本文探讨使用MySQL/MariaDB的Spider存储引擎通过使用单个表链接到多台服务器的实例。
Spider是MariaDB提供的一个新存储引擎,可以让一个标准配置的MariaDB成为一个分布式数据。
虽然实现起来还是会有点复杂,但技术并不太难。本文就来给各位介绍Spider存储引擎的工作与技术原理,并会提供一些实用案例。
MariaDB存储引擎
存储引擎是用于管理低级别数据访问的代码级别实现,它处理写入和读取数据,行锁定,多版本控制以及事务处理等。
从MySQL版本开始,存储引擎不断发展,由表的基础开始,定义一张表使用指定的存储引擎(ENGINE Table),创建后数据库管理系统开始处理,比如表之间的连接,从一张表中选择数据等。在MySQL和MariaDB中,创建完表后,仍然可以更改表的存储引擎。
高能Spider
Spider,一款名为蜘蛛的存储引擎,它提供的是从一台MariaDB服务器访问另一台MariaDB服务器的方法,保存实际表数据的MariaDB服务器可以没有任何Spider处理代码,一台普通的MySQL/MariaDB服务器即可。
可以在一台MariaDB上配置Spider,通过使用Spider存储引擎访问常规的MySQL API通信协议就可以正常访问另一台MariaDB上的数据。

上图中,我们看到,Spider仅在引用节点上安装激活,目标节点并不需要安装Spider。即创建一个Spider表,这意味着我们定义了一张表,这张表包括目标表中的相同一列或此列的子集以及引用的服务器。
安装Spider存储引擎
Spider已经包含在MariaDB服务器中,并提供了一个安装Spider的脚本,我们使用它来安装。
如果将MariaDB以RPM方式安装,Spider将安装在/usr/share/mysql中,脚本名字是install_spider.sql。我们使用MariaDB的命令行source执行即可:
$ mysql -u root
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 2835
Server version: 10.4.6-MariaDB-log MariaDB Server
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB> source /usr/share/mysql/install_spider.sql
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
脚本运行完成,使用SHOW ENGINES命令来查看所有安装的存储引擎:
MariaDB> SHOW ENGINES;
+--------------------+---------+-------------------------------------------------------------------------------------------------+--------------+------+------------+
| Engine | Support | Comment | Transactions | XA | Savepoints |
+--------------------+---------+-------------------------------------------------------------------------------------------------+--------------+------+------------+
| SPIDER | YES | Spider storage engine | YES | YES | NO |
| MRG_MyISAM | YES | Collection of identical MyISAM tables | NO | NO | NO |
| MEMORY | YES | Hash based, stored in memory, useful for temporary tables | NO | NO | NO |
| Aria | YES | Crash-safe tables with MyISAM heritage. Used for internal temporary tables and privilege tables | NO | NO | NO |
| MyISAM | YES | Non-transactional engine with good performance and small data footprint | NO | NO | NO |
| SEQUENCE | YES | Generated tables filled with sequential values | YES | NO | YES |
| InnoDB | DEFAULT | Supports transactions, row-level locking, foreign keys and encryption for tables | YES | YES | YES |
| PERFORMANCE_SCHEMA | YES | Performance Schema | NO | NO | NO |
| CSV | YES | Stores tables as CSV files | NO | NO | NO |
+--------------------+---------+-------------------------------------------------------------------------------------------------+--------------+------+------------+
9 rows in set (0.001 sec)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
可以看到Spider引擎已经就绪,已经可以开始使用。
Spider单表连接
来看一个基础的例子:在目标服务器上创建一张表。再次提示,目标服务器不需要Spider,仅访问远端数据的服务器是必需的。现在我们在目标服务器上创建一张新表,不妨称它为Sever2:
$ mysql -u root -S /tmp/mariadb2.sock -u root
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 11
Server version: 10.4.8-MariaDB MariaDB Server
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]> CREATE DATABASE spidertest;
Query OK, 1 row affected (0.001 sec)
MariaDB [(none)]> use spidertest;
Database changed
MariaDB [spidertest]> CREATE TABLE customer(
id INT NOT NULL PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(200) NOT NULL,
address VARCHAR(255) NOT NULL);
Query OK, 0 rows affected (0.539 sec)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
接下来向该表中插入一些测试数据:
MariaDB [spidertest]> INSERT INTO customer VALUES(NULL, 'John Doe', '1 Main Street');
Query OK, 1 row affected (0.309 sec)
MariaDB [spidertest]> INSERT INTO customer VALUES(NULL, 'Bob Smith', '45 Elm Street');
Query OK, 1 row affected (0.092 sec)
MariaDB [spidertest]> INSERT INTO customer VALUES(NULL, 'Jane Jones',
'18 Second Street');
Query OK, 1 row affected (0.094 sec)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
我承认这个不是玛丽.居里夫人发明镭一样的惊喜实验,但可以看到数据也已经成功插入到刚才的新表中。现在要做的事是从MariaDB服务器的另一个实例来访问该表。当Spider以普通用户身份连接到远程服务器,需要在同一台MariaDB Server上创建一个用户帐户,并为它授予创建数据表的权限。
MariaDB [spidertest]> CREATE USER 'spider'@'192.168.0.11' IDENTIFIED BY 'spider';
Query OK, 0 rows affected (0.236 sec)
MariaDB [spidertest]> GRANT ALL ON spidertest.* TO 'spider'@'192.168.0.11';
Query OK, 0 rows affected (0.238 sec)
MariaDB [spidertest]> GRANT ALL ON mysql.* TO 'spider'@'192.168.0.11';
Query OK, 0 rows affected (0.238 sec)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
下一步创建一个Server。如果之前你没有用过Spider,也不会用到这个命令,它是用来连接MariaDB Server实例以及相关参数,该服务器是在MariaDB Server实例上定义的。
下面是访问我们在上面创建的表(称为Server1)
$ mysql -u root -S /tmp/mariadb1.sock -u root
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 12
Server version: 10.4.8-MariaDB MariaDB Server
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [none]> CREATE SERVER Server2 FOREIGN DATA WRAPPER mysql
OPTIONS(HOST '192.168.0.11', DATABASE 'spidertest', PORT 10482,
USER 'spider', PASSWORD 'spider');
Query OK, 0 rows affected (0.233 sec)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
好的,下面就可以用Spider创建从Server1到Server2的链接了(我们也不必使用目标表中的所有字段)。
$ mysql -u root -S /tmp/mariadb1.sock -u root
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 33
Server version: 10.4.8-MariaDB MariaDB Server
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]> DROP DATABASE IF EXISTS spidertest;
Query OK, 0 rows affected, 1 warning (0.000 sec)
MariaDB [(none)]> CREATE DATABASE spidertest;
Query OK, 1 row affected (0.001 sec)
MariaDB [(none)]> use spidertest;
Database changed
MariaDB [spidertest]> CREATE TABLE customer(
id INT NOT NULL PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(200) NOT NULL) ENGINE=Spider
COMMENT = 'wrapper "mysql", srv "Server2"';
Query OK, 0 rows affected (0.132 sec)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
OK,没有出现任何错误。接着我们来用SELECT获取数据。
MariaDB [spidertest]> SELECT * FROM customer;
+----+------------+
| id | name |
+----+------------+
| 1 | John Doe |
| 2 | Bob Smith |
| 3 | Jane Jones |
+----+------------+
3 rows in set (0.006 sec)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
我们看到了,命令运行也已经成功。居里夫人鼓励我继续下一步,我们正在一步步接近目标。
用于单表链接
即使是单表链接,也有不少用途,比如上述表的链接。在某些情况下,它只是用来复制单张表,可以用它来替换复制。
比如你有一张表,它在维护着一个数据库实例,比如客户数据信息,你希望从另一个MariaDB Server中的应用程序可以引用该库的CustomerID。
这种配置存在一些缺点。比如,性能是一个大问题,对于使用Spider表的每个语句,都要建立与服务器的连接,本地表与Spider表之间的联接也可能很慢。总体来说,Spider存储引擎性能很出色,本身并不瓶颈,还存在很大的调整空间。
第三个选择是当我们只有一张表时,比如日志表,我并不想与任何其它表混在一起用。那么,Spider表是实现此目标的一种选择。
使用Spider在多台服务器上的状态
比如你运行的MariaDB集群是一个主数据库和多个辅助数据组成,我们可以将此集群的所有服务器视为一个单元。接着派Spider出场,在当前场景下,有两个要监视的服务器,一个叫moe,另一个叫homer,moe是主服务器,我们还希望在此中看到两个服务器的全局状态。
在homer服务器上,我们基于infomation_schema.GLOBAL STATUS创建一个视图,添加一个用来保存服务器名字的字段再保存到数据库中。如下:
CREATE OR REPLACE VIEW global_status_homer
AS SElECT 'homer' host, gs.variable_name, gs.variable_value
FROM information_schema.global_status gs;
- 1.
- 2.
- 3.
- 4.
- 5.
我们在moe服务器上做相同的事情:
CREATE OR REPLACE VIEW global_status_moe
AS SElECT 'moe' host, gs.variable_name, gs.variable_value
FROM information_schema.global_status gs;
- 1.
- 2.
- 3.
- 4.
- 5.
接下来,创建主服务器moe到另一台服务器homer的链接。在moe上我们创建如下命令:
CREATE OR REPLACE SERVER homer FOREIGN DATA WRAPPER mysql
OPTIONS(HOST '192.168.0.11', DATABASE 'mysql', PORT 10482, USER 'spider',
PASSWORD 'spider');
- 1.
- 2.
- 3.
- 4.
- 5.
如此就在moe上创建了一个新视图,用来查看homer服务器的状态。
CREATE OR REPLACE TABLE global_status_homer(host varchar(2048), variable_name VARCHAR(64), variable_value VARCHAR(64)) ENGINE=Spider COMMENT='wrapper "mysql", srv "homer"';
- 1.
在homer服务器上,现有一张表和一张视图。每台服务器都有一个视图,具有相似的架构,它们反映着整个集群的状态。接下来把两张表结合成一个视图。
CREATE OR REPLACE VIEW global_status_all AS
SELECT host, variable_name, variable_value
FROM global_status_homer
UNION
SELECT host, variable_name, variable_value
FROM global_status_moe;
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
然后,视图会显示整个集群的状态。
CREATE OR REPLACE VIEW global_status_total AS
SELECT variable_name, SUM(variable_value) sum, MAX(variable_value) max,
MIN(variable_value) min
FROM global_status_all
GROUP BY variable_name;
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
来测试下,它能不能正常工作:
MariaDB [mysql]> SELECT * FROM global_status_total WHERE variable_name LIKE 'open%';
+--------------------------+------+------+------+
| variable_name | sum | max | min |
+--------------------------+------+------+------+
| OPENED_FILES | 629 | 477 | 152 |
| OPENED_PLUGIN_LIBRARIES | 1 | 1 | 0 |
| OPENED_TABLES | 112 | 75 | 37 |
| OPENED_TABLE_DEFINITIONS | 125 | 95 | 30 |
| OPENED_VIEWS | 85 | 43 | 42 |
| OPEN_FILES | 132 | 76 | 56 |
| OPEN_STREAMS | 0 | 0 | 0 |
| OPEN_TABLES | 77 | 46 | 31 |
| OPEN_TABLE_DEFINITIONS | 83 | 49 | 34 |
+--------------------------+------+------+------+
9 rows in set (0.029 sec)
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
嗯,尽管这是一个简单实例,但它却很有用。如果服务器多于两台时,它会更有价值。
合并多个服务器表
在上面的例子中,我们研究了如何使用Spider表将具有相似内容和相同结构的表合并到一个视图中,这在实际场合中有价值的应用,比如有一个多实例的应用程序,如某个由多个部门使用的ERP应用,如果要从报表服务器做跨部门报告,则可以使用此模型访问该应用程序的全部实例。
Spider的替代解决方案是使用多源复制,但它需要在报表服务器中存储更多冗余的数据,这便是Spider解决方案的优势。
Spider分表
分片(也可称为分表)是Spider最常见的用例了。在前面我将一台服务器的表映射到另外一台服务器的表,也可以将Spider用于服务器上的分区表,每个分区都在单独的服务器上,除此之外在实践上并没有什么区别。
尽管Spider可以在分区用例上做更多有趣的事情,对于这些特定用例Spider还有一些性能增强能力。
来举一个简单的示例,我们来展示使用两个分片来设置分区,为了展示其原理,我们将使用customer表。在此实例中总共有三台服务器,两台“数据服务器”,其中包含两个分片数据和一台服务器,而“Spider”服务器中没有任何正在使用表的实际数据,而指向的是驻留在其它两以服务器上的数据。
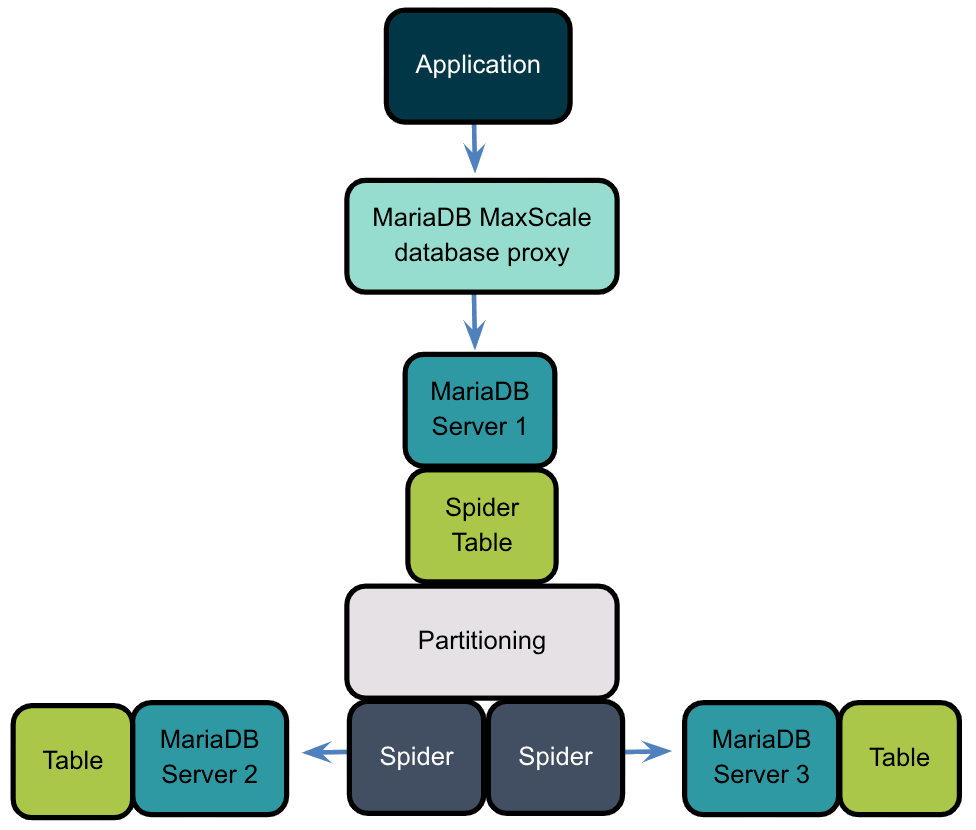
从最基础开始,先创建在MariaDB Server2和Server3中使用的表(与Customer表相似,但也不完全相同)。这两台服务器均以root用户身份运行。
CREATE DATABASE IF NOT EXISTS spidertest;
CREATE TABLE spidertest.customer(
id INT NOT NULL PRIMARY KEY,
name VARCHAR(200) NOT NULL,
address VARCHAR(255) NOT NULL);
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
现在已经创建两个分表,接着来创建链接,从MariaDB Server1来访问它们,我们在Server1上执行类似于以下SQL语句,里面的端口、主机名以及帐号根据情况可以自己更换。
CREATE OR REPLACE SERVER Server2 FOREIGN DATA WRAPPER mysql
OPTIONS(HOST '192.168.0.11', DATABASE 'spidertest', PORT 10482,
USER 'spider', PASSWORD 'spider');
CREATE OR REPLACE SERVER Server3 FOREIGN DATA WRAPPER mysql
OPTIONS(HOST '192.168.0.11', DATABASE 'spidertest', PORT 10483,
USER 'spider', PASSWORD 'spider');
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
接下来,我们将它和一个分区表绑定在一起,注意你可以在此使用任何合理的分区方案,我们只是选择一个简单的方案来说明这一点。
CREATE TABLE spidertest.customer(id INT NOT NULL PRIMARY KEY,
name VARCHAR(200) NOT NULL,
address VARCHAR(255) NOT NULL) ENGINE=Spider
COMMENT 'wrapper "mysql", table "customer"'
PARTITION BY RANGE(id) (
PARTITION p0 VALUES LESS THAN (1000) COMMENT = 'srv "Server2"',
PARTITION p1 VALUES LESS THAN (2000) COMMENT = 'srv "Server3
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
现在,我们在Server1上可以插入一些数据,并在Server2和Server3看到它们的显示。
INSERT INTO customer VALUES(1, 'Larry', 'Main Street 1');
INSERT INTO customer VALUES(2, 'Ed', 'Main Street 1');
INSERT INTO customer VALUES(3, 'Bob', 'Main Street 1');
INSERT INTO customer VALUES(1001, 'Monty', 'Main Street 1');
INSERT INTO customer VALUES(1002, 'David', 'Main Street 1');
INSERT INTO customer VALUES(1003, 'Allan', 'Main Street 1');
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
根据分区设置,1-3行将进入Server2,最后3行将进入Server3。我们会在本节完成之前提出来,分区分表是常见的MariaDB实景,没有Spider存储引擎,因此可以通过连接到Server2或Server3,逐个分表来访问。
用于Spider的分片
分片的明显优势是在处理大型数据集合时可以有效提高性能。除了以上功能外,Spider存储引擎还有其它优点,比如每个分片都可以单独访问普通的MariaDB Server,即可以按分片查看数据集,而不存在任何瓶颈,亦可以将其视为整体,同时使用Spider。
小结
本文介绍了Spider存储引擎的一些基本用法,这些用法对开发者都是很有用的,相关文档还可参考Spider的分片用例文档:https://mariadb.com/docs/usage/sharding/,你会发现前两种用法对于一些人会惊讶加启发。