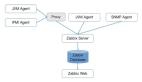
一、 导语
我们知道监控系统的目标是:为保障业务 SLA,帮忙我们更全面、细致的了解业务系统的运行状态,更及时的发现系统风险,同时给技术运营的同学争取更多化解风险的时间和解决问题的方向。
为此有使用开源监控系统(例如 Nagios、Zabbix、Prometheus、Grafana等),也有为了满足自己的业务需求,会使用自己开发的监控系统(例如小米的open falcon,腾讯内部的监控系统 tnm2【基础监控】、cms【日志监控】等)。
随着业务系统对监控系统的依赖,我们对监控系统的高可用性、扩展性等能力都会有更高的要求,那我们应该如何来全面的、系统的看待和提高自身监控系统的要求呢?
二、 能力提升方法
如何进行全面、系统的进行看待监控系统的要求,有很多办法,遇到问题的时候对照一些顶级公司的优秀监控系统,找出提升点。
也可以对照由 中国信息通信研究院牵头 及 BATJ 等各大互联网巨头参与的专家《研发运营一体化(DevOps)能力成熟度模型》中关于 “监控管理” 能力评估内容,根据标准的评估内容我们可以看到 BATJ 公司是如何定义一个先进的监控系统的能力,下面我们来一起看看:
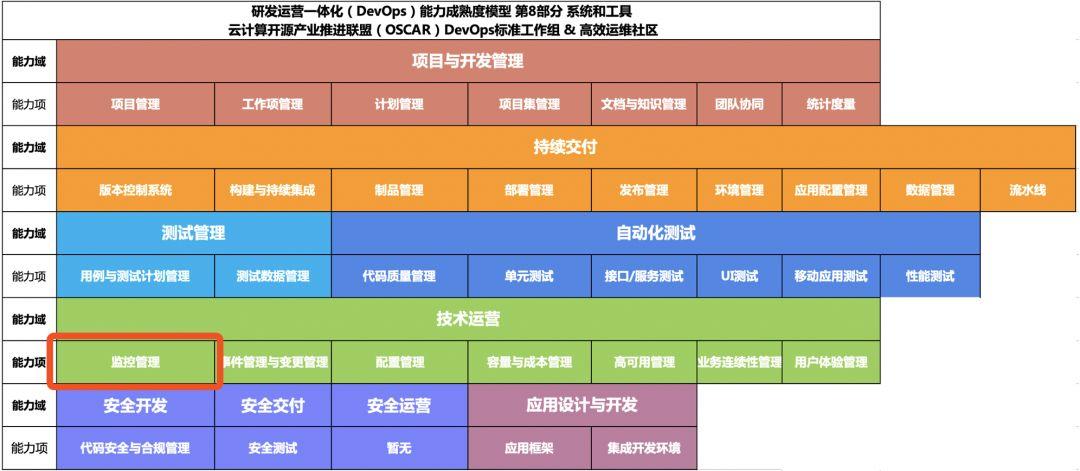
三、 提升点:能力项
我们发现整个关于“监控管理”的能力项分成三个能力项,分别是“监控采集”、“数据管理” 和 “数据应用” 三个,能力项内又包括了相关的子能力项,我摘取一些我自己觉得很有代表性的点来进行分析:
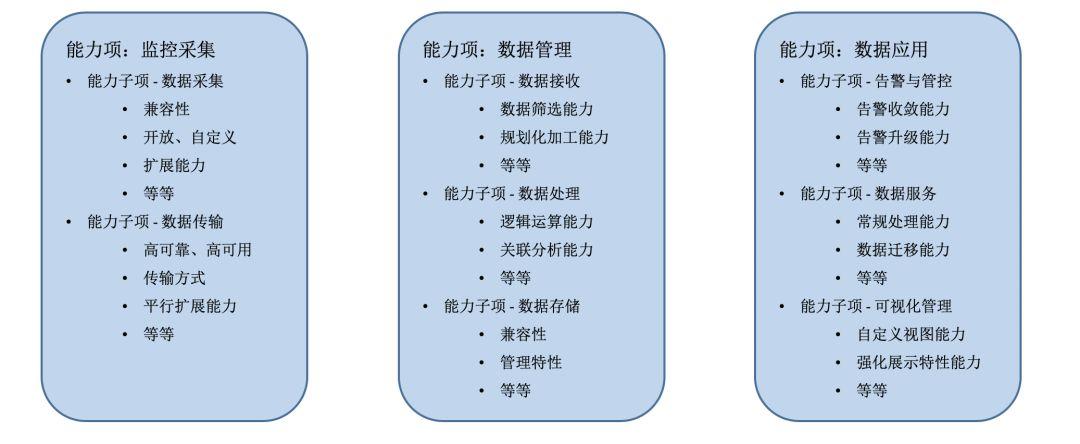
a)【能力项1:监控采集】
1.能力点:“支持提供开放式、自定义的数据内容采集上报方案”
疑问:为什么需要对上报方案有要求呢?
解读:比如腾讯内部的自研日志监控系统CMS,对拥有多种采集方案“Agent、SDK、Kafka、ES等”,各种不同的采集方案应对不同的场景
Agent:类似filebeat,指定服务器的具体路径,对文件的inode节点进行侦听,发现新增立即进行上报数据;
SDK:可以嵌入到业务代码逻辑里面,应对一些敏感数据不落地但是又需要上报的场景,可以在业务逻辑中对敏感数据进行脱敏(染色),然后再进行上报,也可以应对一些日志量太大,不想经过日志落盘这个中间消耗性能环节的场景;
例如:金融交易场景,要对交易数据做监控,但是又有一些敏感数据不想进入监控系统,这个时候就需要使用SDK在产生日志的时候进行脱敏,将用户信息隐藏掉,再上报到监控系统内部;
Kafka:可以应对一份日志多份消费者的场景,可以让业务将日志放入Kafka后,多个消费者进行自行提取即可;
例如:还是金融交易场景,一份日志可以做安全审计,同时也可以做监控系统,这时候就可以安全审计系统和监控系统同时拉取一份Kafka的主题数据,不用打印多份;
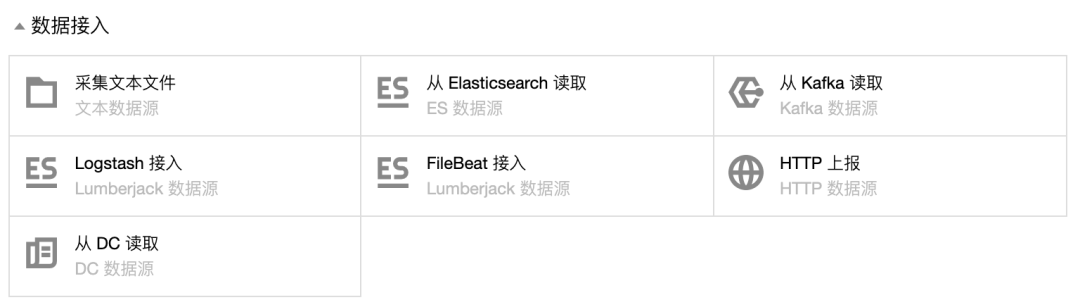
2.能力点:“支持多种传输方案 ,如同时具备推与拉数据”
疑问:为什么需要具备推与拉数据呢?具备一种不可以吗?
解读:正常的监控系统一般都是采用拉数据的方案,因为由服务器端发起,顺序和过程可控,但是为什么需要拉数据呢?
原因是在几种场景下需要这种能力:网络限制,当出现网络限制时,如安全等保中规定,高安全等级区域可以发起对低安全等级区域的链接,反之则不可以,所以需要从高安全等级区域推送数据至监控服务;性能要求,如同 Zabbix 的 active模式 和 passive模式;服务特性,部分服务并么有对外提供请求接口,则需要内部逻辑对外进行主动 Push 监控数据。为了保证对业务系统和流程全面的监控,我们需要有多种能力的满足;
例如:某个业务中有个定时任务将离线数据统计并更新至数据库,该定时任务并无任何请求访问接口,我们如何能监控它的运行状态呢?可以在定时任务逻辑内部加入一个心跳机制,定期向监控系统push自身的监控状况,所以推的传输能力也是监控必不可少的;
b)【能力项2:数据管理】
1.能力点:“具备对原始数据进行规则化处理的能力”
疑问:为什么在接收数据的时候需要有规则化的处理呢,落地之后进行规则化处理不行吗?
解读:基于性能高效及数据完整性的考虑,需要在接收过程具备这个能力,我们还是以腾讯自研日志监控系统为例,当我们接收大量的日志Agent上报的时候,可能日志不一定是按照我们的规则进行上报,如果一旦有日志格式错误,会导致大量的入库数据异常,还会导致数据污染,这个时候需要一个规则化处理的能力,将不满足规则的数据进行清洗。同时如果大量的日志异常,落地之后进行清洗和处理将会消耗大量的算力,对于后来也是很大的压力,所以具备这个能力是非常有必要的。
2.能力点:“对异构数据源的关联分析处理能力”
疑问:异构数据源关联分析处理能力具体是指什么?
解读:异构数据源广义上是指“数据结构、存取方式、形式不一样的多个数据源”,我们还是以腾讯内部的 自研日志监控系统CMS 为例,当 某个服务上报日志里面有 源IP地址 和 业务关键数据,我们简单排重和排序就可以知道哪个源IP地址访问最多,但是如果我们想知道某个城市、省份、甚至是运营商(电信、移动、联通),那就需要这个关联分析能力,我们知道有一种数据是IP地址对应城市、省份 和 运营商(由于不断在更新,所以需要独立维护),通过这个数据和日志数据一关联就可以清楚地看到我们要的结果;
3.能力点:“具备数据一致性、完整性和可用性等管理特性”
疑问:数据一致性、完整性和可用性好理解,但是管理特性是什么?
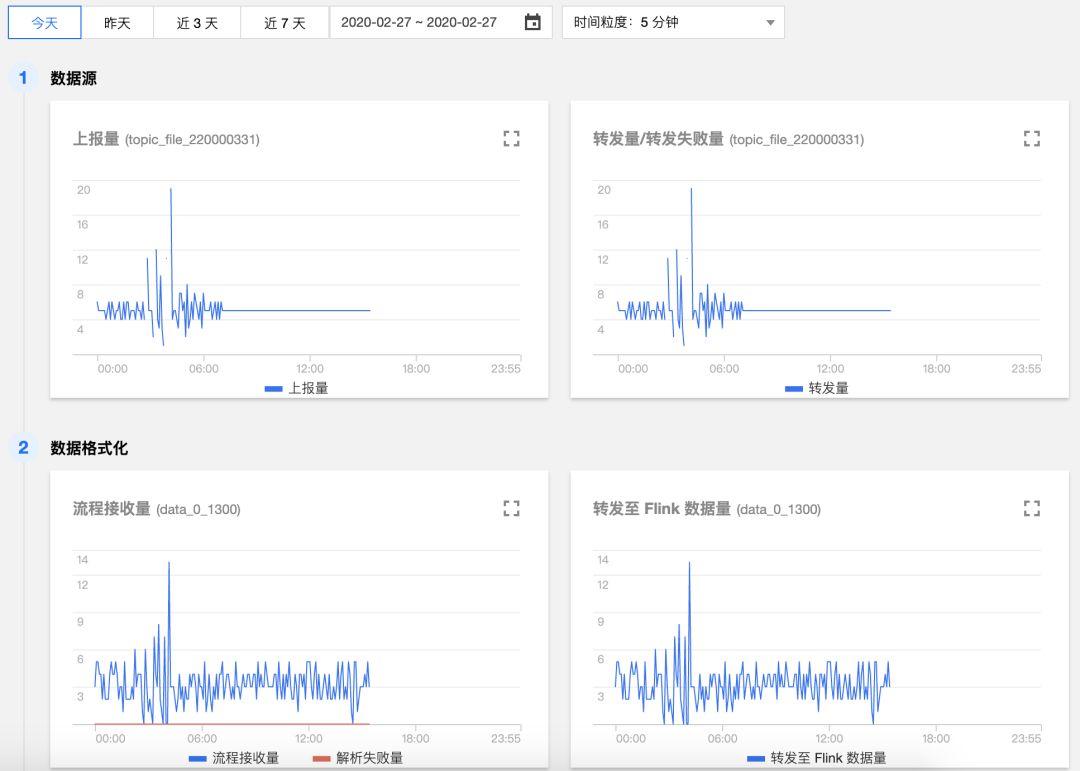
解读:我们还是以腾讯内部的 自研日志监控系统CMS 为例,日志监控系统是由用户数据上报、数据格式化、处理、聚合(统计、维度分析)、入库/投递、写入时序数据库等多个环节组成,当用户看到最终结果异常如何能快速知道哪里出了问题呢?这个就需要有相关的管理特性来实现了,在每个环节都增加自监控的能力,清晰看到数据流和曲线图,可以快速发现异常点;
c)【能力项3:数据应用】
1.能力点:“具备告警风暴管控的能力, 如抑制、收敛等”
疑问:告警收敛能力常用的方式都有哪些呢?
解读:一般在告警收敛中常用的规则有“基于时间收敛”、“基于事件收敛” 和 “基于级别收敛”等,根据不同的业务需求可以有不同的收敛方式。基于时间是最常用的,Nagios 和 Zabbix 的基础配置。基于事件,一般是需要有主动和被动调用关系的告警,比如Zabbix 的 trigger-Dependencies 的功能。基于级别的收敛更是在开源和自研的系统中被使用。
四、结尾
如何看待和提高监控系统的能力,不管是参照开源监控系统对比学习,还是从《研发运营一体化(DevOps)能力成熟度模型》中对比学习,都是一个不错的方向,当然里面的知识点是集合了多数大牛的智慧结晶,本文只是摘取了少量的点进行解读。