疫情当前,科技向善,腾讯应用都开始支撑各大远程工作、教育的场景,众所周知的“腾讯课堂”、“微信课堂”,“腾讯会议”在抗击疫情中做出了很大的贡献,数亿人成为了这些系统的用户。通过可视、互动的远程有效沟通、交流,一定程度保障了生产、学习工作的有序进行。
笔者有幸参与了腾讯云的这次“战疫”工作,监控系统有效地支撑了几大应用场景。
01 业务的监控需求
腾讯会议放量较早、腾讯课堂、微信课堂也相继放量,应对海量的用户场景需求,我们分析系统的主要需求表现在:
1. 如何了解设备整体水位与资源趋势?
前面提及过,各大系统基于视频云技术搭建,视频云本身存在较多的视频、音频处理工作,设备量的需求日益增长。每天面对数万核、数十万核的设备量需求,虽然每个模块有各自的负载特点,但大盘层急需准确把控整体系统水位,从而判断整体设备需求趋势。跟后端的设备供应部门准确、有效地提出需求。
2. 如何针对有可能出现的问题,第一时间做出有效分析?
比如:
a. 如何避免在海量指标中把控重点指标?
从单维指标到多维指标,系统的指标上万个,且由于历史原因,指标散落在不同BG的数个监控系统,如果对于重点指标缺乏有效的抽象、监控。不分主次地处理,可能忽略重要指标的把控,引起严重后果。

图一、错综复杂的立体式监控系统
b. 监控系统如何有效监测上述这些指标,使告警敛到合适范围?
常见的监控手段为阈值监控,对业务形态比较熟练的开发、运维人员在指标上设置一个“恰当”的阈值,一旦偏离阈值,系统即发送告警到开发人员。
然而阈值设置的合理性不易判断。在数千万、上亿用户的场景下,阈值少设或多设 0.01% 都代表数千、上万人的体验受损,而且不同时间的数据,数据也会呈现一定的周期规律性,如图二所示,简单的阈值告警显然无法满足多样化的业务需求。
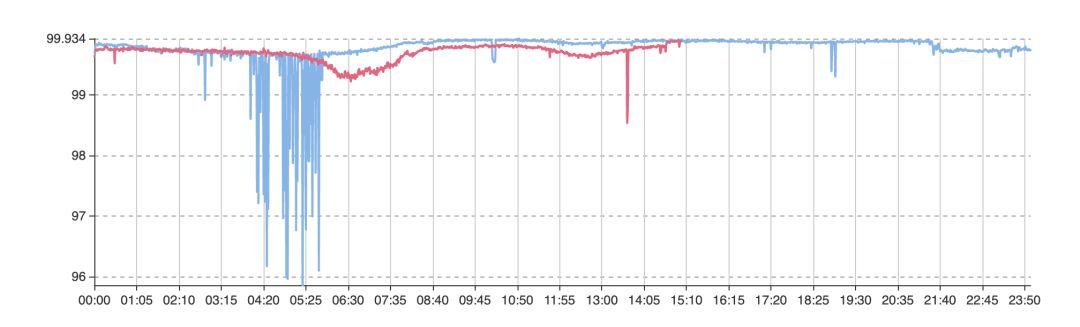
图二、 无法判断“阈值”的业务指标曲线
c. 问题发现的第一时间,开发、运维人员迫切需要知道问题的表现根因。以便快速介入处理,如何准确发现根因?
业务故障时,在大盘面,可能看到的是整个成功率(或用户量)的下降。但引起下降的可能性是较多的。必须在第一时间找到原因,深入排查,以减少业务故障时间。
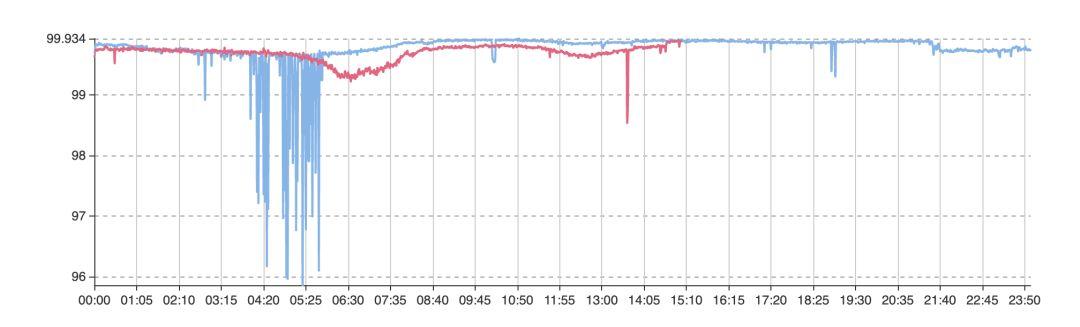
图三-1 某业务整体大盘成功率曲线
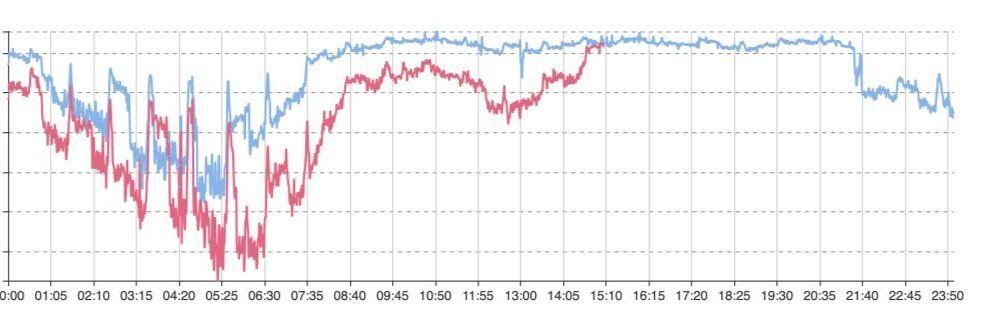
图三-2 某业务下钻维度成功率曲线
02 监控解决方案
监控的存在是为业务服务的,团队一起进行了碰头,很快形成了解决方案并实施:
一、梳理重点模块、重点指标。建立直观的业务可观测性
基于业务架构剖析、业务形态理解,我们梳理起若干个关键指标。所谓关键即业务生死指标,这些指标可以从以下维度来衡量:
1、对用户有损
用户有损的指标有:在线用户量,用户登陆成功率,用户进房成功率,关键接口调用成功率…
2、对收入有损
购买成功率、付费成功率、收入趋势等 ……
3、资源风险相关
分SET、分模块CPU负载、出口带宽等、以便及时介入调度。一般每个SET的容量是有限的,必须及时观察各SET容量水位及负载趋势,一方面系统自行进行SET间用户调度,一方面人为可在必要时进行调度干预。
二、导入自定义 Dashboard 能力
采用 Dashboard 展示以上指标,抽象形成数个作战视图。较为常见的 Dashboard 有 Grafana, Kibana 等,我们采用了较常用的开源 Grafana,原因是:
- 非常适合时序展示展示,提供自由的时间选择功能;
- 易于运维人员自由定制。配置门槛极低;
- 易于适配各种异构数据源, 开发工作量较少。
在原有 Grafana 我们做了以下定制:
- 集成公司 OA 权限控制机制。
- 适配公司内部各监控系统数据源。时序数据库存储协议转换,以有利于 grafana 直接拉取数据,而无需数据转存,以节约数据存储成本、获得较为实时的数据效果。
图四:自定义 dashboard
三、引入 AIOps 能力
1. 无阈值监控
在之前多次提及过无阈值监控,在此不做过多阐述。基于统计(无监督)及 基于数据特征、人员打标形成的有监督方法。在此次监控保障中发挥了重要力量。
同时工程上我们做了一些场景导入,我们开发了“云监控助手” 移动端。方便用户自行一键订阅、退订指标。获得了较好的告警触达准确性。避免告警过多骚扰。同时通过用户的订阅退订动作,形成了用户的兴趣点标签,为后续的告警推荐、模型训练打下了基础。
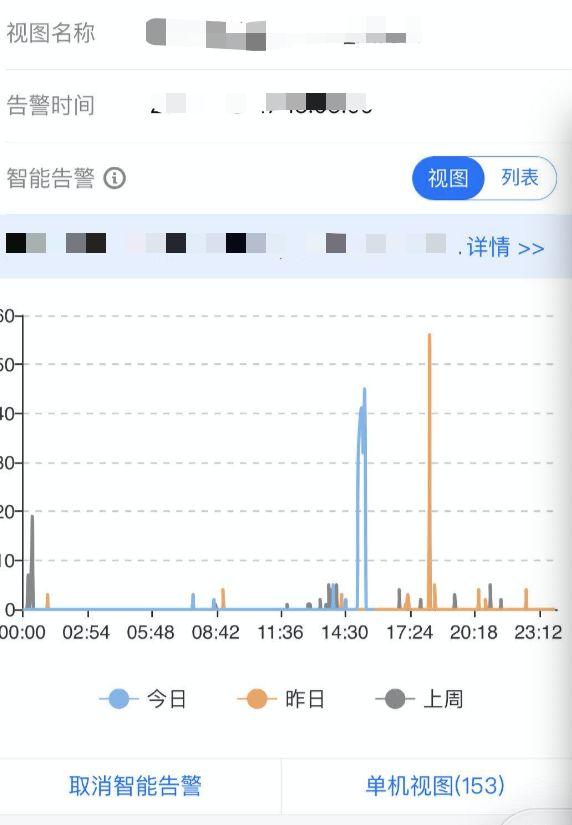
图五 - 智能告警配置移动端
2. 智能多维
业务人员关注整体业务大盘,同时业务保障工作是一个相对细致的工作,既要保障大盘稳定性,也要随时诊断导致各种业务异常的根因,现场如战场,故障场景下,早一秒钟获得根因,就能早一秒钟修复故障,减少损失,多维分析方法是非常快速的问题分析方法,举两个例子:
1)客户端质量
客户端问题一般出现在:无法登陆、卡慢、无法退出、无法发言、异常中断等。这种情况下,一般根因上可能与客户的地域、运营商、客户端版本相关,利用智能多维较为容易找到客户端根因汇聚。
2)后端 API 质量
后端 API 质量主要出现在服务间调用,腾讯云用户API主要表现在WEB端调用后端和用户应用调用腾讯云。一般根因上可以出现在用户调用方式(API/WEB),地域、产品、命令字、版本等层面。通过智能多维能迅速找到汇聚。
多维根因分析实现流程如下:
- 统一业务指标上报,抽象Fields(指标) 与 Tags(维度) 上报至集中存储, 相关技术选型有 Druid, InfluxDB, Prometheus等 。
- 抽象业务关键指标, 集中监控关键指标。
- 通过无阈值/有规则检测方法获得业务异常指标曲线。
- 获得异常期间故障根因维度。常用算法:决策树、Adtributor 等。
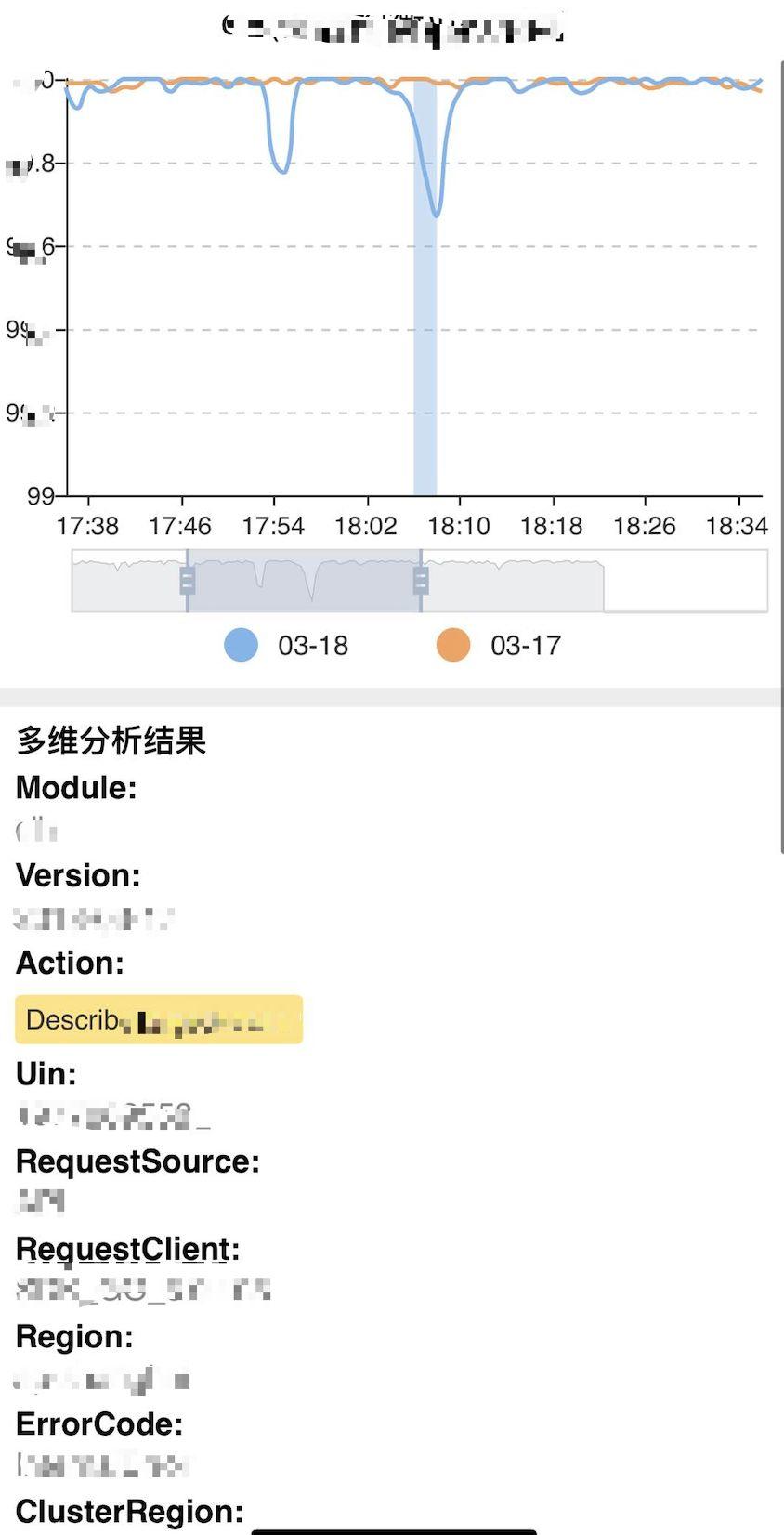
图六 - 多维根因分析
3. 告警相似性
经过告警检测后,产生的告警量可能还是不少,能对告警进行合并显然是非常重要的需求,我们其中的一个解决办法是先通过聚类算法对各告警源进行聚类(采用one-pass clustering, k-means等方法),各告警间的距离可以采用 Pearson 相似性公式获得。
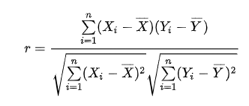
该方法能获得较好的相似性效果,减少对人员的告警骚扰。
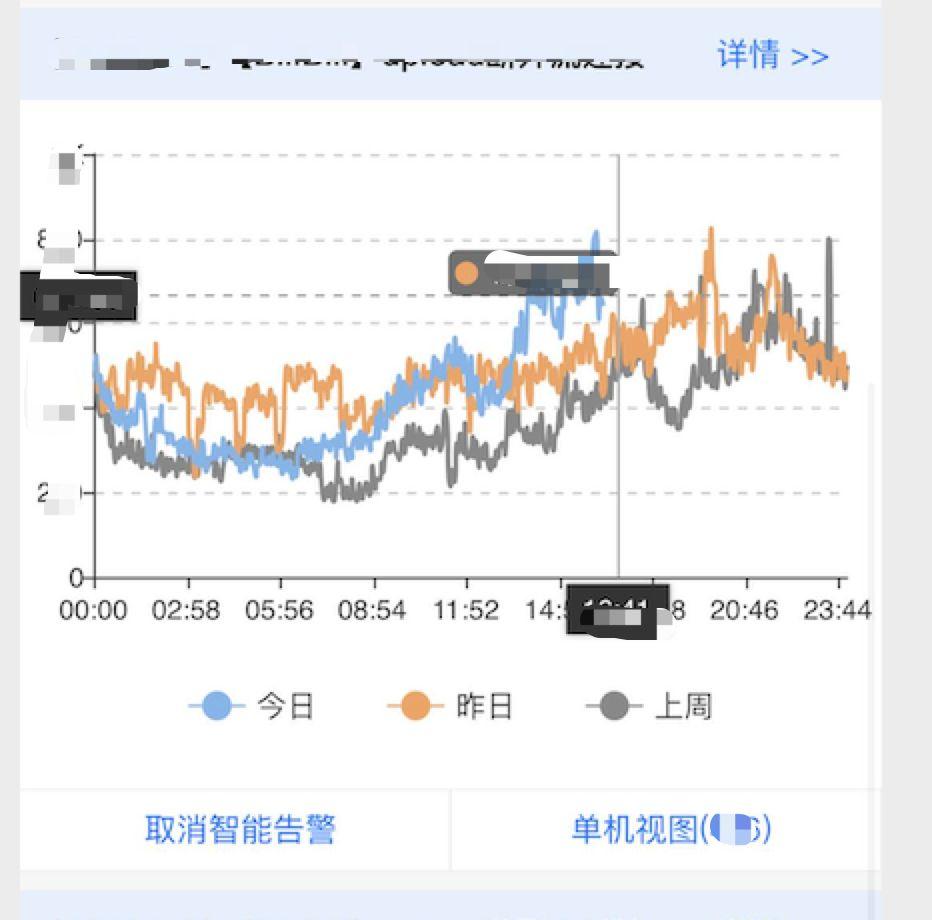
图六:具有高度相似型的两个指标
03 用户反馈分析
用户反馈分析的技术在腾讯内部已经相对成熟了,在2015年前后就已经相继推出一些反馈分析功能。对于海量用户反馈分析,此方法相对比较有效。
较为常见的处理方式是:
- 产品增加投诉入口,用户的反馈通过接口上报至指定位置。
- 将投诉信息分词,分词方法很多,不再详述。
- 分析词频,通过无阈值监控,对突增词频做重点分析处理。
但另一方面此类旁路监控,已经相对滞后。最有效的办法是在问题发生前就解决它,而不是引起投诉后。
04 小记
随着业务的发展,技术越来越中台化,业务质量保障越来越重要,如何有效破除数据烟囱,形成统一视图?监控的本质是数据,如何利用这些数据,及时发现业务问题、有效诊断业务问题,是监控的关键目的所在。