换脸视频是滥用 DL 的一大后果,只要网上有你的照片,那么就有可能被换脸到其它背景或视频。然而,有了这样的开源攻击模型,上传的照片不再成为问题,deepfake 无法直接拿它做换脸。

看上去效果很好,只需要加一些人眼看不到的噪声,换脸模型就再也生成不了正确人脸了。这样的思路不正是对抗攻击么,之前的攻击模型会通过「伪造真实图像」来欺骗识别模型。而现在,攻击模型生成的噪声会武装人脸图像,从而欺骗 deepfake,令 deepfake 生成不了欺骗人类的换脸模型。
这篇波士顿大学的研究放出来没多久,就受到很多研究者的热议,在 Reddit 上也有非常多的讨论。看到这篇论文,再加上研究者有放出 GitHub 项目,很可能我们会想到「是不是能在线发布我们的照片,然后 deepfake 之后就用不了了?」
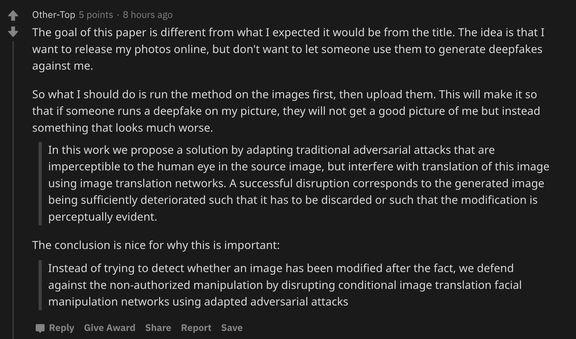
但事情肯定没我们想的那么简单,Reddit 用户 Other-Top 说:「按照这篇论文,我需要先利用该方法对照片进行处理,然后再上传照片,别人再用这张做换脸就会出错。」
也就是说,我们的照片、明星的照片先要用攻击模型过一遍,然后才能上传到网络上,这样的照片才是安全的?
听起来就比较麻烦,但我们还是可以先看看这篇论文的研究内容,说不定能想出更好的办法。在这篇论文中,研究者利用源图像中人眼无法感知的对抗攻击,借助对抗噪声干扰图像的生成结果。
这一破坏的结果是:所生成的图像将被充分劣化,要么使得该图像无法使用,要么使得该图像的变化明显可见。换而言之,不可见的噪声,令 deepfake 生成明显是假的视频。
论文地址:https://arxiv.org/abs/2003.01279
代码地址:https://github.com/natanielruiz/disrupting-deepfakes
对抗攻击,Deepfake 的克星
对抗攻击,常见于欺骗各种图像识别模型,虽然也能用于图像生成模型,但似乎意义不是那么大。不过如果能用在 deepfake 这类换脸模型,那就非常有前景了。
在这篇论文中,研究者正是沿着对抗攻击这条路「欺骗」deepfake 的换脸操作。具体而言,研究者首先提出并成功应用了:
可以泛化至不同类别的可迁移对抗攻击,这意味着攻击者不需要了解图像的类别;
用于生成对抗网络(GAN)的对抗性训练,这是实现鲁棒性图像转换网络的第一步;
在灰盒(gray-box)场景下,使输入图像变模糊可以成功地防御攻击,研究者展示了一个能够规避这种防御的攻击方法。
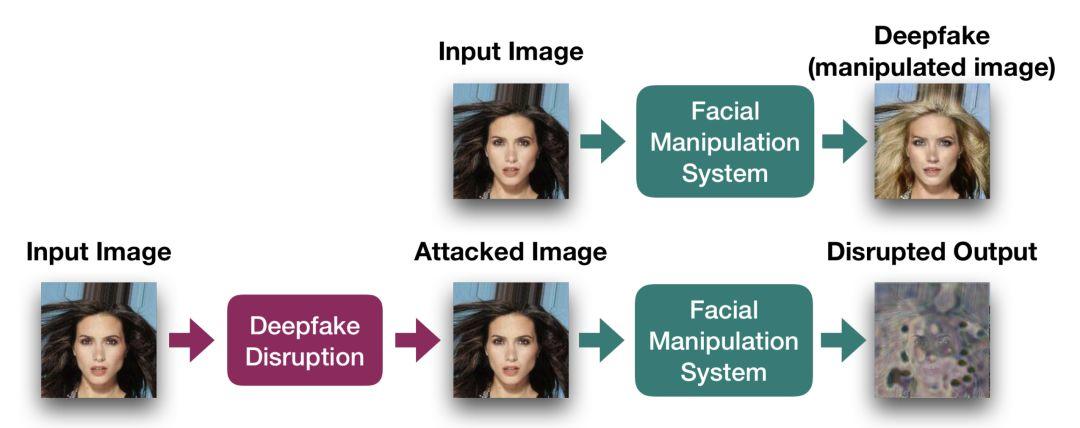
图 1:干扰 deepfake 生成的流程图。使用 I-FGSM 方法,在图像上应用一组无法觉察的噪声,之后就能成功地干扰人脸操纵系统(StarGAN)的输出结果。
大多数人脸操纵架构都是用输入图像和目标条件类别训练的,例如使用某些属性来定义生成人脸的目标表情(如给人脸添加微笑)。如果我们想要阻止他人为图像中的人脸添加微笑,则需要清楚选择的是微笑属性,而不是闭眼等其他不相关属性。
所以要靠对抗攻击欺骗 deepfake,首先需要梳理带条件的图像转换问题,这样才能将之前的攻击方法迁移到换脸上。研究者并提出了两种可迁移的干扰变体类别,从而提升对不同类别属性的泛化性。
在白盒测试场景下,给照片加模糊是一种决定性的防御方式,其中干扰者清楚预处理的模糊类型和大小。此外,在真实场景下,干扰者也许知道所使用的架构,但却忽略了模糊的类型和大小,此场景下的一般攻击方法的效果会显著降低。所以,研究者提出了一种新型 spread-spectrum disruption 方法,它能够规避灰盒测试场景下不同的模糊防御。
总的而言,尽管 deepfake 图像生成有很多独特的地方,但是经受过「传统图像识别」的对抗攻击,经过修改后就能高效地欺骗 deepfake 模型。
如何攻击 Deepfake
如果读者之前了解过对抗攻击,,那么这篇论文后面描述的方法将更容易理解。总的来说,对于如何攻击 deepfake 这类模型,研究者表示可以分为一般的图像转换修改(image translation disruption),他们新提出的条件图像修改、用于 GAN 的对抗训练技术和 spread spectrum disruption。
我们可以先看看攻击的效果,本来没修改的图像(没加对抗噪声)是可以完成换脸的。但是如果给它们加上对抗噪声,尽管人眼看不出输入图像有什么改变,不过模型已经无法根据这样的照片完成换脸了。

与对抗攻击相同,如果我们给图像加上一些人眼无法识别,但机器又非常敏感的噪声,那么依靠这样的图像,deepfakes 就会被攻击到。
目前比较流行的攻击方法主要是基于梯度和迭代的方法,其它很多优秀与先进的攻击方法都基于它们的主要思想。这一类方法的主要思想即希望找到能最大化损失函数变化的微小扰动,这样通过给原始输入加上这一微小扰动,模型就会误分类为其它类别。
通常简单的做法是沿反向传播计算损失函数对输入的导数,并根据该导数最大化损失函数,这样攻击者就能找到最优的扰动方向,并构造对抗样本欺骗该深度网络。
例如早年提出的 Fast Gradient Sign Method(FGSM),如果我们令 x 表示输入图像、G 为完成换脸的生成模型、L 为训练神经网络的损失函数,那么我们可以在当前权重值的邻域线性逼近损失函数,并获得令生成图像 G(x) 与原本换脸效果「r」差别最远的噪声η。
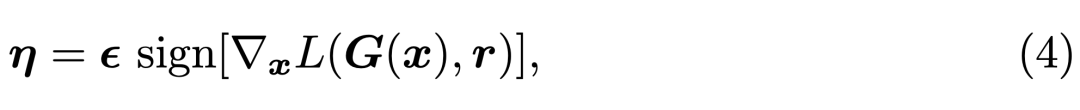
FGSM 能通过反向传播快速计算梯度,并找到令模型损失增加最多的微小扰动 η。其它如基本迭代方法(BIM)会使用较小的步长迭代多次 FGSM,从而获得效果更好的对抗样本。如下图所示将最优的扰动 η 加入原输入 x「人脸」,再用该「人脸」生成 deepfakes 就会存在问题。
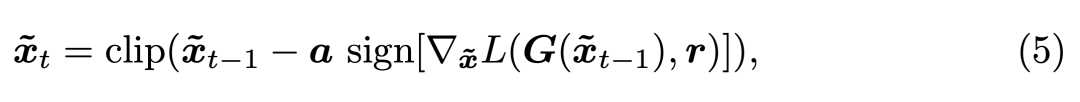
还有三种攻击法
上面只介绍了对抗攻击最为核心的思想,它在一定程度上确实能够欺骗 deepfakes,但是要想有好的效果,研究者在论文中提出了三种更完善的攻击方法。这里只简要介绍条件图像修改的思想,更多的细节可查阅原论文。
之前添加噪声是不带条件的,但很多换脸模型不仅会输入人脸,同时还会输入某个类别,这个类别就是条件。如下我们将条件 c 加入到了图像生成 G(x, c) 中,并希望获得令损失 L 最大,但又只需修改最小像素 η的情况。
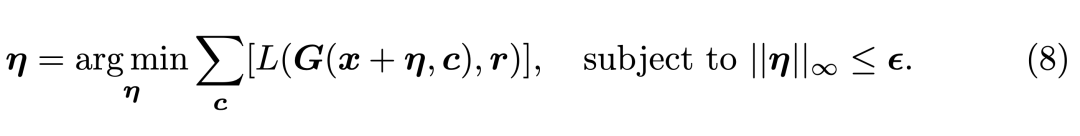
为了解决这一问题,研究者展示了一种新的攻击方法,它针对条件约束下的图像转换方法。这种方法能加强攻击模型迁移到各种类别的能力,例如类别是「笑脸」,那么将它输入攻击模型能更好地生成令 deepfakes 失效的人脸。
具体而言,研究者将 I-FGSM 修改为如下:
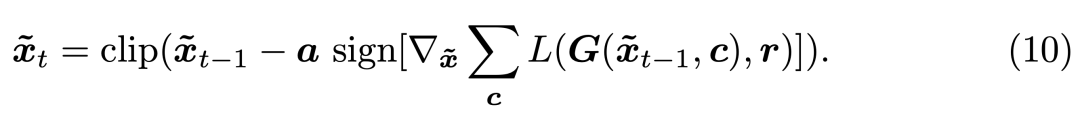
实验效果
实验表明,研究者提出的图像级 FGSM、 I-FGSM 和基于 PGD 的图像加噪方法能够成功地干扰 GANimation、StarGAN、pix2pixHD 和 CycleGAN 等不同的图像生成架构。
为了了解基于 L^2、L^1 度量图像「修改量」对图像转换效果的影响,在下图 3 中,研究者展示了干扰输出的定性示例以及它们各自的失真度量。

图 3:L_2 和 L_1 距离之间的等值规模(equivalence scale)以及 StarGAN 干扰图像上的定性失真。
对于文中提出的迭代类别可迁移干扰和联合类别可迁移干扰,研究者给出了下图 4 中的定性示例。这些干扰的目的是迁移至 GANimation 的所有动作单元输入。

图 4:研究者提出这种攻击换脸模型的效果。
如上图所示,a 为原始输入图像,它在不加入噪声下的 GANimation 生成结果为 b。如果以类别作为约束,使用正确类别后的攻击效果为 c,而没有使用正确类别的攻击效果为 d。后面 e 与 f 分别是研究者提出的迭代类别可迁移攻击效果、联合类别可迁移攻击效果,它们都可以跨各种类别攻击到 deepfakes 生成模型。
在灰盒测试的设置中,干扰者不知道用于预处理的模糊类型和大小,因此模糊是一种有效抵御对抗性破坏的方式。低幅度的模糊可以使得破坏失效,但同时可以保证图像转换输出的质量。下图 5 展示了在 StarGAN 结构中的示例。

图 5:高斯模糊防御的成功示例。
如果图像控制器使用模糊来阻挡对抗性干扰,对方可能不知道所使用模糊的类型和大小。下图 6 展示了该扩频方法在测试图像中成功实现干扰的比例。
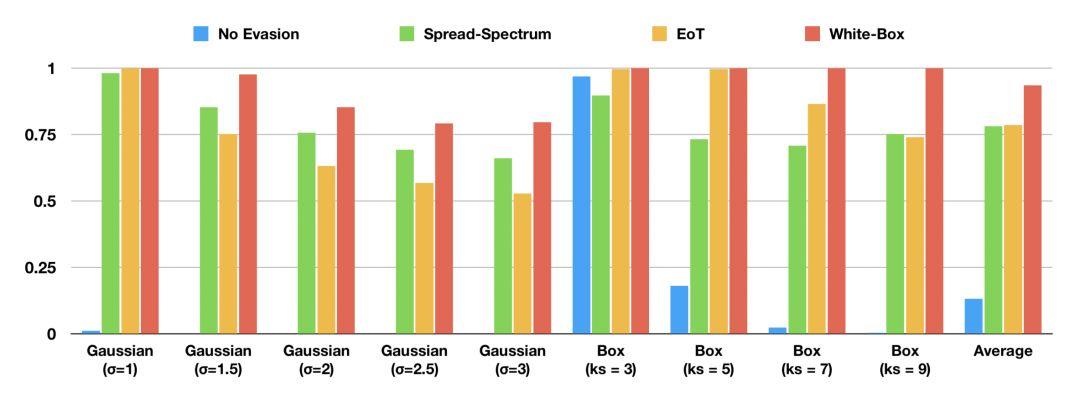
图 6:不同模糊防御下的不同模糊规避所造成的图像干扰比例 (L^2 ≥ 0.05)。

图 7:对于采用高斯模糊(σ = 1.5)的防御手段,spread-spectrum disruption 方法的效果。第一行展示了最初不针对模糊处理进行攻击的方法;第二行为 spread-spectrum disruption 方法方法,最后一行是 white-box 测试条件下的攻击效果。