













阿里妹导读:阿里云智能数据库Tair团队主要负责自研分布式键值存储(KVS)系统,几乎涵盖了淘宝、天猫、阿里妈妈、菜鸟、钉钉、优酷、高德等阿里巴巴所有核心业务。十多年来,始终如一为阿里业务提供着高可靠、高性能、低成本的数据存储与访问服务。
01 概 述
近日,Tair团队的一篇论文——HotRing: A Hotspot-Aware In-Memory Key-Value Store 被FAST'20 Research Track接收 (USENIX Conference on File and Storage Techniques (FAST),CCF A类会议,存储领域顶会,2020年接受率16%)。
HotRing是Tair团队的创新性纯内存KV存储引擎设计。其引擎吞吐性能可达600M ops/s,与目前最快的KVS系统相比,可实现2.58倍的性能提升。HotRing最重要的创新点是:极大的提升了KVS引擎对于热点访问的承载能力。这对于KVS系统的稳定性以及成本控制尤为关键。
为了方便大家更通俗全面的理解这篇论文,本文将从阿里巴巴的双十一零点峰值讲起,介绍峰值下数据库整体架构所面临的热点问题,再介绍Tair团队在解决热点方面一次次的优化提升,最后介绍Tair的创新性引擎HotRing。
02 背 景
零点峰值
2019年天猫双11再次刷新世界纪录,零点的订单峰值达到54.4万笔/秒。有订单就涉及到交易,有交易就需要数据库的事务保证,因此阿里巴巴数据库将在这时面临巨大的冲击。
现实往往更加严峻,在业务方面,一次订单随着业务逻辑在后端会放大为数十次的访问;在客户方面,大量的客户只是疯狂的访问,并没有生成订单。因此,在双11的零点峰值,业务实际的访问量级是10亿次/秒。
Tair作为高并发分布式的KVS系统,在这时发挥了重要作用。如下面的逻辑图所示,Tair作为数据库的分布式缓存系统,缓存了大量的热点数据(例如商品,库存,风控信息等),为数据库抵挡了巨大的访问量。2019年双11,Tair的峰值访问为9.92亿次/秒。
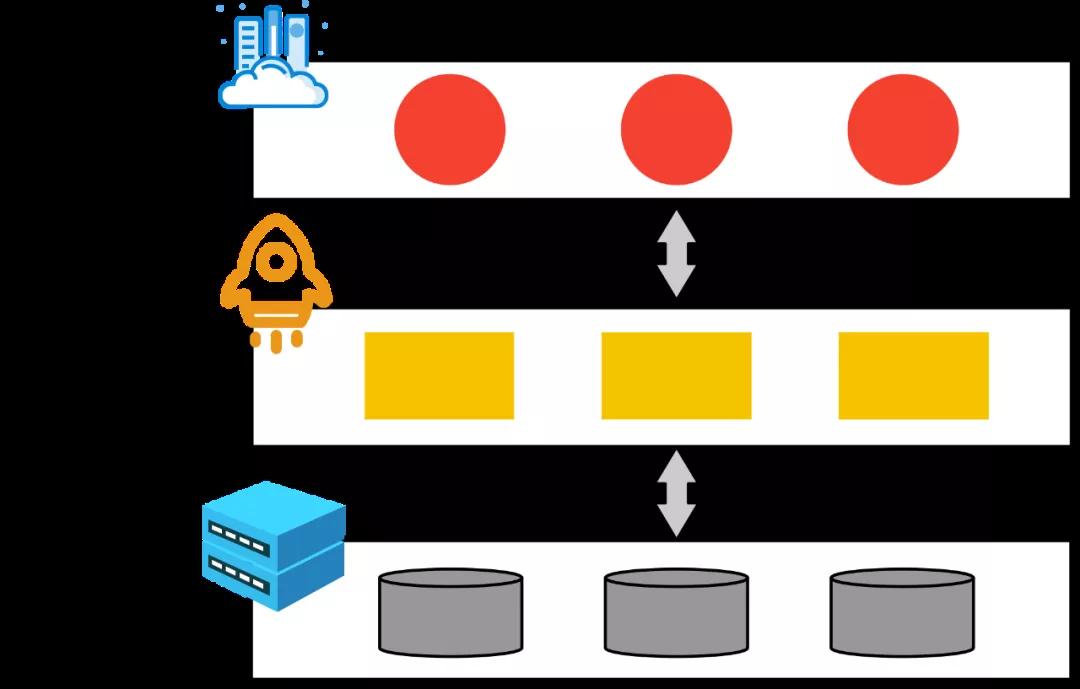
热点问题
在业务层面,热点问题很好理解,最典型的就是双十一零点秒杀。这会导致数据访问呈现严重倾斜的幂律分布。
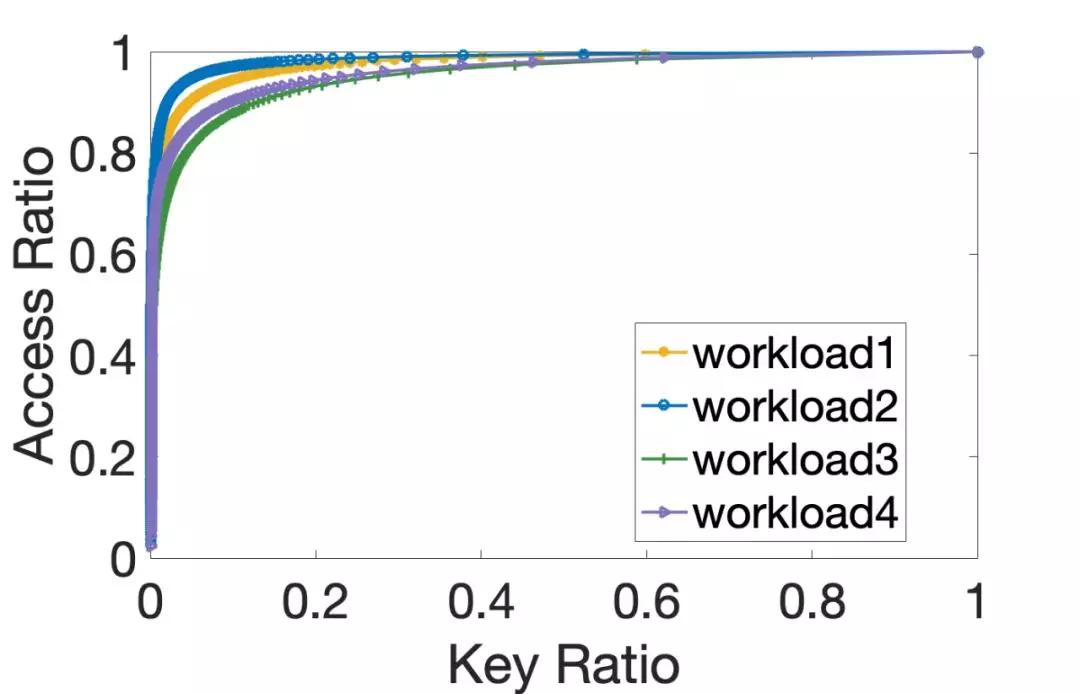
我们分析了多种业务的数据访问分布,如下图所示,大量的数据访问只集中在少部分的热点数据中,若用离散幂率分布(Zipfian)刻画,其θ参数约为1.22。相似地,Facebook的一篇论文同样也展示了近似的数据访问分布(参考论文[3])。
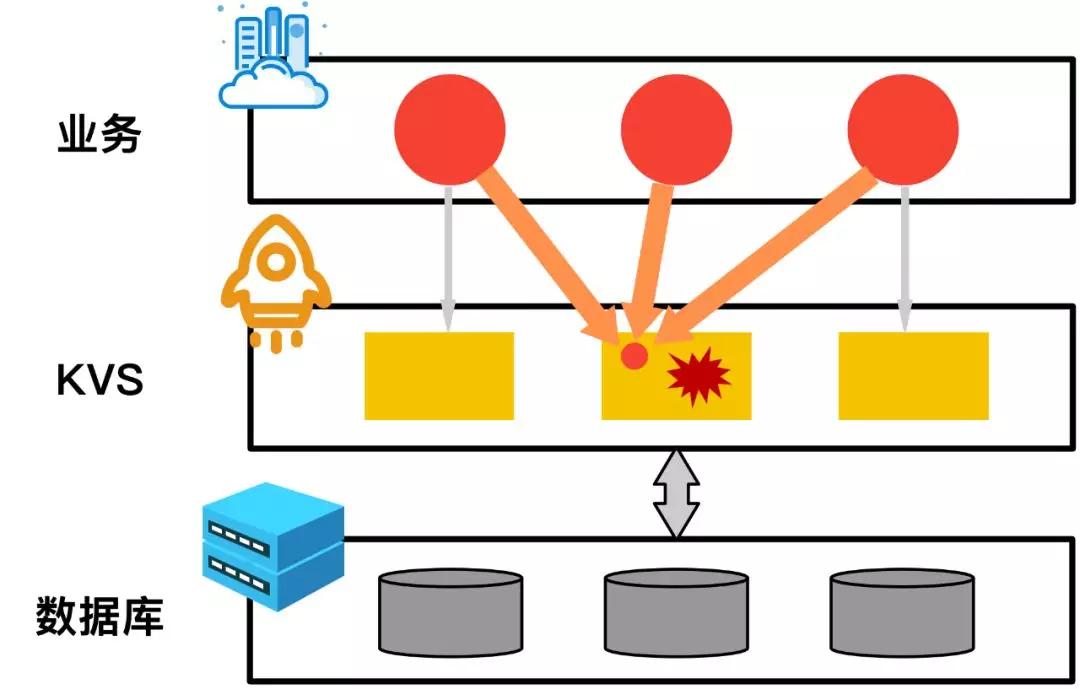
直观上可以用下图来解释。以苹果新手机发售举例。手机的库存等信息只存在KVS的一个节点中。当新手机发售后,大量的果粉疯狂进行抢购下单,业务的访问量基本都聚集在这一个节点上。节点可能无法承载大量的热点访问,进而引发系统崩溃,严重影响用户体验。
热点优化
为了保证双十一丝般顺滑的购物体验,Tair针对热点问题进行了多层优化:
- 客户端缓存:通过预先标记热点,设置客户端层面的缓存。以上图来理解,就是将访问在业务层面返回,直接减小了KVS系统的负载压力。
- 热点散列技术:通过将热点数据备份到多个KVS节点上,分摊热点访问。以少量成本的资源与系统开销,换取了成倍的系统承载力。
- RCU无锁引擎:通过采用Read-Copy-Update的方式,实现内存KV引擎的无锁化(lock-free)访问(参考论文[1,2])。成倍提升KVS引擎的性能,进而提高热点的承载力。
- HotRing:在RCU无锁引擎基础上,我们进行索引结构的热点感知设计,提出了一种名为HotRing的新型热点感知内存KVS。HotRing可动态识别热点,并实时的进行索引结构的无锁调整,对于幂律分布场景实现成倍的引擎性能提升。
经过十年的技术沉淀,我们已将集团Tair数据库的缓存技术释放到云上,普惠大众,即“阿里云Redis企业版”。
03 HotRing
现有技术
现有的内存KVS引擎通常采用链式哈希作为索引,结构如下图所示。首先,根据数据的键值(k)计算其哈希值h(k),对应到哈希表(Hash table)的某个头指针(Headi)。根据头指针遍历相应的冲突链(Collision Chain)的所有数据(Item),通过键值比较,找到目标数据。如果目标数据不在冲突链中(read miss),则可在冲突链头部插入该数据。
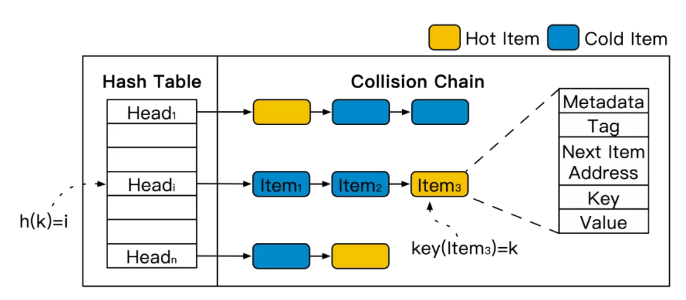

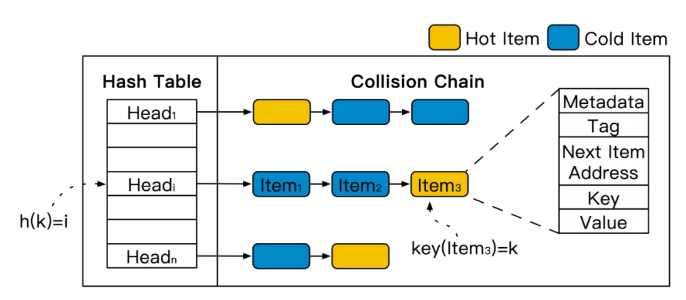
在链式哈希索引结构中,访问位于冲突链尾部的数据,需要经过更多的索引跳数,即更多次的内存访问。很直观的想法是,如果可以将热点数据放置在冲突链头部,那么系统对于热点数据的访问将会有更快的响应速度。
但是,数据在冲突链中的位置由数据的插入顺序决定,这和数据的冷热程度是互相独立的。因此,如图所示,热点数据(Hot Item)在冲突链中的位置是完全均匀分布。
设计挑战
理想的设计也很直观,就是将所有热点数据移动到冲突链的头部。但有两方面因素使得这个问题非常难解。一方面,数据的热度是动态变化的,必须实现动态的热点感知保证热点时效性。另一方面,内存KVS的引擎性能是很敏感的(一次访问的时延通常是100ns量级),必须实现无锁的热点感知维持引擎的高并发与高吞吐特性。
HotRing整体设计
HotRing在传统链式哈希索引基础上,实现了有序环式哈希索引设计。如下图所示,将冲突链首尾连接形式冲突环,保证头指针指向任何一个item都可以遍历环上所有数据。然后,HotRing通过lock-free移动头指针,动态指向热度较高的item(或根据算法计算出的最优item位置),使得访问热点数据可以更快的返回。
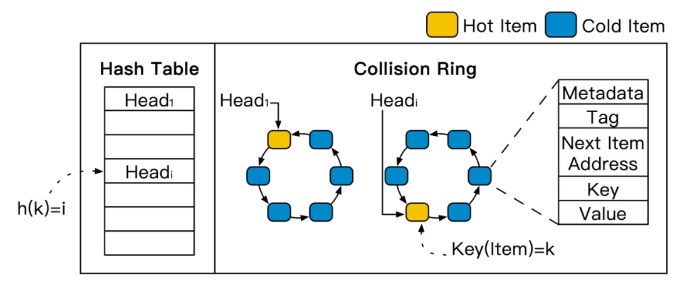
下面通过如下4方面进行介绍:
- 设计1:为什么要实现为有序环?
- 设计2:如何动态识别热点并调整头指针?
- 设计3:如何保证无锁的并发访问?
- 设计4:如何根据热点数据量的动态变化进行无锁rehash?
设计1——有序环
实现环式哈希索引后,第一个问题是要保证查询的正确性。若为无序环,当一个read miss操作遍历冲突环时,它需要一个标志来判断遍历何时终止,否则会形式死循环。但是在环上,所有数据都会动态变化(更新或删除),头指针同样也会动态移动,没有标志可以作为遍历的终止判断。
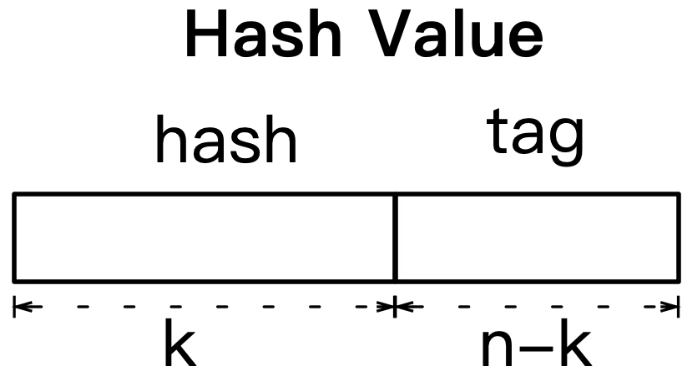
利用key排序可以解决这个问题,若目标key介于连续两个item的key之间,说明为read miss操作,即可终止返回。由于实际系统中,数据key的大小通常为10~100B,比较会带来巨大的开销。哈希结构利用tag来减少key的比较开销。
如下图所示,tag是哈希值的一部分,每个key计算的哈希值,前k位用来哈希表的定位,后n-k位作为冲突链中进一步区分key的标志。为了减小排序开销,我们构建字典序:order = (tag, key)。先根据tag进行排序,tag相同再根据key进行排序。
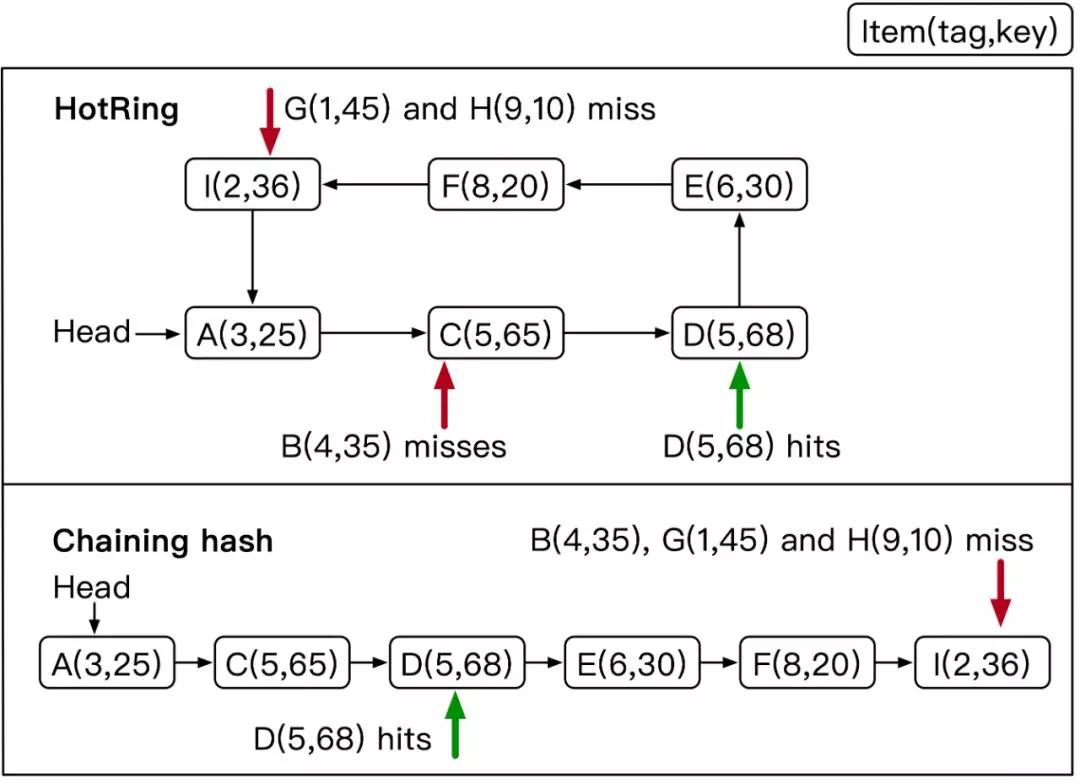
下图比较了HotRing与传统链式哈希。以itemB举例,链式哈希需要遍历所有数据才能返回read miss。而HotRing在访问itemA与C后,即可确认B read miss。因此针对read miss操作,链式哈希需要遍历整个冲突链;而HotRing利用字典序,不仅可以正确终止,且平均只需遍历1/2冲突环。
设计2——动态识别与调整
HotRing实现了两种策略来实现周期性的热点识别与调整。每R次访问为一个周期(R通常设置为5),第R次访问的线程将进行头指针的调整。两种策略如下:
- 随机移动策略:每R次访问,移动头指针指向第R次访问的item。若已经指向该item,则头指针不移动。该策略的优势是, 不需要额外的元数据开销,且不需要采样过程,响应速度极快。
- 采样分析策略:每R次访问,尝试启动对应冲突环的采样,统计item的访问频率。若第R次访问的item已经是头指针指向的item,则不启动采样。
采样所需的元数据结构如下图所示,分别在头指针处设置Total Counter,记录该环的访问总次数,每个item设置Counter记录该item的访问次数。因为内存指针需要分配64bits,但实际系统地址索引只使用其中的48bits。我们使用剩余16bits设置标志位(例如Total Counter、Counter等),保证不会增加额外的元数据开销。该策略的优势是,通过采样分析,可以计算选出最优的头指针位置,稳态时性能表现更优。
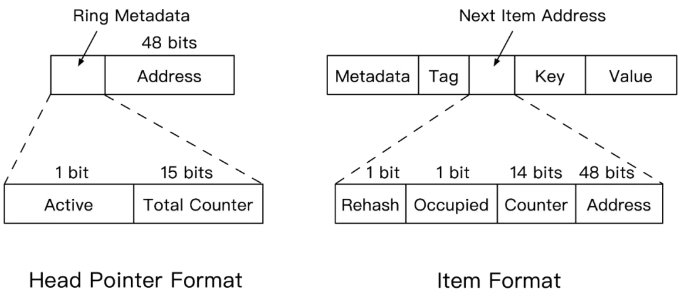
这一部分的细节设计有很多:
- 采样分析策略如何选出最优位置;
- 针对RCU更新操作的采样优化,
- 热点继承防止冷启动。
本文不再详细描述,有兴趣请参考HotRing论文。
设计3——无锁并发访问
Tair的RCU无锁引擎是HotRing的设计基础。参考论文[1,2]对如何实现无锁链表进行了详细讲解,后续的所有无锁设计基本都沿用了他们的策略。有兴趣可以读一下。这里我们举一个典型的并发示例进行介绍。
如下图所示,在链A->B->D上,线程1进行插入C的操作,同时线程2进行RCU更新B的操作,尝试更新为B'。线程1修改B的指针指向C,完成插入。而线程2修改A的指针指向B'完成更新。两个线程并发修改不同的内存,均可成功返回。但是这时遍历整条链(A->B'->D),将发现C无法被遍历到,导致正确性问题。
解决措施是利用上图(Item Format)中的Occupied标志位。当线程2更新B时,首先需要将B的Occupied标志位置位。线程1插入C需要修改B的指针(Next Item Address),若发现Occupied标志位已置位,则需要重新遍历链表,尝试插入。通过使并发操作竞争修改同一内存地址,保证并发操作的正确性。
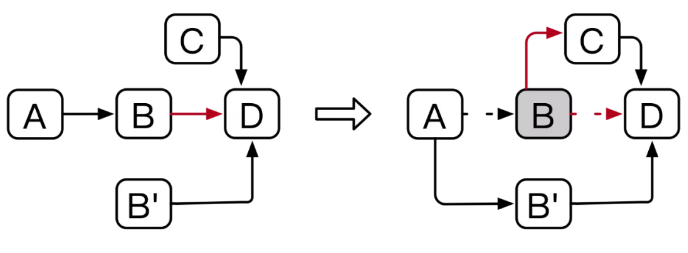
利用相同原理,我们保证了头指针移动操作,与CRUD操作的并发正确性。因此实现了HotRing的无锁并发访问。
设计4——适应热点数据量的无锁rehash
如背景所述,对于极端的幂率分布场景,大量的数据访问只集中在少部分的热点数据中。因此只要保证热点数据可以位于头指针位置,冲突环即使很长,对于引擎的性能表现并不影响。引擎性能的降低,必然是因为冲突环上存在多个热点。因此HotRing设计了适应热点数据量的无锁rehash策略来解决这一问题。
HotRing利用访问所需平均内存访问次数(access overhead)来替代传统rehash策略的负载因子(load factor)。在幂率分布场景,若每个冲突环只有一个热点,HotRing可以保证access overhead < 2,即平均每次访问所需内存访问次数小于2。因此设定access overhead阈值为2,当大于2时,触发rehash。
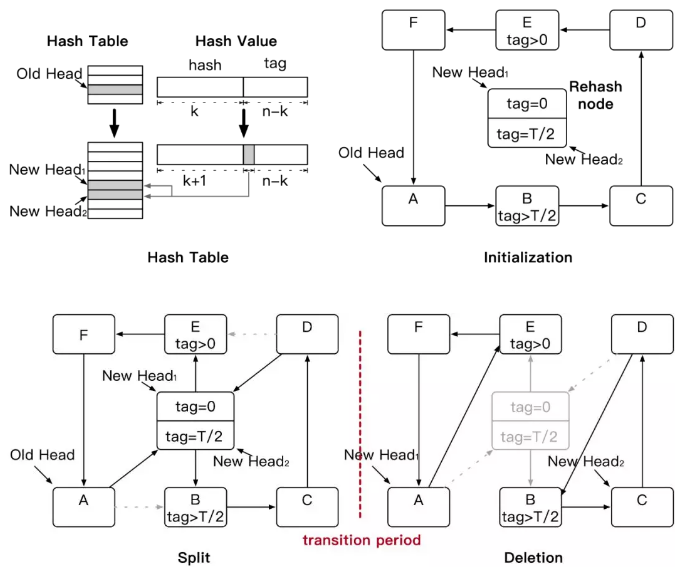
rehash过程分为3步进行,结合上面4图进行说明,图一为哈希表,哈希值在rehash前后的变化。剩余三图为rehash三个过程。
初始化(Initialization):首先,HotRing创建一个后台rehash线程。该线程创建2倍空间的新哈希表,通过复用tag的最高一位来进行索引。因此,新表中将会有两个头指针与旧表中的一个头指针对应。HotRing根据tag范围对数据进行划分。假设tag最大值为T,tag范围为[0,T),则两个新的头指针对应tag范围为[0,T/2)和[T/2,T)。同时,rahash线程创建一个rehash节点(包含两个空数据的子item节点),子item节点分别对应两个新头指针。HotRing利用item中的Rehash标志位识别rehash节点的子item节点。
分裂(Split):在分裂阶段,rehash线程通过将rehash节点的两个子item节点插入环中完成环的分裂。如图(Split)所示,因为itemB和E是tag的范围边界,所以子item节点分别插入到itemB和E之前。完成两个插入操作后,新哈希表将激活,所有的访问都将通过新哈希表进行访问。到目前为止,已经在逻辑上将冲突环一分为二。当我们查找数据时,最多只需要扫描一半的item。
删除(Deletion):删除阶段需要做一些首尾工作,包括旧哈希表的回收。以及rehash节点的删除回收。这里需要强调,分裂阶段和删除阶段间,必须有一个RCU静默期(transition period)。该静默期保证所有从旧哈希表进入的访问均已经返回。否则,直接回收旧哈希表可能导致并发错误。
04 总 结
内存键值存储系统由于高性能、易扩展等特性在云存储服务中广泛使用。其通常作为必不可少的缓存组件,以解决持久化存储系统或分布式存储系统中的热点问题。
但分析发现,内存KVS内部的热点问题更加严重,其数据访问分布同样服从幂律分布,且访问倾斜愈加严重。现有的内存KVS缺乏热点优化意识,部分数据节点可能无法承载大量的热点访问,进而引发系统崩溃,严重影响用户体验。
在本论文中,我们进行索引结构的热点感知设计,提出了一种名为HotRing的新型热点感知内存KVS,针对幂率分布的热点场景进行大量优化。HotRing可动态识别热点,并实时的进行索引结构的无锁调整,进而提供高并发高性能的无锁化访问。
与传统的内存KVS索引相比,HotRing采用轻量级的热点识别策略,且没有增加元数据存储开销。但在幂律分布的应用场景中,HotRing的引擎吞吐性能可达600M ops/s,与目前最快KVS相比,可实现2.58倍的性能提升。
参考
[1] John D Valois. Lock-free linked lists using compare-and-swap. (PODC 1995)
[2] Timothy L Harris. A Pragmatic Implementation of Non-blocking Linked-lists. (DISC 2001)
[3] Berk Atikoglu. Workload Analysis of a Large- Scale Key-Value Store. (SIGMETRICS 2012)


















