【51CTO.com快译】在上一篇文章《从零开始构建一个人工神经网络(上)》中,我们一开始讨论了什么是人工神经网络,接着介绍了如何使用Python从零开始构建一个简单的神经网络,只有1个输入层和1个输出层。这种神经网络名为Perceptron。然而,能够执行图像分类和股市分析等复杂任务的实际神经网络除了输入层和输出层外还有多个隐藏层。
我们在上篇中得出结论,Perceptron能够找到线性决策边界。我们使用Perceptron借助虚拟数据集来预测某人是否患有糖尿病。然而,Perceptron无法找到非线性决策边界。
我们在本文中将构建一个有1个输入层、1个隐藏层和1个输出层的神经网络。我们会看到,我们构建的神经网络能够找到非线性边界。
生成数据集
不妨先创造可供试用的数据集。幸好,scikit-learn有一些有用的数据集生成器,因此我们不需要自行编写代码。我们将使用make_moons函数。
- from sklearn import datasets
- np.random.seed(0)
- feature_set, labels = datasets.make_moons(300, noise=0.20)
- plt.figure(figsize=(10,7))
- plt.scatter(feature_set[:,0], feature_set[:,1], c=labels, cmap=plt.cm.Spectral)

图1
我们生成的数据集有两个类别,分别标为红点和蓝点。可以将蓝点视为男性患者,将红点视为女性患者,x轴和y轴是医学度量指标。
我们的目的是训练可根据x和y坐标预测正确类别(男性或女性)的机器学习分类器。请注意,数据不是线性可分离的,我们无法绘制将两个类别分开的直线。这意味着,除非你手动设计适用于特定数据集的非线性特征(比如多项式),否则线性分类器(比如没有任何隐藏层甚至没有逻辑回归的ANN)将无法拟合数据。
有1个隐藏层的神经网络
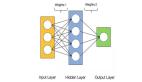
这是我们的简单网络:

图2
我们有两个输入:x1和x2。有单单一个隐藏层,它有3个单元(节点):h1、h2和h3。最后,有两个输出:y1和y2。连接它们的箭头是权重。有两个权重矩阵:w和u。w权重连接输入层和隐藏层,u权重连接隐藏层和输出层。我们使用字母w和u,那样更容易关注要关注的计算。你还能看到我们将输出y1和y2与目标t1和t2进行了比较。
进行计算之前,我们需要介绍最后一个字母。让a成为激活前的线性组合。因此,我们有:
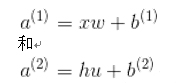
由于我们无法穷尽所有激活函数和所有损失函数,因此专注于两种最常见的函数。Sigmoid激活和L2范数损失。有了该新信息和新符号,输出y等于激活的线性组合。
因此,就输出层而言,我们有:
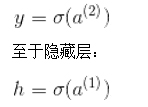
由于方法不同,我们将分别检查输出层和隐藏层的反向传播。
我想提醒诸位:
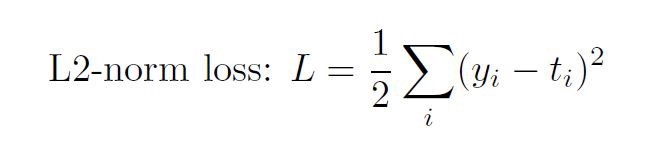
Sigmoid函数是:

导数是:
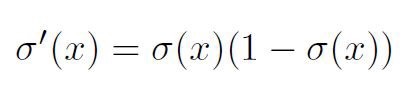
输出层的反向传播
为了获得更新规则:
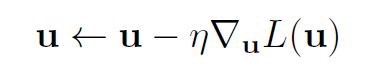
我们必须计算
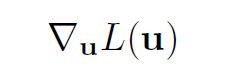
以单个权重uij为例。损失w.r.t. uij的偏导数等于:
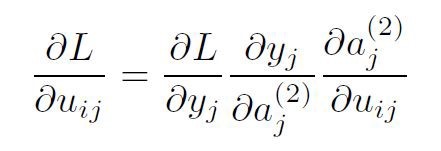
其中i对应上一层(该变换的输入层),j对应下一层(该变换的输出层)。只要根据链式规则即可计算出偏导数。
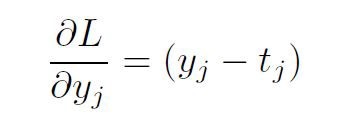
关注L2-范数损失导数。
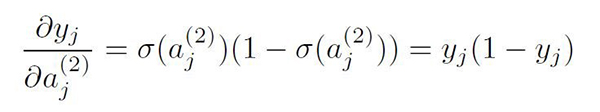
关注Sigmoid导数。
最后,三阶偏导数就是下面的导数:
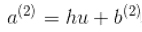
所以,
替换上面表达式中的偏导数,我们得到:
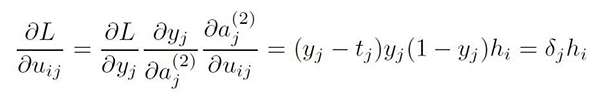
因此,输出层的单个权重的更新规则由下式给出:

隐藏层的反向传播
与输出层的反向传播类似,wij将依赖:
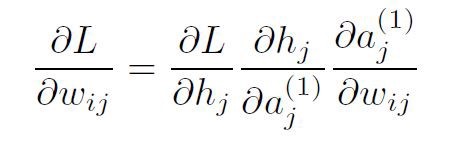
关注链式规则。利用到目前为止我们可以利用Sigmoid激活和线性模型进行转换的结果,我们得到:

和
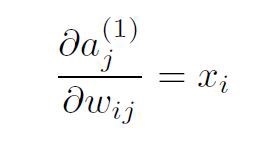
反向传播的实际问题来自该术语

那是由于没有“隐藏”目标。可以在下面看看权重w11的解决方案。查看计算过程时,建议先看一下上面显示的NN图。
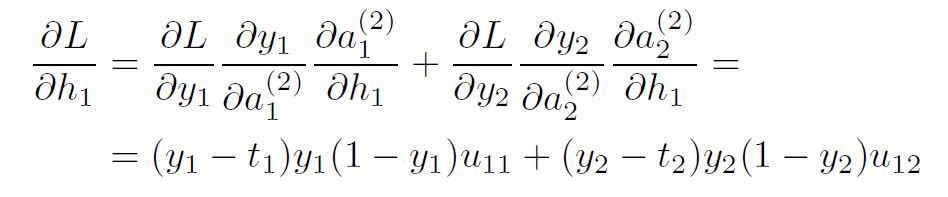
从这里,我们可以计算
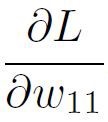
这就是我们想要的。最终的表达式是:
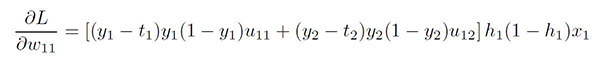
该方程的广义形式是:

反向传播的一般化
使用输出层和隐藏层的反向传播的结果,我们可以将它们放到一个公式中,在存在L2-范数损失和Sigmoid激活的情况下总结反向传播。
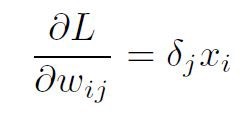
其中就隐藏层而言
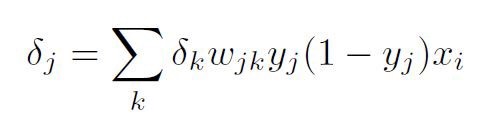
实现有1个隐藏层的神经网络的代码
现在不妨实现我们刚使用Pytho从零开始的神经网络。我们将再次尝试对上面创建的非线性数据进行分类。
我们先为梯度下降定义一些有用的变量和参数,比如训练数据集大小、输入层和输出层的维度。
- num_examples = len(X) # training set size
- nn_input_dim = 2 # input layer dimensionality
- nn_output_dim = 2 # output layer dimensionality
还定义梯度下降参数。
- epsilon = 0.01 # learning rate for gradient descent
- reg_lambda = 0.01 # regularization strength
首先,不妨实现上面定义的损失函数。我们使用该函数来评估模型的表现有多好:
- # Helper function to evaluate the total loss on the dataset
- def calculate_loss(model, X, y):
- num_examples = len(X) # training set size
- W1, b1, W2, b2 = model['W1'], model['b1'], model['W2'], model['b2']
- # Forward propagation to calculate our predictions
- z1 = X.dot(W1) + b1
- a1 = np.tanh(z1)
- z2 = a1.dot(W2) + b2
- exp_scores = np.exp(z2)
- probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
- # Calculating the loss
- corect_logprobs = -np.log(probs[range(num_examples), y])
- data_loss = np.sum(corect_logprobs)
- # Add regulatization term to loss (optional)
- data_loss += Config.reg_lambda / 2 * (np.sum(np.square(W1)) + np.sum(np.square(W2)))
- return 1. / num_examples * data_loss
我们还实现了helper函数,计算网络的输出。它进行正向传播,返回概率最大的类别。
- def predict(model, x):
- W1, b1, W2, b2 = model['W1'], model['b1'], model['W2'], model['b2']
- # Forward propagation
- z1 = x.dot(W1) + b1
- a1 = np.tanh(z1)
- z2 = a1.dot(W2) + b2
- exp_scores = np.exp(z2)
- probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)
- return np.argmax(probs, axis=1)
最后是训练神经网络的函数。它使用我们在上面找到的反向传播导数实现了批梯度下降。
该函数学习神经网络的参数后返回模型。
nn_hdim:隐藏层中节点的数量。
num_passes:遍历梯度下降训练数据的次数。
print_loss:如果是True,每1000次迭代就打印输出损失。
- def build_model(X, y, nn_hdim, num_passes=20000, print_loss=False):
- # Initialize the parameters to random values. We need to learn these.
- num_examples = len(X)
- np.random.seed(0)
- W1 = np.random.randn(Config.nn_input_dim, nn_hdim) / np.sqrt(Config.nn_input_dim)
- b1 = np.zeros((1, nn_hdim))
- W2 = np.random.randn(nn_hdim, Config.nn_output_dim) / np.sqrt(nn_hdim)
- b2 = np.zeros((1, Config.nn_output_dim))# This is what we return at the end
- model = {}# Gradient descent. For each batch...
- for i in range(0, num_passes):# Forward propagation
- z1 = X.dot(W1) + b1
- a1 = np.tanh(z1)
- z2 = a1.dot(W2) + b2
- exp_scores = np.exp(z2)
- probs = exp_scores / np.sum(exp_scores, axis=1, keepdims=True)# Backpropagation
- delta3 = probs
- delta3[range(num_examples), y] -= 1
- dW2 = (a1.T).dot(delta3)
- db2 = np.sum(delta3, axis=0, keepdims=True)
- delta2 = delta3.dot(W2.T) * (1 - np.power(a1, 2))
- dW1 = np.dot(X.T, delta2)
- db1 = np.sum(delta2, axis=0)# Add regularization terms (b1 and b2 don't have regularization terms)
- dW2 += Config.reg_lambda * W2
- dW1 += Config.reg_lambda * W1# Gradient descent parameter update
- W1 += -Config.epsilon * dW1
- b1 += -Config.epsilon * db1
- W2 += -Config.epsilon * dW2
- b2 += -Config.epsilon * db2# Assign new parameters to the model
- model = {'W1': W1, 'b1': b1, 'W2': W2, 'b2': b2}# Optionally print the loss.
- # This is expensive because it uses the whole dataset, so we don't want to do it too often.
- if print_loss and i % 1000 == 0:
- print("Loss after iteration %i: %f" % (i, calculate_loss(model, X, y)))return model
最后是主方法:
- def main():
- X, y = generate_data()
- model = build_model(X, y, 3, print_loss=True)
- visualize(X, y, model)
每1000次迭代打印输出损失:
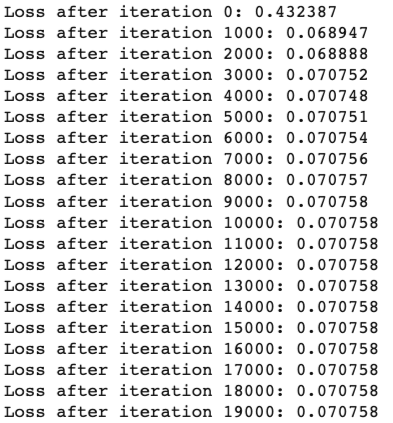
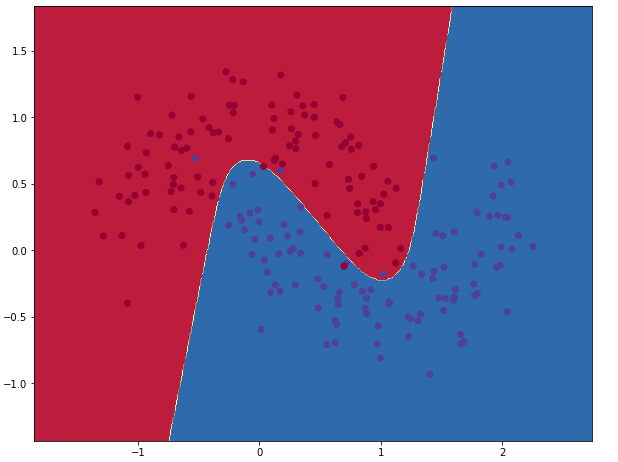
图3
隐藏层中节点数量是3时的分类
现在了解不同的隐藏层大小对结果有何影响。
- hidden_layer_dimensions = [1, 2, 3, 4, 5, 20, 50]
- for i, nn_hdim in enumerate(hidden_layer_dimensions):
- plt.subplot(5, 2, i+1)
- plt.title('Hidden Layer size %d' % nn_hdim)
- model = build_model(X, y,nn_hdim, 20000, print_loss=False)
- plot_decision_boundary(lambda x:predict(model,x), X, y)
- plt.show()
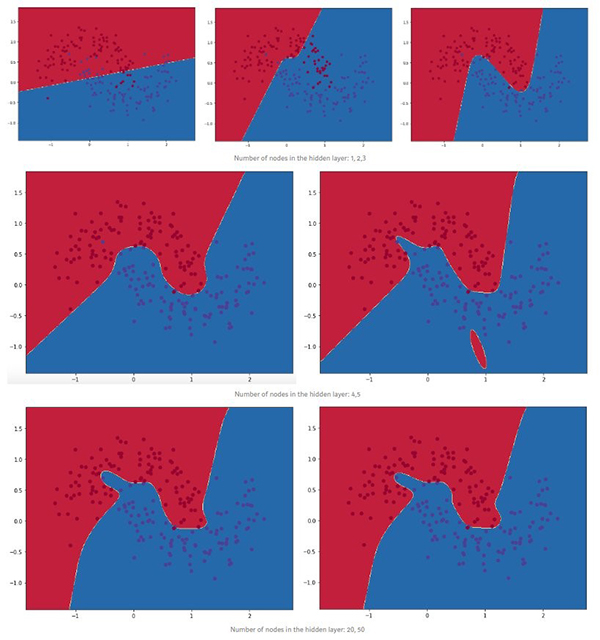
图4
我们可以看到,低维度的隐藏层很好地捕获了数据的总体趋势。较高维度易于过拟合。它们在“记忆”数据,而不是拟合总体形状。
如果我们在另外的测试集上评估模型,由于更好的泛化能力,隐藏层尺寸较小的模型可能会表现更好。我们可以通过更强的正则化来抵消过拟合,但是为隐藏层选择正确的尺寸是一种极为“经济”的解决方法。
你可以在该GitHub存储库中获取全部代码。
nageshsinghc4 / Artificial-Neural-Network-from-scratch-python
结论
我们在本文中介绍了如何使用Numpy Python,用数学导出有1个隐藏层的神经网络,并创建了有1个隐藏层的神经网络。
原文标题:Build an Artificial Neural Network From Scratch: Part 2,作者:Nagesh Singh Chauhan
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】