加速新境界:通过使用简单的缓存功能,仅需一行代码即可加速你的函数。
不久前,我构建了一个日常运行的ETL管道,其通过从外部服务中抽取数据来丰富输入数据,然后将结果加载到数据库中。
随着输入数据的增加,等待外部服务器的响应变得非常费时,这使得ETL进程越来越慢。经过一番调查,我发现与总记录数(~500k)相比,并没有太多不同的输入值(~500)。
因此,换句话说,使用相同的参数调用外部服务时,每个参数大约要重复执行1000次。
像这样的情况是使用缓存的主要用例。缓存一个函数意味着无论何时首次计算函数的返回值,都会将其输入和结果放在字典中。
对于每个后续函数调用,首先通过查看缓存来检查结果是否已经计算过。如果在缓存中找到了,那就很完美,不需要再次计算!如果没有找到,就计算结果并将输入和结果存储在缓存中,以便下一个函数调用时查找到它。
Python标准库附带了许多鲜为人知但功能强大的软件包。对于本示例,将使用functools中的lru_cache。(LRU代表“最近最少使用(Least Recently Used)”,正如字面意思,这明确意味着缓存将保留最近的输入/结果对。)
从Fun(c)tools中导入lru_cache
把c放进括号中有点像一个蹩脚的笑话,因为这样functools就变成了fun tools(有趣的工具),使用缓存当然很有趣!
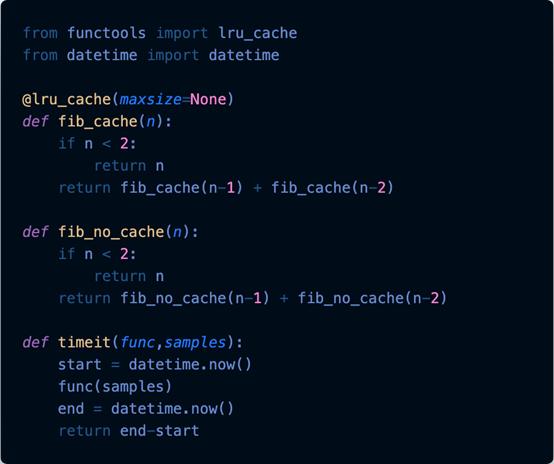
这里无需过多解释。导入lru_cache并用它来装饰一个函数,该函数将生成斐波那契数。
装饰函数意味着将该函数与缓存函数包装在一起,随后每当调用fib_cache函数时,都将调用缓存的函数。
比赛开始
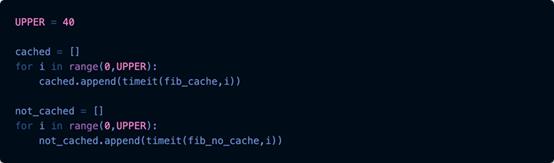
我们进行了一个实验,计算函数的缓存和未缓存版本从0到40计算所有斐波那契数所花费的时间,并将结果放入各自的列表中。
获胜者
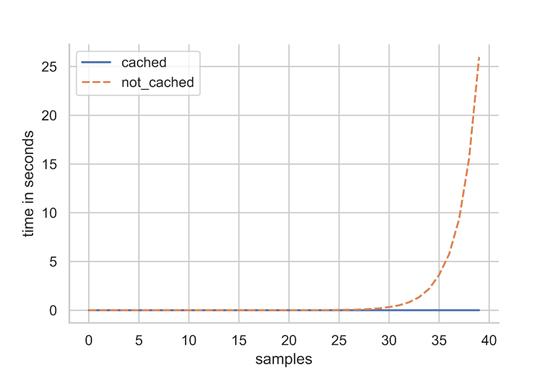
对于较小的斐波那契数,二者并没有什么大的区别,但是一旦达到约30个样本,缓存函数的效率增益就开始累加。
我没有耐心让未缓存的版本运行超过40个样本,因为它的运行时间是指数增长的。而对于缓存的版本,它的运行时间只是线性增量。
这就完成了!距离Python缓存仅一行代码之遥。毕竟它并没那么可怕。
在初始示例中,我在Pandas数据框上使用了数据转换。值得一提的是,缓存的函数可以传递给Pandas apply,而无需进行其它的任何更改。
是不是很棒?你也来试试吧~