













【51CTO.com快译】作为提高企业的运营效率和业务部门竞争力的必备工具,企业知识图谱(Enterprise Knowledge Graphs,EKG)正日益被广泛地运用在协调组织内、外部数据的不同场景中。不过,作为事物的另一面,EKG的弊端则主要体现在:业务部门可能难以对其进行开发、维护、以及扩展。本文介绍了EKG目前尚存在的各种挑战,以及如何使用原生的多模型数据库所提供的灵活的数据表示,来解决这些挑战(请参见图1)。
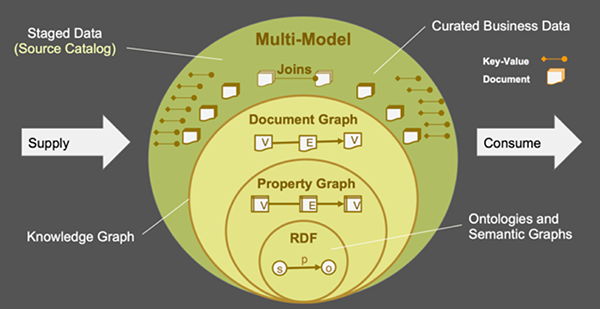
图1:多模型知识图谱能够在一个系统中融合多种数据表示
什么是企业知识图谱?
目前,知识图谱已经为Google、Apple、Facebook、Twitter、MicroSoft、Linkedin、Ebay以及阿里巴巴等公司创造了数万亿美元的财富。它们主要是通过自行研发技术栈(technology stacks)来支持知识图谱。相对于开源的EKG,商业化图形数据库产品的开发,则是根据行业或企业特定的知识模型,来协调组织的内容、数据、以及信息资产。
EKG通常表示某个组织的知识领域,以及那些可被人工和机器理解的组件。它是对本组织的知识资产、内容和数据的参考集合。此类集合利用某种数据模型来描述人员、地点、事物、以及它们之间的关系。
虽然许多企业都部署了各种类型的业务知识图谱(business knowledge graph,BKG)方案,但是并非所有的图谱都能叫做EKG。EKG的主要驱动力源自:为满足特定业务需求而构建定制化的知识图谱。如果说BKG主要旨在支持那些细分的业务用例,那么EKG则旨在向多个业务部门提供高质量的统一数据,以及多种用例。在下一节中,我们将讨论在利用EKG支持业务用例时,所面临的挑战和机遇。
EKG的挑战与机遇
对于业务部门而言,由于EKG包含了来自多个数据源的高净值数据,因此它省去了为支持业务用例而集成数据源所使用的时间和精力。目前许多EKG方案都能够根据企业的概念模型,来协调多个截然不同的异构源系统。这些原始数据通常被暂存在诸如Hadoop/HDFS、S3等分布式的存储系统上,中间件群集会将这些数据提取并转换(Extract Transform Load,ETL)到图形数据库的群集之中。
由于EKG能够支持诸如企业级搜索之类的应用,因此它们需要提取和转换各种格式(如:文档、表格、键值和图形)的EKG数据,以支持业务应用。
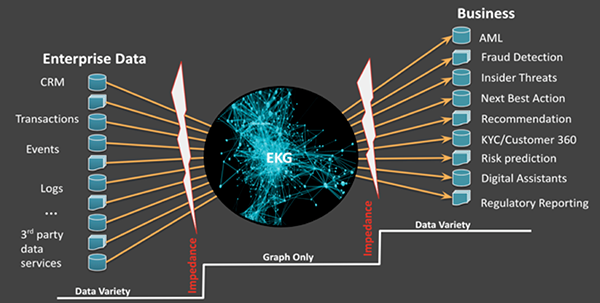
图2:在协调图谱和提供数据时,可能产生不匹配的现象
由于企业往往难以将数据协调成为EKG所需的复杂多源数据,因此EKG常常无法发挥出其全部的潜力。同时,业务用户不但难以应对复杂且生疏的知识图谱表示形式,而且缺乏使用它们的工具。虽然企业可以通过付出巨大的努力,将数十个、乃至数百个数据源整合到一个EKG中,并且解决诸如数据出处、以及权限保留之类的数据治理问题,因此业务部门在充分利用高质量EKG数据过程种,面临着“最后一百米”的巨大挑战。
其实,问题的本质在于,从数据到图形的“全有或全无”转换过程,会导致源数据表示形式与EKG之间、以及EKG与业务部门希望的数据处理方式之间的不匹配(见图2)状况。基于多模型的EKG,通过允许知识图谱中表示形式的多样性,来减少数据的不匹配。据此,图谱将得以灵活地进行增量协调,而业务部门也能够按需对数据进行最少的转换。
多个数据源被协调到图谱中的挑战
企业需要协调好大量不同的数据源。通常情况下,被统一的相关数据源越多,对企业的潜在价值也就越大。当然,将数据协调到图谱的成本,也会随着数据源数量的增加而呈现指数级的增长。这就是为什么企业渴望找到能够对数据进行自动协调,以及通过敏捷应用,来按需提供数据的协调方法。
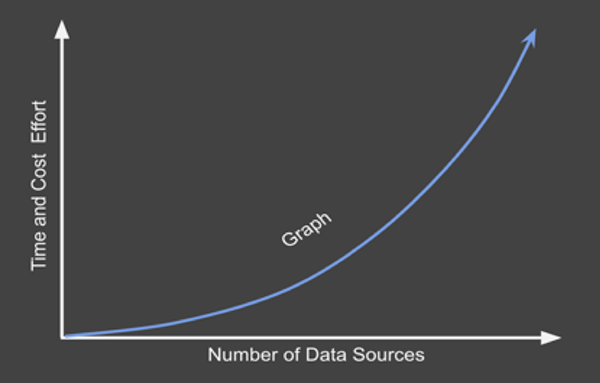
图3:EKG的数据协调工作量会随着数据源数量而呈现出指数级的增长
可见,我们需要通过复杂的知识表示形式,来表示不同数据的细微差别,并标准化图谱结构。供知识图谱使用与联合的所有源数据,都需要被转换成为单模型图形数据库中的图表结构。当然,将源数据映射到这些复杂的知识图谱表示形式是需要时间、精力、以及知识储备的。
如下图4所示,由于需要大量的资源,EKG的生成过程可能会影响到图形数据库的扩展性能。在实际应用中,总会有超过图形数据库扩展能力的海量数据,尤其是存储键值和文档等实际数据的时候。
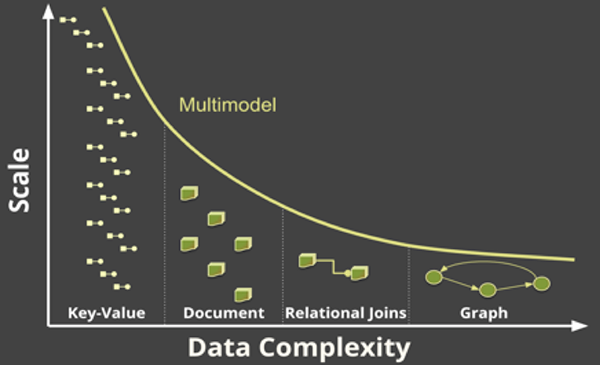
图4:图形处理数据的复杂度与文档、键值的处理能力关系
基于上述原因,多模型数据库恰好能够以按需扩容和简化图形表示的方式,来融合各种键值、文档、联接(join)、以及图形数据模型。例如:当用纯图形表示时,企业内部的网络安全信息会逐年以数万亿条“边(edge)”的速度增长。那么在结合了图形、文档和联接之后,同一个企业网络安全的图谱则可能以数十亿条“边”来表示。
企业在寻找减少开发和维护EKG所需工作量的过程中,往往会扪心自问如下问题:
- 我们可以自动将源数据进行分类、映射和转换为知识图谱吗?
- 在概念模型出现变化时,我们能够自动重构EKG吗?
- 我们能够搜索数据源、知识图谱,进而精选数据吗?
鉴于目前尚无可用于将数据自动协调为图形的实用方案,EKG必须是整体化的图模型,并且所有数据都必须被转换为图才能真正有用。同时,通过允许包含其他类型的数据模型,我们可以减少EKG的部署和维护工作,增加EKG的潜在规模,并且提高EKG开发和维持的灵活性与敏捷性。另外,通过让其他数据模型的知识图谱将分段数据和图形存储在同一数据库中,我们能够以敏捷和迭代的方式进行图形的协调。
让EKG易用的挑战
如前文所述,业务用户难以应对复杂且生疏的知识图谱的表示形式,而且缺乏使用它们的工具。在实际使用中,他们常会碰到如下EKG问题:
- 它能够与我现有的工具一起使用吗?
- 我的开发人员会知道如何使用它吗?
- 我如何能够找到相关的数据?
- 如何绑定所需的数据?
- 如何获得所需的数据格式?
上述挑战的实质源于:在EKG与业务部门需要使用和处理的数据方式之间,存在不匹配的状况。例如:某家企业可能需要2017年1月至2019年12月的所有交易信息,并要求此类数据能够以特定文档结构(如JSON文档集合)的形式提供出来。由于不想额外地学习或使用图形查询语言来达到该目的,因此他们需要一种“数据购物”的体验。即:通过访问EKG商店,并使用多重过滤器在EKG的目录中搜索数据,然后他们根据EKG商店推荐的数据集,来补充现有的数据,并指定获取数据的方式与时间。
多模型企业知识图谱
多模型企业图谱(Multi-model enterprise graphs,MMEKG)可以通过让用户在同一个生态系统中混合和管理数据源、EKG、以及数据的表示形式,以解决前面提到的各种问题。
减少时间和成本
MMEKG能够按需对图进行延迟转换。由于允许在边和顶点中包含不同的文档,因此多模型图谱能够减小图的大小。据此,EKG也可以使用敏捷迭代的过程来进行开发。
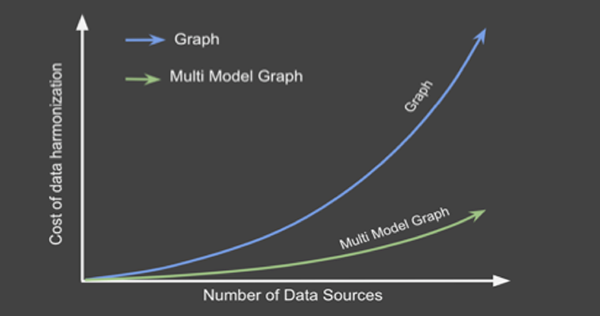
图5:使用多模型图谱能够更有效地协调知识图谱的数据
减少计算资源
如下图6所示,EKG解决方案通常需要使用单独的数据系统,来进行stage、图形ETL、图形管理、以及将数据传递给业务部门使用。MMEKG可以有效地消除源数据、知识图谱、以及精选的业务数据之间存在的不匹配状况。它不但可以在同一个系统中管理数据,而且能够减少转换的延迟,并使得所有的数据都可以被搜索。可见,它降低了使用单独的集群来进行stage,转换,图形化,以及业务应用的相关成本(请参见图7)。
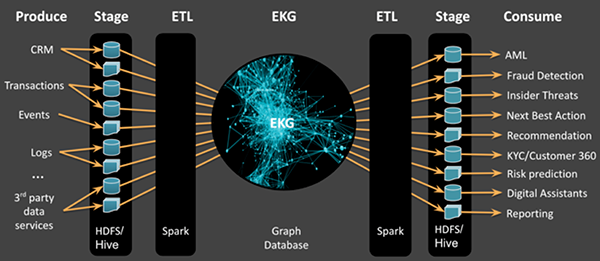
图6:典型的EKG生态系统会使用多个系统来进行stage和转换
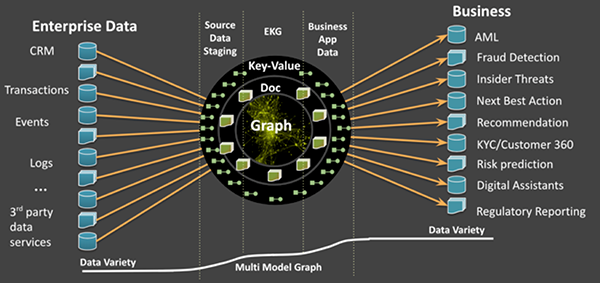
图7:可以在同一多模型数据库中管理源数据、EKG、以及业务数据
使用方便
由于多模型使得源数据、知识图谱和业务应用数据,能够在同一个数据系统中被搜索和找到,因此业务用户可以采用自己的格式去使用数据,而不必了解复杂的企业图谱模型。
数据沿袭(data lineage)
同样由于采用了同一个多模型系统进行数据的stage,转换和交付,因此跟踪数据的沿袭也变得容易了许多。
增强现有的EKG
具有RDF(Resource Description Framework,资源描述框架)类EKG的企业,完全可以保留现有的投入,并在MMEKG中加以利用。因为多模型图是RDF基于带标记的有向图的超集,因此模型数据库可以吸收RDF的本体和RDF的EKG。类似地,多模型图也包含有属性图,因此方便了吸收那些基于属性图的EKG。
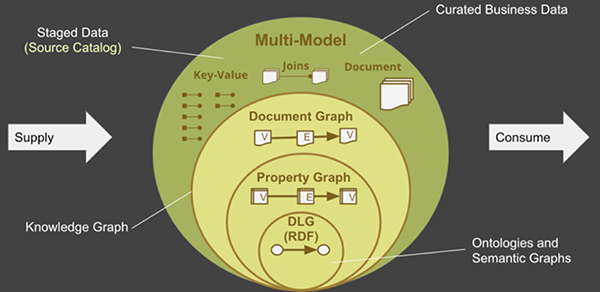
图8:多模型的EKG可以提取RDF,以及基于属性图的EKG
总结
多模型(Multi-model)可谓针对EKG的实用技术,其优势包括让EKG的多源数据更加流畅,提高EKG数据在业务用例中的可用性,通过混合模型实现更高的可扩展性,以及减少EKG生态系统的复杂度。
原文标题:The Multi-Model Knowledge Graph,作者:Arthur Keen & Jan Stuecke
【51CTO译稿,合作站点转载请注明原文译者和出处为51CTO.com】
























