,差不多500万的 entity,4亿级别的 timeseries。
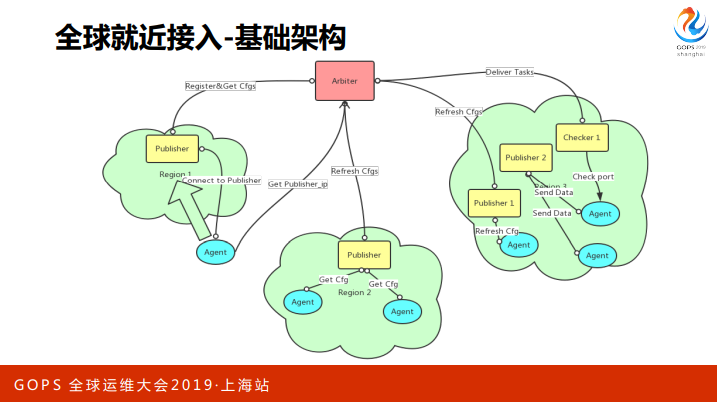
刚才讲到全球就近接入层,这是服务端监控的基础架构。最中间的红色是一个 Arbiter,它的⻆色是仲裁,负责订阅 CMDB 的变更,生成监控配置,监控配置就会被分发到每一个 region 里面,当 agent 入网的时候会先去询问 Arbiter,我是属于哪个region的?
然后 Arbiter 会告诉它所属的 region 和 node 列表,agent 尝试连接,成功就会入网,它会跟 node 保持一个⻓链接,把它产生的数据全部交给 Node 去中转。node 到中央我们会做网络优化,比 agent 直接连到中央会快很多。
另一方面,保持⻓连接有助于配置同步。配置变更时,Arbiter会通过Node和⻓链接,实时推送配置下去到 Agent。
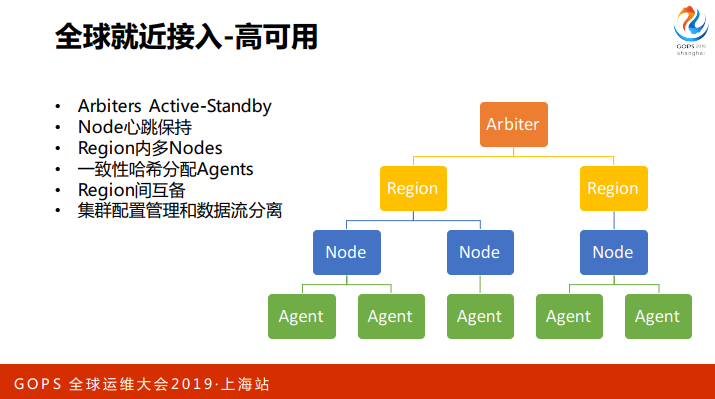
这一套架构有高可用的保障,首先 Arbiter 是单点,我们做了 Arbiters Active-Standby的模式,出问题的时候 Standby Arbiter 会接管主 Arbiters 的工作。
Arbiter 的逻辑基本都是幂等的,所以不会担心数据和集群一致性的问题。Node 会和 Arbiter 保持心跳,如果 Node 失联了,Arbiter 会把相关的 Agents 调度到其他的节点上去。此外,每个 region 里面会有多个 node 冗余,在 node 之间分配 agent 时,我们用了一致性哈希,去确保增删 node 时,尽量减少 agent 分配关系的抖动。
这套流程,配置管理部分和数据流部分是分离的,上层Arbiter和node完全失联的情况下,agent会跟node一直保持连接,直到接到新的配置。这种情况下,即使我们中央出现了故障,agent仍然会上报数据。
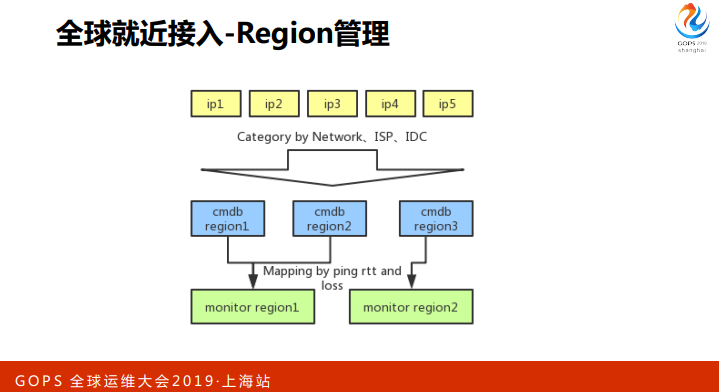
说一下我们的 region 是怎么划分的,首先我们会有一批机器和它们的IP,CMDB 会用 IDC、ISP 等一系列信息,把IP分类,分成 CMDB 的 region。
当一个新的 CMDB region 产生的时候,我们会拿到变更事件,根据地区、ISP 等几种条件判断可能跟哪个 monitor region 比较近,或者相关的网络质量比较好,然后在几个候选 regions 中选一些点,跟新的 region 发起互相探测的任务,得到 rtt and loss。
管理员可以看到 一个包含这些数据的可供决策的列表,只要去选一个 monitor region,新的cmdb region 就会自动加入到 monitor region。
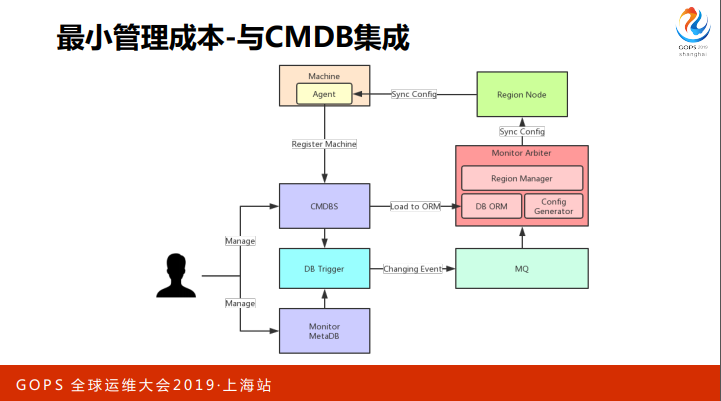
最小管理成本则是通过订阅 CMDBS 的变更实现的,我们的 SRE 通过各种管理系统和 CMDB,来管理一些资源和业务的对应关系。
Arbiter 对需要生成配置的数据,做一个内存的 ORM,同时在 CMDB 接一个 db trigger,把它所有增删改的事件打到 MQ, 在 arbiter 订阅,实时更新 ORM。
然后基于这个 ORM 做配置生成,这些配置生成完之后就会推到 region nodes,然后推到 agent 去,最初这个架构做完之后,我们可以实现秒级的配置更新,但是后续规模变的非常庞大,维持秒级配置更新使用的资源不划算,所以后续在这里面加了窗口,十秒或者一分钟内变更的事件,我们会统一分 发,尽量减少配置的抖动。
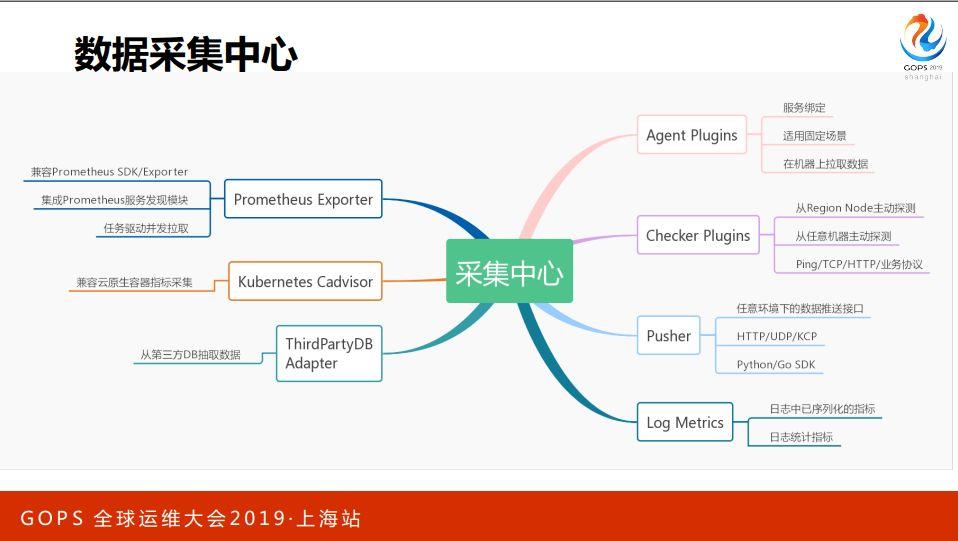
在数据采集方面,因为游戏面临的场景非常多,所以我们提供了多个采集方式。
首先就是 agent 插件,它通过服务绑定到机器,在机器上采集数据然后推出去。主动监控的 checker 插件也是类似的方案,我们提供各个 region 的探测点,做从外部发起的主动探测。此外也有一套框架,能让用户自己配置,从任意一台主机上发起探测。
主动监控支持 icmp/tcp/http 等一系列协议。此外,SRE 可以直接开发插件,覆盖到业务协议。
第三个方式是 pusher,我们提供一套 SDK 和 server 端,主要场景是由进程内向外 push 数据。游戏开发只要把 SDK 引入到自己的代码,调用几个接口,然后就可以 push 数据。目标就是能够实现任意环境下的数据push接口。
最后,游戏经常使用日志暴露一些统计指标,这种情况下我们也做了 log metric 的兼容,从实时日志流里过滤一些标准字段,把它直接导到监控数据流。
此外,公司也在尝试云原生的方案,所以我们也引入了 prometheus,我们集成了它的服务发现模块,然后直接对接 prometheus exporter 的协议,用一组分布式的 agent 去拉exporter 暴露出的数据,这样 k8s、etcd 等系统的监控就可以直接对接。
对于容器的监控,我们用插件封装了 cadvisor。为了兼容公司内其他的时间序列数据,我们提供了第三方 db 的 adapter,用来从其他的DB里面导数据。
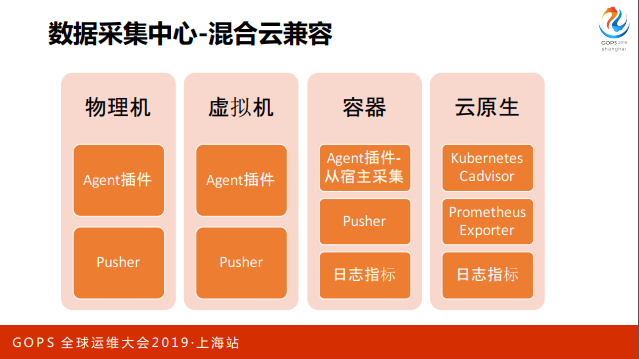
有了这些数据采集方式,我们就可以比较从容应对混合云下的监控场景。
对于物理机和虚拟机,跑 agent,SRE 按需编写和绑定插件;对于容器,我们比较倾向于用 pusher 或日志导出数据;对于比较固定的场景也支持从宿主直接 attach 到容器采集数据;云原生的场景使用 Cadvisor、Prometheus Exporter、日志指标等。
刚刚提到我们 agent 是插件化的框架,目前我们是用 Python 做这套 agent 的,所以对于 SRE 来说上手成本非常低。
SRE 想要开发一个插件,就可以在系统点一下,得到一个 Gitlab 的 repo,在代码框架里面填采集数据的代码,push 上去。
只要 push 到保护分支,就会自动打成一个pip包,然后丢到 pip 源上面去。接下来只需要服务绑定 插件,这些服务的机器就会get到这个配置,然后 agent 就会装这个插件去跑。
现阶段我们已经800多个Python插件,覆盖了绝大多数的业务场景。包括前面讲到 的多点探测、故障自愈相关功能都是通过插件支持的。
当数据收集上来之后,我们有一个统一总线做处理。首先所有数据都会进到一个 Kafka Origin Data Topics 里,然后 PreProcessor 做一些数据清洗,过滤非法数据。做数据对⻬,然后进入 MainFlow。
进到 MainFlow ,我们会有一个 Flink Aggregator 去负责做聚合,用户会在系统上配 一些可视化和报警规则,按这些规则延生成一些统一规范下的聚合规则,Flink 规则聚合数据,再把聚合好的数据丢回 MainFlow。
后面会有几个系统去订阅,首先是存储,然后周边系统会 Subscriber,然后是 Visualization Updater 会做自动的可视化方案生成,最后就是报警。
这里是一个存储的架构, Kafka 的 MainFlow 在存储这边对接了三个模块。首先是 存储架构,我们把 metadata 和时序数据分开了。Metadata 是描述 Metrics 的 Tags 以及跟 Entity关系的数据, 我们把它全部拆出来,生成 UUID,接下来存储的 时候拿这个 UUID 和 TimeSeries 存在一起。
Redis 的集群会缓存六个小时数据,会有一个模块每半个小时把数据 merge dump一 次,在 mongodb 这边分了几个粒度的库,有1分钟,有5分钟,有30分钟还有一天。Archive 模块每天跑一次,负责把 MongDB 中的数据归档到 hdfs。
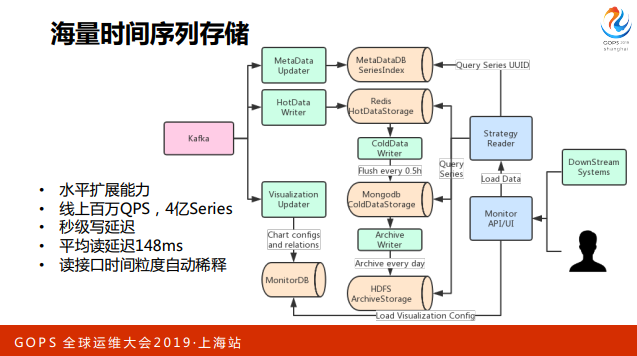
接下来第三个模块是 Visualization Updater,通过订阅数据,按数据的组织形式来 生成与数据相对应的可视化的配置。大部分情况下用户只要推数据,就可以在系统 中看到图表,接下来他想要定制细化、业务化的一些视图的时候,可以再拖拉这些图表。
用户或者第三方的下游平台会通过我们统一API和UI拉数据,拉数据的过程有一个策略读的模块,这个模块主要责任决定从哪里读数据,按用户的query索引到要取哪些 UUID的数据,然后接下来按用户的读取方式决定从哪个库取数据。
比如说要展示图表,然后取最近一小时的数据,就直接从 Redis 里面取一小时,如果取一天的数 据,我们就会做一次降级,因为一分钟的点会非常密,也是不利于观察,这时候我 们会直接把它降成5分钟的粒度,从 MongoDB 读。如果取更久的数据,我们就可能依次降级,做更友好的可视化。
3. 数据可视化和报警
说完存储,我们简单说一下可视化方面,比较通用的功能就不说了,重点说一下比较有意思的地方。之前提到我们对监控对象抽象了一层概念,有 EntityTypes、Entities、Tags。这种情况下可以实现任意组织架构的业务视图组装。
只需要选择你要看哪些 EntityTypes,这些 EntityTypes 之间的关系通过 Tags 描述,然后就可以构建出树形的组织架构,这个树形架构就可以直接关联到所有相关 Entities 的数据和图表。
这里有一个例子,最典型的机器视图,有 project,groups、machines,组成一个三层树形结构。
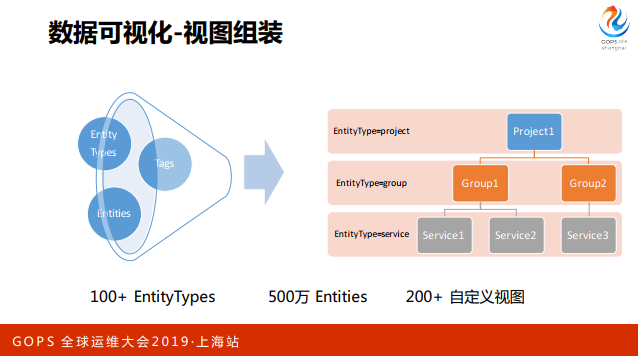
目前我们有 200 多个自定义视图,比如这个机器视图,这个用户使用的容器视图, K8S-Pod-Container的层级。

这里是监控后端的视图,把 Arbiter-Region-Node 这三个层级渲染上去了,然后最下面这一层看到的就是所有 Node 节点的信息。
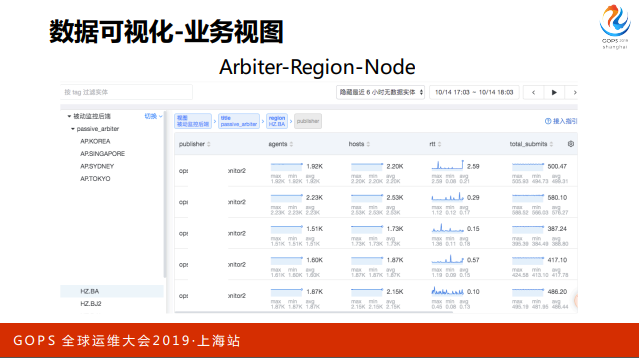
同时如果你想做聚合,不需要上报多次数据,比如这里只需要 Node 报自己的数据,根 据这个视图的组织关系配一个向上聚合的规则,然后前面那个聚合模块就会帮我们搞定所有聚合相关的事情。这时候其实你只要点到 Region 节点就可以看到所属 Nodes 总共加起来有多少数据。
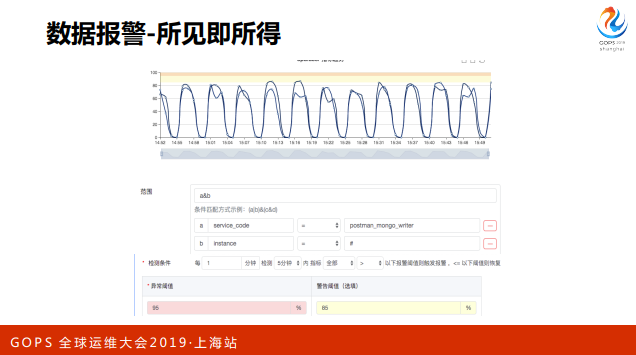
我们之前发现一个很典型的问题,报警这个东⻄很难调试。我们配了一个规则,但不知道这个规则是否能生效,所以需要造数据测试。基于这个痛点,我们迭代新系统的时候,所有的功能是基于所⻅即所得的原则去做的。
比如说这里用户给一些 tags,筛选出一批数据,这些数据就会直接呈现在图表,同时给出一些统计数据,比如说均值、percentile。输入阈值,就会在图表显示出来阈值和数据的相对关系,做报警模板调试的时候也是类似的,只要选一条已经存在的数据,就可以按这条数据直接按模版渲染报警出来。
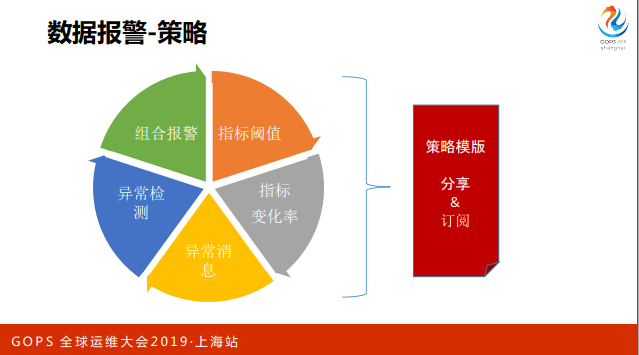
报警主要做了如下的策略,首先是指标阈值,然后是变化率,还有一些用户自定义的异常消息、异常检测,还有组合报警。
用户配完这些报警之后,可以用策略模板分享出来的。
我们会有几百个项目,有很多运维人员在维护,有些项目可能是同构或者说是类似架构的,这种情况报警策略很多都是相同的,我们可以用策略模板做分享和订阅,减少人工配置的成本。
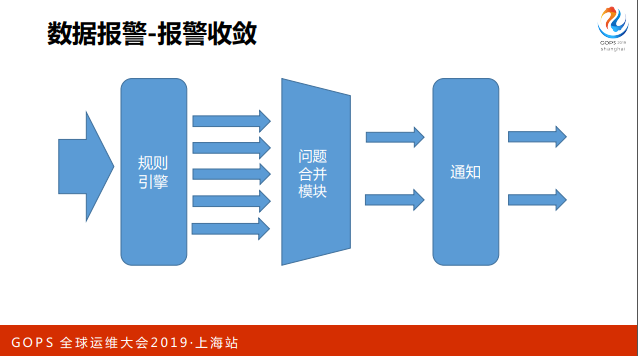
再简单说一下收敛方面做的事情,我们基于整体的规则引擎处理数据,产生问题, 后面有一些问题合并模块做合并,目的是尽可能减少报警。
在合并策略上做了一些人工策略,比如说我们可以选择做一个十秒钟的合并,相当于做了一定报警时效性,同时增加报警的准确性。另一方面我们也会根据项目、分类、策略等维度做报警合并。
除此之外,与CMDB关联可以做到更多合并策略,例如CMDB能够描述网 段和机器的关系,就可以做到网络层到机器层到的合并。
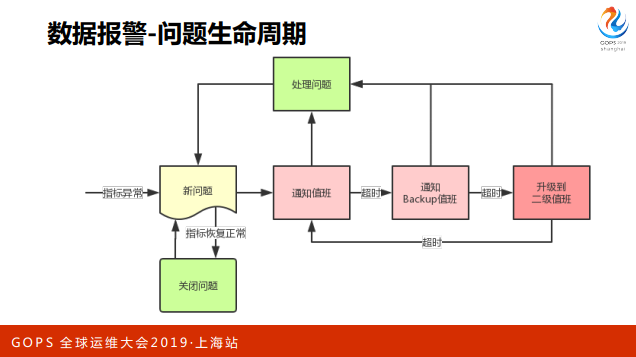
问题产生之后,我们做了一个策略确保问题会被及时处理。产生新问题之后,首先 通知值班,有各种方式,比如泡泡、邮件、电话、短信之类。
如果这个值班正好手机不在旁边,确认超时,就会通知到下一个backup值班,后面还有2级值班,3级值班,如果都没有通知到,再回来通知,这样一个方式确保了报警的可达性。
这个过程只要有任意一个人收到消息点击处理问题,报警就被抑制了。对于一些指标类的 报警,我们也做了一个指标恢复正常时自动关闭问题的逻辑。
4. 智能监控实践
说完报警相关的事情,再说一下我们再智能监控方面的一些尝试。
首先,传统的报警中,像阈值、同环比用的都比较多,能解决很多问题,还是有一些情况是没办法覆盖的。异常检测能做到很多事情,一方面能够按照数据的特征去找出异常点。另一方面能够增量学习,适配数据变化。
比如说,以前某个数据维持在一个基线上面,如果我们用阈值,有一天这个数据明显偏离了基线,然后又⻓期稳定下来的,就需要调阈值。而很多异常检测模型可以通过线上的增量学习更新模型适应变化。

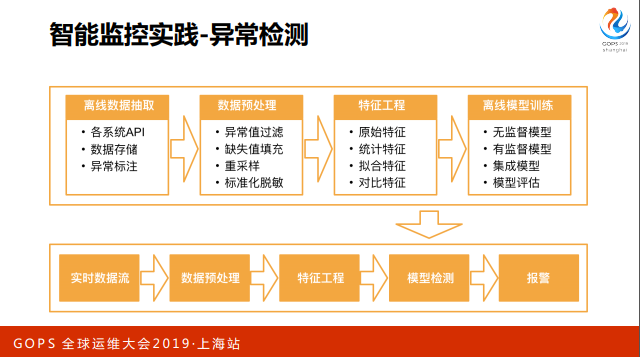
我们整体流程大概是这样的,首先是数据的抽取、存储还有标注,接下来做一系列的预处理,比如对于非对称的样本做重采样,一些标准化的脱敏等。我们在特征工程方面做了蛮多的努力,目前我们线上比较有价值的特征大概360多个。
接下来是模型训练的流程,我们线上已经有一些无监督和有监督的模型在跑,也做 了一些集成,同时这里会有一个模型实时评估反馈。模型训练完之后就会丢到S3的 存储上,有一套线上实时检测流,订阅模型的变更,拉取模型,订阅数据做检测和报警。
我们这边尝试过一些模型。
首先说说最传统的统计学基于距离、密度等的方法,这些方法有一个共同特点,使用特别简单,不需要标注,但是有一个问题就是效果随缘,它们在一些场景下表现的很好,另一些场景下,数据特点不同,表现的就很差。
第二个阶段我们尝试 IsolationForest ,这个算法是我们⻅过无监督算法里面最好的 一个,它的 Baseline 相当高,在大部分场景下能得到比较好的效果,基本上不用太多调试。但也有另外一个问题,上限一般,毕竟无监督,没有标注介入,事实上很难按你的意图区分很多细节情况,比有监督来说还是有差距。
最后还是走有监督的路子,一开始尝试了LSTM、DNN等模型,后续后是回归到比较基础的树模型,当然也有尝试做集成,目前集成模型效果会更好一些。
接下来我们发现一个问题,就是在更新样本集和特征的时候,会发现当我们想要满足一个场景,就有可能会对其他的场景造成误导。
比如说有一些业务的曲线本身抖动比较厉害,它需要对大幅度抖动进行报警,如果我们把这类样本直接导入样本集,就可能影响比较平滑的曲线检测。当然有人说我们可以对前面曲线做平滑,再进模型,但这样的话其实会降低抖动幅度比较厉害的曲线的峰值,也会影响到结果。
所以这种情况下我们就尝试做一个曲线分类,抽取一些曲线特征,比如说自相关系数,比如 说抖动幅度相关的特征,用这些特征来做一下数据分类,根据不同的分类来预训练 模型,尝试解决这个问题,这样在某一个场景下我们加入样本就不会影响到另外一个场景的模型。

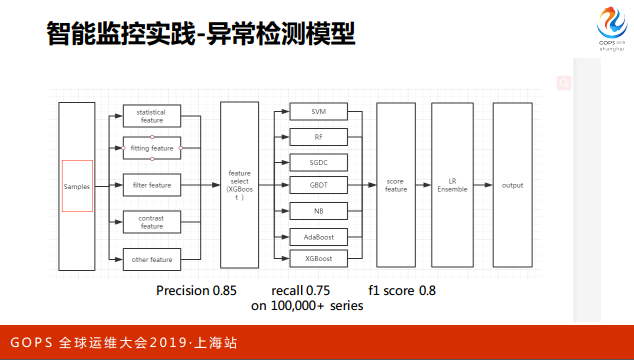
简单说一下我们的模型,预处理后有features展开,然后用xgb做了特征选择,然后 有SVM、RF、GBDT等一系列的弱模型,最后用LR做一个简单的ensemble。这套模 型在我们的十万条曲线上测试的结果大概是85%的precision,因为我们是重点对 precision做优化的,recall会稍低一些。
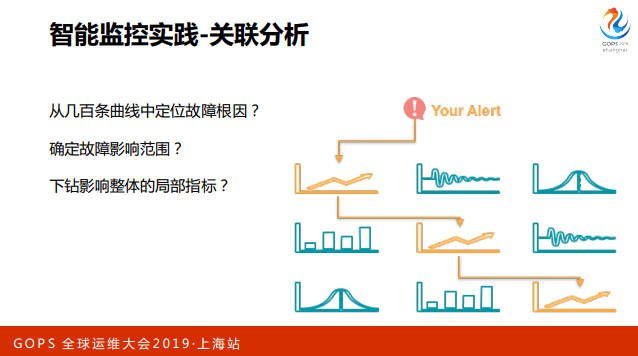
说完异常检测说说另一个话题,我们在尝试去寻找问题之间的关系,引入了关联分 析。这里的关联分析主要是指时间序列的关联分析,我们的目标是从几百条曲线中 定位出故障原因或者确定故障影响范围,或者确定影响整体指标的局部指标。
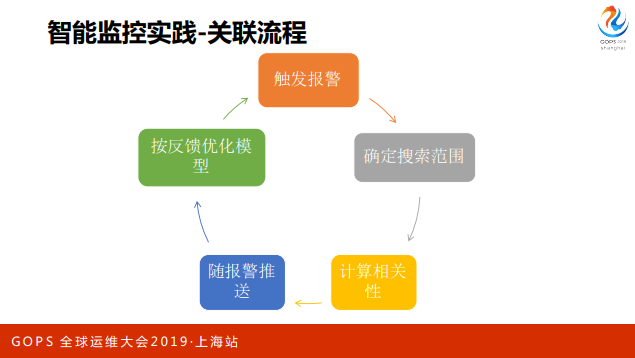
整体流程是:从报警触发,通过CMDB的业务配置和一些策略,确定要搜索哪些曲线,然后获取数据,跟当前发生报警这条曲线做相关性计算,最后按相关性排名, 推送用户,用户这时候也会有一些反馈,我们拿回来之后做相应优化。
这是一个简单的模型介绍,一开始我们尝试了一些曲线相似性计算的模型,一直没有取得很好的效果。
后来我们看到一篇论文,它的观点很有意思,不去搜索两个曲线之间的关系,只搜索一个事件和曲线之间的关系。
因为我们知道前面的曲线已经有问题,我们按这个时间节点,对需要搜索的曲线前后划分子序列,抽出两个子序列出来,再到这条曲线上随机取一个子序列,再对比这三个子序列之间是不是相同,如果前面的子序列和随机子序列不同,我们认为这个序列的变更导致这个事件,如果是随机子序列跟后面那个子序列不同,我们就认为是这个事件导致这个序 列的变更,这样就可以大致构建出曲线之间影响的链条,形成一个传播链。
这里面有一定的偶然性,随机子序列的选择非常影响模型的效果,我们也尝试随机多次选择,合并结果的方式,去降低它的偶然性。
整体而言,这个模型在测试效果中比直接计算曲线相关性要好不少。
我今天分享差不多到这里结束,谢谢。