本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
在2D图像中做3D目标检测很难?
现在,拿着一部手机就能做到,还是实时的那种。
这就是谷歌AI今天发布的MediaPipe Objectron,一个可以实时3D目标检测的pipeline。
分开来看:
MediaPipe是一个开源的跨平台框架,用于构建pipeline来处理不同模式的感知数据。
Objectron在移动设备上实时计算面向对象的3D边界框。
日常生活中的物体,它都可以检测,来看下效果。
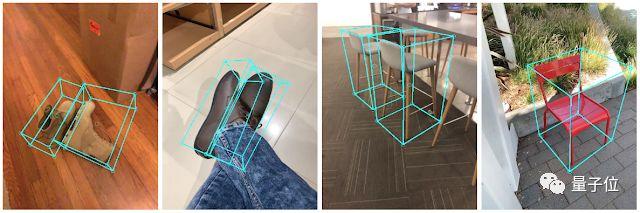
它可以在移动端设备上,实时地确定物体的位置、方向和大小。

这个pipeline检测2D图像中的物体,然后通过机器学习模型,来估计它的姿态和大小。
那么,它具体是怎么做到的呢?
获取真实世界中的3D数据
我们知道,3D数据集相对于2D来说,非常有限。
为了解决这个问题,谷歌AI的研究人员使用移动增强现实(AR)会话数据(session data),开发了新的数据pipeline。
目前来说,大部分智能手机现在都具备了增强现实的功能,在这个过程中捕捉额外的信息,包括相机姿态、稀疏的3D点云、估计的光照和平面。
为了标记groud truth数据,研究人员构建了一个新的注释工具,并将它和AR会话数据拿来一起使用,能让注释器快速地标记对象的3D边界框。
这个工具使用分屏视图来显示2D视频帧,例如下图所示。
左边是覆盖的3D边界框,右边显示的是3D点云、摄像机位置和检测平面的视图。
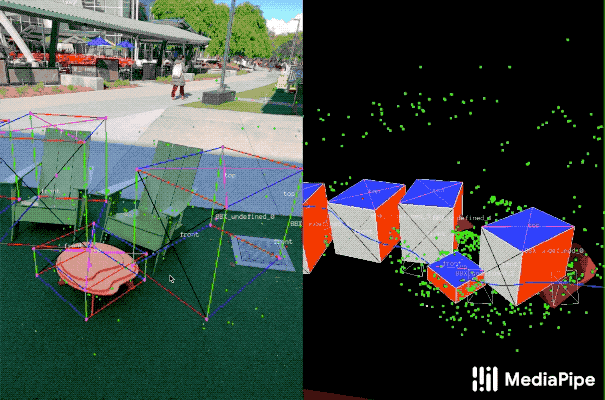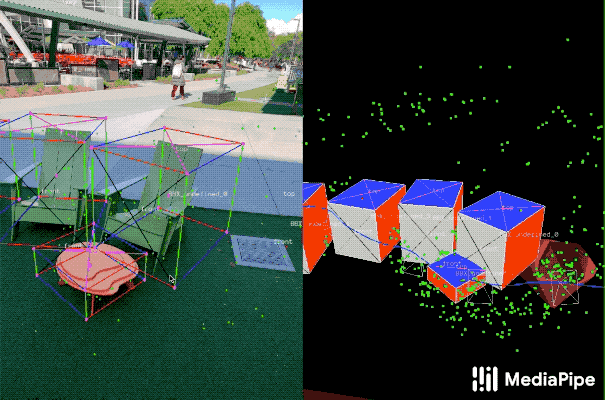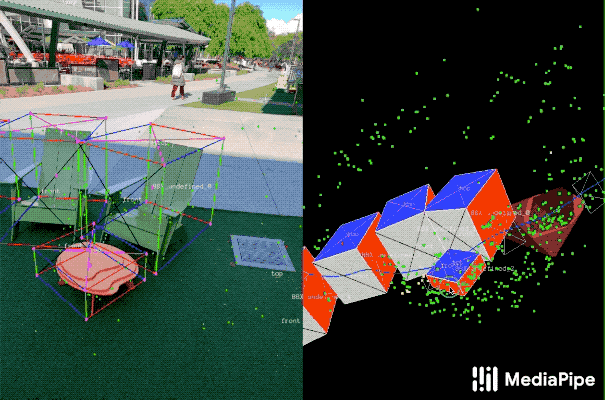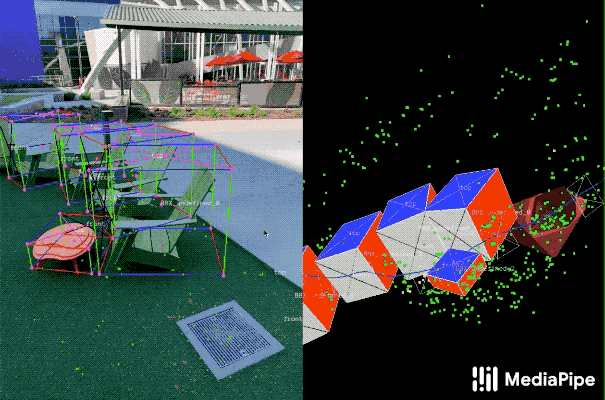
注释器在3D视图中绘制3D边界框,并通过查看2D视频帧中的投影来验证其位置。
对于静态对象,只需要在单帧中注释一个对象,并使用来自AR会话数据的ground truth摄像机位姿信息,将它的位置传播到所有帧。
这就让该过程变得非常高效。
AR合成数据生成
为了提高预测的准确性,现在比较流行的一种方法,就是通过合成的3D数据,来“填充”真实世界的数据。
但这样往往就会产生很不真实的数据,甚至还需要大量的计算工作。
谷歌AI就提出了一种新的方法——AR合成数据生成 (AR Synthetic Data Generation)。
这就允许研究人员可以利用相机的姿势、检测到的平面、估计的照明,来生成物理上可能的位置以及具有与场景匹配的照明位置 。
这种方法产生了高质量的合成数据,与真实数据一起使用,能够将准确率提高约10%。

用于3D目标检测的机器学习pipeline
为了达到这个目的,研究人员建立了一个单阶段的模型,从一个RGB图像预测一个物体的姿态和物理大小。
模型主干部分有一个基于MobileNetv2的编码器-解码器架构。
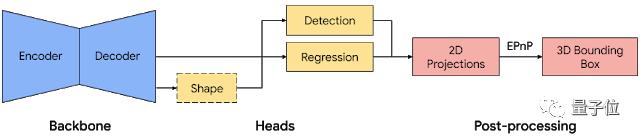
还采用一种多任务学习方法,通过检测和回归来共同预测物体的形状。
对于形状任务,根据可用的ground truth注释(如分割)来预测对象的形状信号;对于检测任务,使用带注释的边界框,并将高斯分布拟合到框中,以框形质心为中心,并与框的大小成比例的标准差。
检测的目标是预测这个分布,它的峰值代表了目标的中心位置。
回归任务估计边界框8个顶点的2D投影。为了获得边界框的最终3D坐标,还利用了一个成熟的姿态估计算法(EPnP),可以在不知道物体尺寸的前提下恢复物体的3D边界框。
有了3D边界框,就可以很容易地计算出物体的姿态和大小。

这个模型也是非常的轻量级,可以在移动设备上实时运行。
在MediaPipe中进行检测和跟踪
在移动端设备使用这个模型的时候,由于每一帧中3D边界框的模糊性,模型可能会发生“抖动”。
为了缓解这种情况,研究人员采用了最近在“2D界”发布的检测+跟踪框架。
这个框架减少了在每一帧上运行网络的需要,允许使用更大、更精确的模型,还能保持在pipeline上的实时性。
为了进一步提高移动pipeline的效率,每隔几帧只让运行一次模型推断。

最后,这么好的项目,当然已经开源了!
戳下方传送门链接,快去试试吧~
传送门
GitHub项目地址:
https://github.com/google/mediapipe/blob/master/mediapipe/docs/objectron_mobile_gpu.md
谷歌AI博客:
https://ai.googleblog.com/2020/03/real-time-3d-object-detection-on-mobile.html