- 你有一个思想,我有一个思想,我们交换后,一个人就有两个思想
- If you can NOT explain it simply, you do NOT understand it well enough
现陆续将Demo代码和技术文章整理在一起 Github实践精选 ,方便大家阅读查看,本文同样收录在此,觉得不错,还请Star

之前写了几篇 Java并发编程的系列 文章,有个朋友微群里问我,还是不能理解 volatile 和 synchronized 二者的区别, 他的问题主要可以归纳为这几个:
- volatile 与 synchronized 在处理哪些问题是相对等价的?
- 为什么说 volatile 是 synchronized 弱同步的方式?
- volatile 除了可见性问题,还能解决什么问题?
- 二者我要如何选择使用?
如果你不能回答上面的几个问题,说明你对二者的区别还有一些含混。本文就通过图文的方式好好说说他们微妙的关系
都听过【天上一天,地下一年】,假设 CPU 执行一条普通指令需要一天,那么 CPU 读写内存就得等待一年的时间。
受【木桶原理】的限制,在CPU眼里,程序的整体性能都被内存的办事效率拉低了,为了解决这个短板,硬件同学也使用了我们做软件常用的提速策略——使用缓存Cache(实则是硬件同学给软件同学挖的坑)
Java 内存模型(JMM)
CPU 增加了缓存均衡了与内存的速度差异,这一增加还是好几层。
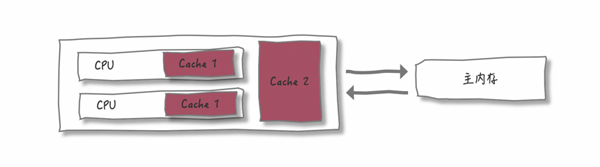
此时内存的短板不再那么明显,CPU甚喜。但随之却带来很多问题
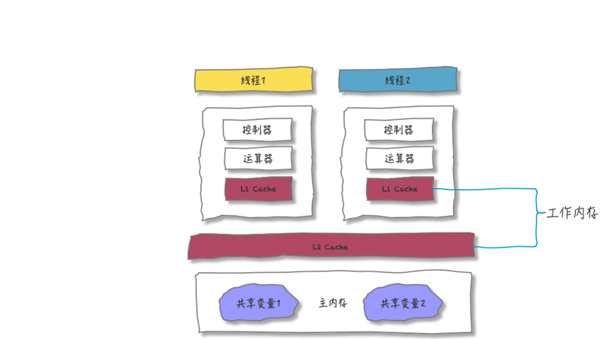
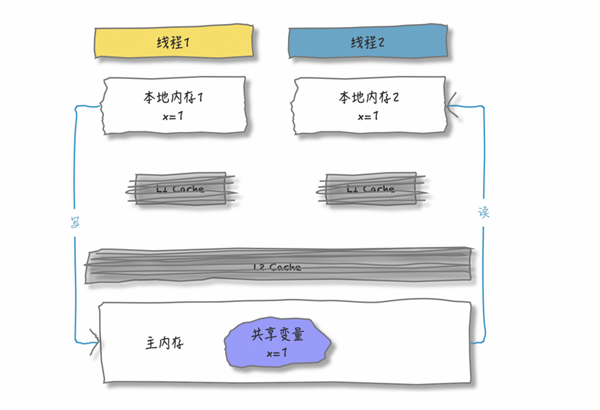
看上图,每个核都有自己的一级缓存(L1 Cache),有的架构里面还有所有核共用的二级缓存(L2 Cache)。使用缓存之后,当线程要访问共享变量时,如果 L1 中存在该共享变量,就不会再逐级访问直至主内存了。所以,通过这种方式,就补上了访问内存慢的短板
具体来说,线程读/写共享变量的步骤是这样:
- 从主内存复制共享变量到自己的工作内存
- 在工作内存中对变量进行处理
- 处理完后,将变量值更新回主内存
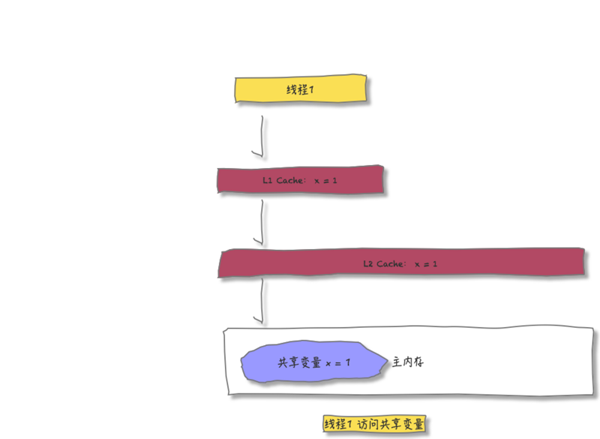
假设现在主内存中有共享变量 X, 其初始值为 0
线程1先访问变量 X, 套用上面的步骤就是这样:
- L1 和 L2 中都没有发现变量 X,直到在主内存中找到
- 拷贝变量 X 到 L1 和 L2 中
- 在 L1 中将 X 的值修改为1,并逐层写回到主内存中
此时,在线程 1 眼中,X 的值是这样的:
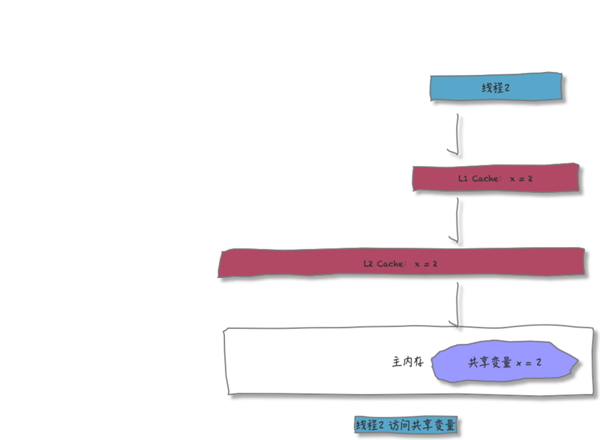
接下来,线程 2 同样按照上面的步骤访问变量 X
- L1 中没有发现变量 X
- L2 中发现了变量X
- 从L2中拷贝变量到L1中
在L1中将X 的值修改为2,并逐层写回到主内存中
此时,线程 2 眼中,X 的值是这样的:
结合刚刚的两次操作,当线程1再访问变量x,我们看看有什么问题:
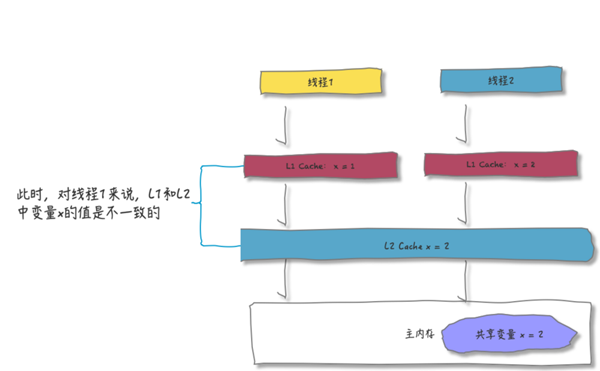
此刻,如果线程 1 再次将 x=1回写,就会覆盖线程2 x=2 的结果,同样的共享变量,线程拿到的结果却不一样(线程1眼中x=1;线程2眼中x=2),这就是共享变量内存不可见的问题。
怎么补坑呢?今天的两位主角闪亮登场,不过在说明 volatile关键字之前,我们先来说说你最熟悉的 synchronized 关键字
synchronized
遇到线程不安全的问题,习惯性的会想到用 synchronized 关键字来解决问题,暂且先不论该办法是否合理,我们来看 synchronized 关键字是怎么解决上面提到的共享变量内存可见性问题的
- 【进入】synchronized 块的内存语义是把在 synchronized 块内使用的变量从线程的工作内存中清除,从主内存中读取
- 【退出】synchronized 块的内存语义事把在 synchronized 块内对共享变量的修改刷新到主内存中
二话不说,无情向下看 volatile
volatile
当一个变量被声明为 volatile 时:
- 线程在【读取】共享变量时,会先清空本地内存变量值,再从主内存获取最新值
- 线程在【写入】共享变量时,不会把值缓存在寄存器或其他地方(就是刚刚说的所谓的「工作内存」),而是会把值刷新回主内存
有种换汤不换药的感觉,你看的一点都没错
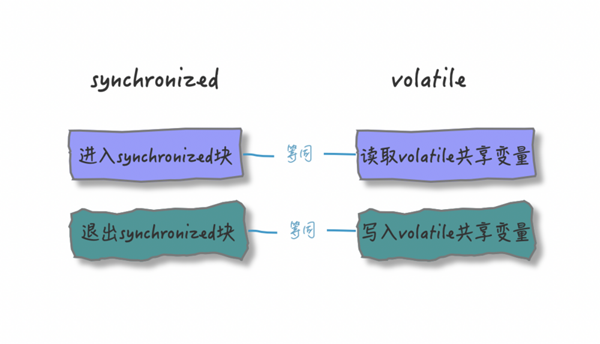
所以,当使用 synchronized 或 volatile 后,多线程操作共享变量的步骤就变成了这样:
简单点来说就是不再参考 L1 和 L2 中共享变量的值,而是直接访问主内存
来点踏实的,上例子
- public class ThreadNotSafeInteger {
- /**
- * 共享变量 value
- */
- private int value;
- public int getValue() {
- return value;
- }
- public void setValue(int value) {
- this.value = value;
- }
- }
经过前序分析铺垫,很明显,上面代码中,共享变量 value 存在大大的隐患,尝试对其作出一些改变
先使用 volatile 关键字改造:
- public class ThreadSafeInteger {
- /**
- * 共享变量 value
- */
- private volatile int value;
- public int getValue() {
- return value;
- }
- public void setValue(int value) {
- this.value = value;
- }
- }
再使用 synchronized 关键字改造
- public class ThreadSafeInteger {
- /**
- * 共享变量 value
- */
- private int value;
- public synchronized int getValue() {
- return value;
- }
- public synchronized void setValue(int value) {
- this.value = value;
- }
- }
这两个结果是完全相同,在解决【当前】共享变量数据可见性的问题上,二者算是等同的
如果说 synchronized 和 volatile 是完全等同的,那就没必要设计两个关键字了,继续看个例子
- @Slf4j
- public class VisibilityIssue {
- private static final int TOTAL = 10000;
- // 即便像下面这样加了 volatile 关键字修饰不会解决问题,因为并没有解决原子性问题
- private volatile int count;
- public static void main(String[] args) {
- VisibilityIssue visibilityIssue = new VisibilityIssue();
- Thread thread1 = new Thread(() -> visibilityIssue.add10KCount());
- Thread thread2 = new Thread(() -> visibilityIssue.add10KCount());
- thread1.start();
- thread2.start();
- try {
- thread1.join();
- thread2.join();
- } catch (InterruptedException e) {
- log.error(e.getMessage());
- }
- log.info("count 值为:{}", visibilityIssue.count);
- }
- private void add10KCount(){
- int start = 0;
- while (start ++ < TOTAL){
- this.count ++;
- }
- }
- }
其实就是将上面setValue 简单赋值操作 (this.value = value;)变成了 (this.count ++;)形式,如果你运行代码,你会发现,count的值始终是处于1w和2w之间的
将上面方法再以 synchronized 的形式做改动
- @Slf4j
- public class VisibilityIssue {
- private static final int TOTAL = 10000;
- private int count;
- //... 同上
- private synchronized void add10KCount(){
- int start = 0;
- while (start ++ < TOTAL){
- this.count ++;
- }
- }
- }
再次运行代码,count 结果就是 2w
两组代码,都通过 volatile 和 synchronized 关键字以同样形式修饰,怎么有的可以带来相同结果,有的却不能呢?
这就要说说二者的不同了
count++ 程序代码是一行,但是翻译成 CPU 指令确是三行( 不信你用 javap -c 命令试试)
synchronized 是独占锁/排他锁(就是有你没我的意思),同时只能有一个线程调用 add10KCount 方法,其他调用线程会被阻塞。所以三行 CPU 指令都是同一个线程执行完之后别的线程才能继续执行,这就是通常说说的 原子性 (线程执行多条指令不被中断)
但 volatile 是非阻塞算法(也就是不排他),当遇到三行 CPU 指令自然就不能保证别的线程不插足了,这就是通常所说的,volatile 能保证内存可见性,但是不能保证原子性
一句话,那什么时候才能用volatile关键字呢?(千万记住了,重要事情说三遍,感觉这句话过时了)
如果写入变量值不依赖变量当前值,那么就可以用 volatile
如果写入变量值不依赖变量当前值,那么就可以用 volatile
如果写入变量值不依赖变量当前值,那么就可以用 volatile
比如上面 count++ ,是获取-计算-写入三步操作,也就是依赖当前值的,所以不能靠volatile 解决问题
到这里,文章开头第一个问题【volatile 与 synchronized 在处理哪些问题是相对等价的?】答案已经揭晓了
先自己脑补一下,如果让你同一段时间内【写几行代码】就要去【数钱】,数几下钱就要去【唱歌】,唱完歌又要去【写代码】,反复频繁这样操作,还要接上上一次的操作(代码接着写,钱累加着数,歌接着唱)还需要保证不出错,你累不累?
synchronized 是排他的,线程排队就要有切换,这个切换就好比上面的例子,要完成切换,还得记准线程上一次的操作,很累CPU大脑,这就是通常说的上下文切换会带来很大开销
volatile 就不一样了,它是非阻塞的方式,所以在解决共享变量可见性问题的时候,volatile 就是 synchronized 的弱同步体现了
到这,文章的第二个问题【为什么说 volatile 是 synchronized 弱同步的方式?】你也应该明白了吧
volatile 除了还能解决可见性问题,还能解决编译优化重排序问题,之前的文章已经介绍过,请大家点击链接自行查看就好(面试常问的双重检查锁单例模式为什么不是线程安全的也可以在里面找到答案哦):
看完这两篇文章,相信第三个问题也就迎刃而解了
了解了这些,相信你也就懂得如何使用了
精挑细选,终于整理完初版 Java 技术栈硬核资料,抢先看就私信回复【资料】/【666】吧
灵魂追问
- 你了解线程的生命周期吗?不同的状态流转是什么样的?
- 为什么线程有通知唤醒机制?
下一篇文章,我们来说说【唤醒线程为什么建议用notifyAll而不建议用notify呢?】
欢迎关注我的公众号 「日拱一兵」,趣味原创解析Java技术栈问题,将复杂问题简单化,将抽象问题图形化落地
如果对我的专题内容感兴趣,或抢先看更多内容,欢迎访问我的博客 dayarch.top