如果读者安装的是Anaconda发行版,那么它已经自带了以下库:NumPy、SciPy、Matplotlib、pandas、scikit-learn。

本文主要是对这些库进行简单的介绍,读者也可以到官网阅读更加详细的使用教程。
- NumPy:提供数组支持以及相应的高效的处理函数
- SciPy:提供矩阵支持以及矩阵相关的数值计算模块
- Matplotlib:强大的数据可视化工具、作图库
- pandas:强大、灵活的数据分析和探索工具
- StatsModels:统计建模和计量经济学,包括描述统计、统计模型估计和推断
- scikit-learn:支持回归、分类、聚类等强大的机器学习库
- Keras:深度学习库,用于建立神经网络以及深度学习模型
- Gensim:用来做文本主题模型的库,文本挖掘可能会用到
01 NumPy
Python并没有提供数组功能。虽然列表可以完成基本的数组功能,但它不是真正的数组,而且在数据量较大时,使用列表的速度就会很慢。为此,NumPy提供了真正的数组功能以及对数据进行快速处理的函数。
NumPy还是很多更高级的扩展库的依赖库,我们后面介绍的SciPy、Matplotlib、pandas等库都依赖于它。值得强调的是,NumPy内置函数处理数据的速度是C语言级别的,因此在编写程序的时候,应当尽量使用其内置函数,避免效率瓶颈的(尤其是涉及循环的问题)出现。
在Windows操作系统中,NumPy的安装跟普通第三方库的安装一样,可以通过pip命令进行,命令如下:
- pip install numpy
也可以自行下载源代码,然后使用如下命令安装:
- python setup.py install
在Linux操作系统下,上述方法也是可行的。此外,很多Linux发行版的软件源中都有Python常见的库,因此还可以通过Linux系统自带的软件管理器安装,如在Ubuntu下可以用如下命令安装:
- sudo apt-get install python-numpy
安装完成后,可以使用NumPy对数据进行操作,如代码清单2-27所示。
- 代码清单2-27 使用NumPy操作数组
- # -*- coding: utf-8 -*
- import numpy as np # 一般以np作为NumPy库的别名
- a = np.array([2, 0, 1, 5]) # 创建数组
- print(a) # 输出数组
- print(a[:3]) # 引用前三个数字(切片)
- print(a.min()) # 输出a的最小值
- a.sort() # 将a的元素从小到大排序,此操作直接修改a,因此这时候a为[0, 1, 2, 5]
- b= np.array([[1, 2, 3], [4, 5, 6]]) # 创建二维数组
- print(b*b) # 输出数组的平方阵,即[[1, 4, 9], [16, 25, 36]]
NumPy是Python中相当成熟和常用的库,因此关于它的教程有很多,最值得一看的是其官网的帮助文档,其次还有很多中英文教程,读者遇到相应的问题时,可以查阅相关资料。
参考链接:
http://www.numpy.org
http://reverland.org/python/2012/08/22/numpy
02 SciPy
如果说NumPy让Python有了MATLAB的味道,那么SciPy就让Python真正成为半个MATLAB了。NumPy提供了多维数组功能,但它只是一般的数组,并不是矩阵,比如当两个数组相乘时,只是对应元素相乘,而不是矩阵乘法。SciPy提供了真正的矩阵以及大量基于矩阵运算的对象与函数。
SciPy包含的功能有最优化、线性代数、积分、插值、拟合、特殊函数、快速傅里叶变换、信号处理和图像处理、常微分方程求解和其他科学与工程中常用的计算,显然,这些功能都是挖掘与建模必需的。
SciPy依赖于NumPy,因此安装之前得先安装好NumPy。安装SciPy的方式与安装NumPy的方法大同小异,需要提及的是,在Ubuntu下也可以用类似的命令安装SciPy,安装命令如下:
- sudo apt-get install python-scipy
安装好SciPy后,使用SciPy求解非线性方程组和数值积分,如代码清单2-28所示。
- 代码清单2-28 使用SciPy求解非线性方程组和数值积分
- # -*- coding: utf-8 -*
- # 求解非线性方程组2x1-x2^2=1,x1^2-x2=2
- from scipy.optimize import fsolve # 导入求解方程组的函数
- def f(x): # 定义要求解的方程组
- x1 = x[0]
- x2 = x[1]
- return [2*x1 - x2**2 - 1, x1**2 - x2 -2]
- result = fsolve(f, [1,1]) # 输入初值[1, 1]并求解
- print(result) # 输出结果,为array([ 1.91963957, 1.68501606])
- # 数值积分
- from scipy import integrate # 导入积分函数
- def g(x): # 定义被积函数
- return (1-x**2)**0.5
- pi_2, err = integrate.quad(g, -1, 1) # 积分结果和误差
- print(pi_2 * 2) # 由微积分知识知道积分结果为圆周率pi的一半
参考链接:
http://www.scipy.org
http://reverland.org/python/2012/08/24/scipy
03 Matplotlib
不论是数据挖掘还是数学建模,都要面对数据可视化的问题。对于Python来说,Matplotlib是最著名的绘图库,主要用于二维绘图,当然也可以进行简单的三维绘图。它不仅提供了一整套和MATLAB相似但更为丰富的命令,让我们可以非常快捷地用Python可视化数据,而且允许输出达到出版质量的多种图像格式。
Matplotlib的安装并没有什么特别之处,可以通过“pip install matplotlib”命令安装或者自行下载源代码安装,在Ubuntu下也可以用类似的命令安装,命令如下:
- sudo apt-get install python-matplotlib
需要注意的是,Matplotlib的上级依赖库相对较多,手动安装的时候,需要逐一把这些依赖库都安装好。安装完成后就可以牛刀小试了。下面是一个简单的作图例子,如代码清单2-29所示,它基本包含了Matplotlib作图的关键要素,作图效果如图2-5所示。
- 代码清单2-29 Matplotlib作图示例
- # -*- coding: utf-8 -*-
- import numpy as np
- import matplotlib.pyplot as plt # 导入Matplotlib
- x = np.linspace(0, 10, 1000) # 作图的变量自变量
- y = np.sin(x) + 1 # 因变量y
- z = np.cos(x**2) + 1 # 因变量z
- plt.figure(figsize = (8, 4)) # 设置图像大小
- plt.plot(x,y,label = '$\sin x+1$', color = 'red', linewidth = 2)
- # 作图,设置标签、线条颜色、线条大小
- plt.plot(x, z, 'b--', label = '$\cos x^2+1$') # 作图,设置标签、线条类型
- plt.xlabel('Time(s) ') # x轴名称
- plt.ylabel('Volt') # y轴名称
- plt.title('A Simple Example') # 标题
- plt.ylim(0, 2.2) # 显示的y轴范围
- plt.legend() # 显示图例
- plt.show() # 显示作图结果
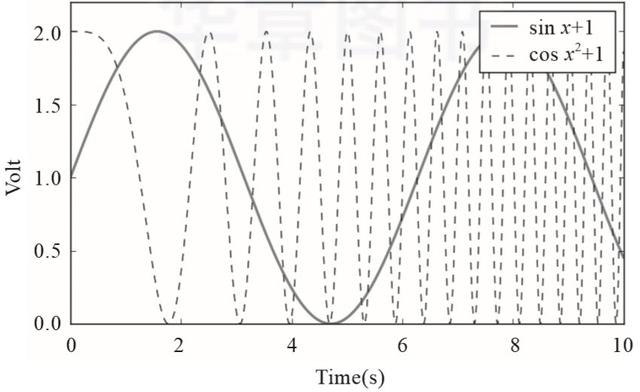
▲图2-5 Matplotlib的作图效果展示
如果读者使用的是中文标签,就会发现中文标签无法正常显示,这是因为Matplotlib的默认字体是英文字体,解决方法是在作图之前手动指定默认字体为中文字体,如黑体(Sim-Hei),命令如下:
- plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
其次,保存作图图像时,负号有可能不能显示,对此可以通过以下代码解决:
- plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
这里有一个小建议:有时间多去Matplotlib提供的“画廊”欣赏用它做出的漂亮图片,也许你就会慢慢爱上Matplotlib作图了。
画廊网址:
http://matplotlib.org/gallery.html
参考链接:
http://matplotlib.org
http://reverland.org/python/2012/09/07/matplotlib-tutorial
04 pandas
pandas是Python下最强大的数据分析和探索工具。它包含高级的数据结构和精巧的工具,使得用户在Python中处理数据非常快速和简单。
pandas建造在NumPy之上,它使得以NumPy为中心的应用使用起来更容易。pandas的名称来自于面板数据(Panel Data)和Python数据分析(Data Analysis),它最初作为金融数据分析工具被开发,由AQR Capital Management于2008年4月开发问世,并于2009年底开源出来。
pandas的功能非常强大,支持类似SQL的数据增、删、查、改,并且带有丰富的数据处理函数;支持时间序列分析功能;支持灵活处理缺失数据;等等。事实上,单纯地用pandas这个工具就足以写一本书,读者可以阅读pandas的主要作者之一Wes Mc-Kinney写的《利用Python进行数据分析》来学习更详细的内容。
1. 安装
pandas的安装相对来说比较容易一些,只要安装好NumPy之后,就可以直接安装了,通过pip install pandas命令或下载源码后通过python setup.py install命令安装均可。
由于我们频繁用到读取和写入Excel,但默认的pandas还不能读写Excel文件,需要安装xlrd(读)度和xlwt(写)库才能支持Excel的读写。为Python添加读取/写入Excel功能的命令如下:
- pip install xlrd # 为Python添加读取Excel的功能
- pip install xlwt # 为Python添加写入Excel的功能
2. 使用
在后面的章节中,我们会逐步展示pandas的强大功能,而在本节,我们先以简单的例子一睹为快。
首先,pandas基本的数据结构是Series和DataFrame。Series顾名思义就是序列,类似一维数组;DataFrame则相当于一张二维的表格,类似二维数组,它的每一列都是一个Series。
为了定位Series中的元素,pandas提供了Index这一对象,每个Series都会带有一个对应的Index,用来标记不同的元素,Index的内容不一定是数字,也可以是字母、中文等,它类似于SQL中的主键。
类似的,DataFrame相当于多个带有同样Index的Series的组合(本质是Series的容器),每个Series都带有一个唯一的表头,用来标识不同的Series。pandas中常用操作的示例如代码清单2-30所示。
- 代码清单2-30 pandas中的常用操作
- # -*- coding: utf-8 -*-
- import numpy as np
- import pandas as pd # 通常用pd作为pandas的别名。
- s = pd.Series([1,2,3], index=['a', 'b', 'c']) # 创建一个序列s
- # 创建一个表
- d = pd.DataFrame([[1, 2, 3], [4, 5, 6]], columns=['a', 'b', 'c'])
- d2 = pd.DataFrame(s) # 也可以用已有的序列来创建数据框
- d.head() # 预览前5行数据
- d.describe() # 数据基本统计量
- # 读取文件,注意文件的存储路径不能带有中文,否则读取可能出错。
- pd.read_excel('data.xls') # 读取Excel文件,创建DataFrame。
- pd.read_csv('data.csv', encoding='utf-8') # 读取文本格式的数据,一般用encoding指定编码。
由于pandas是本书的主力工具,在后面将会频繁使用它,因此这里不再详细介绍,后文会更加详尽地讲解pandas的使用方法。
参考链接:
http://pandas.pydata.org/pandas-docs/stable/
05 StatsModels
pandas着重于数据的读取、处理和探索,而StatsModels则更加注重数据的统计建模分析,它使得Python有了R语言的味道。StatsModels支持与pandas进行数据交互,因此,它与pandas结合成为Python下强大的数据挖掘组合。
安装StatsModels相当简单,既可以通过pip命令安装,又可以通过源码安装。对于Windows用户来说,官网上甚至已经有编译好的exe文件可供下载。如果手动安装的话,需要自行解决好依赖问题,StatsModels依赖于pandas(当然也依赖于pandas所依赖的库),同时还依赖于Pasty(一个描述统计的库)。
使用StatsModels进行ADF平稳性检验,如代码清单2-31所示。
- 代码清单2-31 使用StatsModels进行ADF平稳性检验
- # -*- coding: utf-8 -*-
- from statsmodels.tsa.stattools import adfuller as ADF # 导入ADF检验
- import numpy as np
- ADF(np.random.rand(100)) # 返回的结果有ADF值、p值等
参考链接:
http://statsmodels.sourceforge.net/stable/index.html
06 scikit-learn
从该库的名字可以看出,这是一个与机器学习相关的库。不错,scikit-learn是Python下强大的机器学习工具包,它提供了完善的机器学习工具箱,包括数据预处理、分类、回归、聚类、预测、模型分析等。
scikit-learn依赖于NumPy、SciPy和Matplotlib,因此,只需要提前安装好这几个库,然后安装scikit-learn基本上就没有什么问题了,安装方法跟前几个库的安装一样,可以通过pip install scikit-learn命令安装,也可以下载源码自行安装。
使用scikit-learn创建机器学习的模型很简单,示例如代码清单2-32所示。
- 代码清单2-32 使用scikit-learn创建机器学习模型
- # -*- coding: utf-8 -*-
- from sklearn.linear_model import LinearRegression # 导入线性回归模型
- model = LinearRegression() # 建立线性回归模型
- print(model)
1. 所有模型提供的接口有
对于训练模型来说是model.fit(),对于监督模型来说是fit(X, y),对于非监督模型是fit(X)。
2. 监督模型提供如下接口
- model.predict(X_new):预测新样本。
- model.predict_proba(X_new):预测概率,仅对某些模型有用(比如LR)。
- model.score():得分越高,fit越好。
3. 非监督模型提供如下接口
- model.transform():从数据中学到新的“基空间”。
- model.fit_transform():从数据中学到新的基并将这个数据按照这组“基”进行转换。
Scikit-learn本身提供了一些实例数据供我们上手学习,比较常见的有安德森鸢尾花卉数据集、手写图像数据集等。
安德森鸢尾花卉数据集有150个鸢尾花的尺寸观测值,如萼片长度和宽度,花瓣长度和宽度;还有它们的亚属:山鸢尾(iris setosa)、变色鸢尾(iris versicolor)和维吉尼亚鸢尾(iris virginica)。导入iris数据集并使用该数据训练SVM模型,如代码清单2-33所示。
- 代码清单2-33 导入iris数据集并训练SVM模型
- # -*- coding: utf-8 -*-
- from sklearn import datasets # 导入数据集
- iris = datasets.load_iris() # 加载数据集
- print(iris.data.shape) # 查看数据集大小
- from sklearn import svm # 导入SVM模型
- clf = svm.LinearSVC() # 建立线性SVM分类器
- clf.fit(iris.data, iris.target) # 用数据训练模型
- clf.predict([[ 5.0, 3.6, 1.3, 0.25]]) # 训练好模型之后,输入新的数据进行预测
- clf.coef_ # 查看训练好模型的参数
参考链接:
http://scikit-learn.org/stable/
07 Keras
scikit-learn已经足够强大了,然而它并没有包含这一强大的模型—人工神经网络。人工神经网络是功能相当强大但是原理又相当简单的模型,在语言处理、图像识别等领域都有重要的作用。近年来逐渐流行的“深度学习”算法,实质上也是一种神经网络,可见在Python中实现神经网络是非常必要的。
本书用Keras库来搭建神经网络。事实上,Keras并非简单的神经网络库,而是一个基于Theano的强大的深度学习库,利用它不仅可以搭建普通的神经网络,还可以搭建各种深度学习模型,如自编码器、循环神经网络、递归神经网络、卷积神经网络等。由于它是基于Theano的,因此速度也相当快。
Theano也是Python的一个库,它是由深度学习专家Yoshua Bengio带领的实验室开发出来的,用来定义、优化和高效地解决多维数组数据对应数学表达式的模拟估计问题。它具有高效实现符号分解、高度优化的速度和稳定性等特点,最重要的是它还实现了GPU加速,使得密集型数据的处理速度是CPU的数十倍。
用Theano就可以搭建起高效的神经网络模型,然而对于普通读者来说门槛还是相当高的。Keras正是为此而生,它大大简化了搭建各种神经网络模型的步骤,允许普通用户轻松地搭建并求解具有几百个输入节点的深层神经网络,而且定制的自由度非常大,读者甚至因此惊呼:搭建神经网络可以如此简单!
1. 安装
安装Keras之前首先需要安装NumPy、SciPy和Theano。安装Theano之前首先需要准备一个C++编译器,这在Linux系统下是自带的。因此,在Linux系统下安装Theano和Keras都非常简单,只需要下载源代码,然后用python setup.py install安装就行了,具体可以参考官方文档。
可是在Windows系统下就没有那么简单了,因为它没有现成的编译环境,一般而言是先安装MinGW(Windows系统下的GCC和G++),然后再安装Theano(提前装好NumPy等依赖库),最后安装Keras,如果要实现GPU加速,还需要安装和配置CUDA。
值得一提的是,在Windows系统下的Keras速度会大打折扣,因此,想要在神经网络、深度学习做深入研究的读者,请在Linux系统下搭建相应的环境。
参考链接:
http://deeplearning.net/software/theano/install.html#install
2. 使用
用Keras搭建神经网络模型的过程相当简单,也相当直观,就像搭积木一般,通过短短几十行代码,就可以搭建起一个非常强大的神经网络模型,甚至是深度学习模型。简单搭建一个MLP(多层感知器),如代码清单2-34所示。
- 代码清单2-34 搭建一个MLP(多层感知器)
- # -*- coding: utf-8 -*-
- from keras.models import Sequential
- from keras.layers.core import Dense, Dropout, Activation
- from keras.optimizers import SGD
- model = Sequential() # 模型初始化
- model.add(Dense(20, 64)) # 添加输入层(20节点)、第一隐藏层(64节点)的连接
- model.add(Activation('tanh')) # 第一隐藏层用tanh作为激活函数
- model.add(Dropout(0.5)) # 使用Dropout防止过拟合
- model.add(Dense(64, 64)) # 添加第一隐藏层(64节点)、第二隐藏层(64节点)的连接
- model.add(Activation('tanh')) # 第二隐藏层用tanh作为激活函数
- model.add(Dropout(0.5)) # 使用Dropout防止过拟合
- model.add(Dense(64, 1)) # 添加第二隐藏层(64节点)、输出层(1节点)的连接
- model.add(Activation('sigmoid')) # 输出层用sigmoid作为激活函数
- sgd = SGD(lr=0.1, decay=1e-6, momentum=0.9, nesterov=True) # 定义求解算法
- model.compile(loss='mean_squared_error', optimizer=sgd) # 编译生成模型,损失函数为平均误差平方和
- model.fit(X_train, y_train, nb_epoch=20, batch_size=16) # 训练模型
- score = model.evaluate(X_test, y_test, batch_size=16) # 测试模型
要注意的是,Keras的预测函数跟scikit-learn有所差别,Keras用model.predict()方法给出概率,用model.predict_classes()给出分类结果。
参考链接:
https://keras.io/
08 Gensim
在Gensim官网中,它对自己的简介只有一句话:topic modelling for humans!
Gensim用来处理语言方面的任务,如文本相似度计算、LDA、Word2Vec等,这些领域的任务往往需要比较多的背景知识。
在这一节中,我们只是提醒读者有这么一个库的存在,而且这个库很强大,如果读者想深入了解这个库,可以去阅读官方帮助文档或参考链接。
值得一提的是,Gensim把Google在2013年开源的著名的词向量构造工具Word2Vec编译好了,作为它的子库,因此需要用到Word2Vec的读者也可以直接使用Gensim,而无须自行编译了。
Gensim的作者对Word2Vec的代码进行了优化,所以它在Gensim下的表现比原生的Word2Vec还要快。(为了实现加速,需要准备C++编译器环境,因此,建议使用Gensim的Word2Vec的读者在Linux系统环境下运行。)
下面是一个Gensim使用Word2Vec的简单例子,如代码清单2-35所示。
- 代码清单2-35 Gensim使用Word2Vec的简单示例
- # -*- coding: utf-8 -*-
- import gensim, logging
- logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level= logging.INFO)
- # logging是用来输出训练日志
- # 分好词的句子,每个句子以词列表的形式输入
- sentences = [['first', 'sentence'], ['second', 'sentence']]
- # 用以上句子训练词向量模型
- model = gensim.models.Word2Vec(sentences, min_count=1)
- print(model['sentence']) # 输出单词sentence的词向量。
参考链接:
http://radimrehurek.com/gensim/